大数据之路——数据同步(第三章)
文章目录
- 3.1 数据同步基础
-
- 3.1.1 直连同步
- 3.1.2 数据文件同步
- 3.1.3 数据库日志解析同步
如第一章所述,我们将数据采集分为日志采集和数据库数据同步两部分。数据同步技术更通用的含义是不同系统间的数据流转,有多种不同的应用场景。主数据库与备份数据库之间的数据备份,以及主系统与子系统之间的数据更新,属于同类型不同集群数据库之间的数据同步。另外,还有不同地域、不同数据库类型之间的数据传输交换,比如分布式业务系统与数据仓库系统之间的数据同步。对于大数据系统来说,包含数据从业务系统同步进入数据仓库和数据从数据仓库同步进入数据服务或数据应用两个方面。本章侧重讲解数据从业务系统同步进入数据仓库这个环节,但其适用性并不仅限于此。
3.1 数据同步基础
源业务系统的数据类型多种多样,有来源于关系型数据库的结构化数据,如 MySQL Orac le DB2, SQL Server :也有来源于非关系型数据库的非结构化数据,如 Ocean Base HBase Mongo DB 等,这类数据通常存储在数据库表中:还有来源于文件系统的结构化或非结构化数据,如阿里云对象存储 oss 、文件存储 NAS 等,这类数据通常以文件形式进行存储。数据同步需要针对不同的数据类型及业务场景选择不同的同步方式。总的来说,同步方式可以分为三种 直连同步 、数据文件同步和数据库日志解析同步。
3.1.1 直连同步
直连同步是指通过定义好的规范接口 API 和基于动态链接库的方式直接连接业务库,如 BC/JD BC 等规定了统一规范的标准接口,不同的数据库基于这套标准接口提供规范的驱动,支持完全相同的函数调用和 SQL 实现(见图 .1 )。
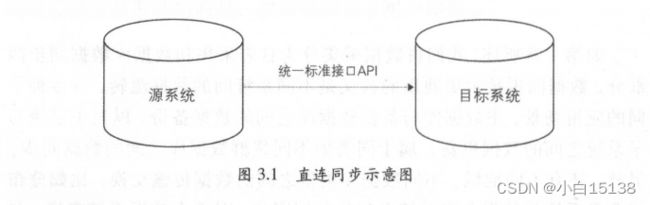
这种方式配置简单,实现容易,比较适合操作型业务系统的数据同步。但是业务库直连的方式对源系统的性能影响较大,当执行大批量数据同步时会降低甚至拖垮业务系统的性能。如果业务库采取主备策略,则可以从备库抽取数据,避免对业务系统产生性能影响。但是当数据量
较大时,采取此种抽取方式性能较差,不太适合从业务系统到数据仓库系统的同步。
3.1.2 数据文件同步
数据文件同步通过约定好的文件编码、大小、格式等,直接从源系统生成数据的文本文件,由专门的文件服务器,如 FTP 服务器传输到目标系统后,加载到目标数据库系统中。当数据源包含多个异构的数据库系统(如 MyS QL Oracle QL Server DB2 等)时,用这种方式比较简单、实用。另外,互联网的日志类数据,通常是以文本文件形式存在的,也适合使用数据文件同步方式(见图 3.2)
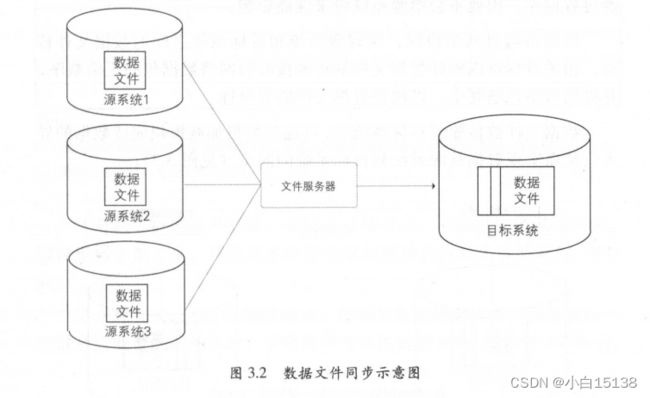
由于通过文件服务器上传、下载可能会造成丢包或错误,为了确保数据文件同步的完整性,通常除了上传数据文件本身以外,还会上传一个校验文件,该校验文件记录了数据文件的数据量以及文件大小等校验信息,以供下游目标系统验证数据同步的准确性。
另外,在从源系统生成数据文件的过程中,可以增加压缩和加密功能,传输到目标系统以后,再对数据进行解压缩和解密 这样可以大大提高文件的传输效率和安全性。
3.1.3 数据库日志解析同步
目前,大多数主流数据库都已经实现了使用日志文件进行系统恢复,因为日 文件信息足够丰富,而且数据格式也很稳定,完全可以通过解析日志文件获取发生变更的数据,从而满足增量数据同步的需求。
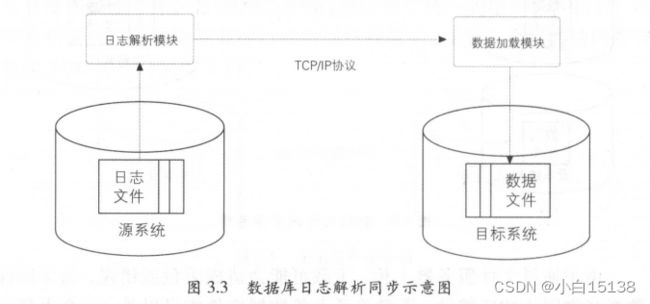
以Oracle 为例,可以通过源系统的进程,读取归档日志文件用以收集变化的数据信息,并判断日志中的变更是否属于被收集对象,将其解析到目标数据文件中。这种读操作是在操作系统层面完成的,不需要通过数据库,因此不会给源系统带来性能影响。
然后可通过网络协议,实现源系统和目标系统之间的数据文件传输。相关进程可以确保数据文件的正确接收和网络数据包的正确顺序,并提供网络传输冗余,以确保数据文件的完整性。
数据文件被传输到目标系统后,可通过数据加载模块完成数据的导人,从而实现数据从源系统到目标系统的同步(见图 3.3 )。
数据库日志解析同步方式实现了实时与准实时同步的能力,延迟可以控制在毫秒级别,并且对业务系统的性能影响也比较小,目前广泛应用于从业务系统到数据仓库系统的增量数据同步应用之中。
由于数据库日志抽取 般是获取所有的数据记录的变更(增、删、改),落地到目标表时我们需要根据主键去重按照日志时间倒排序获取最后状态的变化情况。对于删除数据这种变更情况,针对不同的业务场景可以采用一些不同的落地手法。
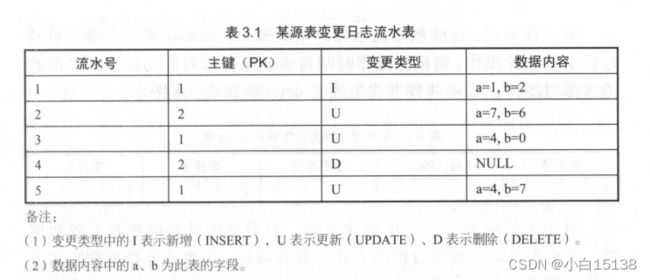
我们以具体的实例进行说明。如表 3.1 所示为源业务系统中某表变更日志流水表。其含义是:存在 条变更日志,其中主键为 的记录有3条变更日志,主键为 的记录有 条变更日志。
针对删除数据这种变更,主要有三种方式,下面以实例 行说明。假设根据主键去重,按照流水倒序获取记录最后状态生成的表为 delta表。
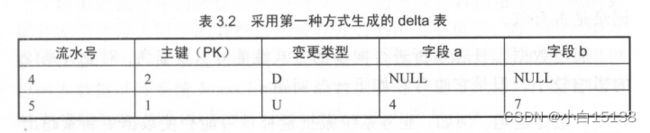
第一种方式,不过滤删除流水。不管是否是删除操作, 都获取同一主键最后变更的那条流水。采用此种方式生成的delta表如表3.2所示。
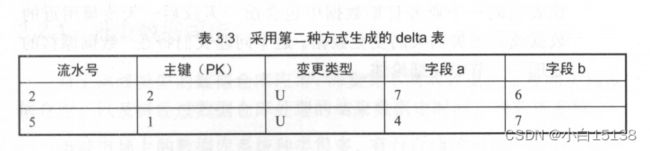
第二种方式,过滤最后一条删除流水,如果同一主键最后变更的那条流水是删除操作,就获取倒数第二条流水。采用此种方式生成 delta表如表3.3所示。
第三种方式,过滤删除流水和之前的流水。如果在同一主键变更的过程中有删除操作,则根据操作时间将该删除操作对应的流水和之前的
流水都过滤掉。采用 此种方式生成的 delta 表如表 3.4 所示。

对于采用哪种方式处理删除数据,要看前端是如何删除无效数据的。前端业务系统删除数据的方式一般有两种 :正常业务数据删除和手工批量删除。手工批量删除通常针对类似的场景,业务系统只做逻辑删除,不做物理删除, OBA 定期将部分历史数据直接删除或者备份到备份库。
一般情况下,可以采用不过滤的方式来处理,下游通过是否删除记录的标识来判断记录是否有效。如果明确业务数据不存在业务上的删除,但是存在批量手工删除或备份数据删除,例如淘宝商品、会员等,则可以采用只过滤最后一条删除流水的方式,通过状态字段来标识删除
记录是否有效。
通过数据库日志解析进行同步的方式性能好、效率高,对业务系统的影响较小。但是它也存在如下一些问题:
·
- 数据延迟。例如,业务系统做批量补录可能会使数据更新量超出系统处理峰值,导致数据延迟。
- 投人较大。采用数据库日 抽取的方式投入较大,需要在源数据库与目标数据库之间部署 个系统实时抽取数据。
- 数据漂移和遗漏。数据漂移, 般是对增量表而言的,通常是指该表的同一个业务日期数据中包含前一天或后一天凌晨 附近的数据或者丢失当天的变更数据。这个问题我们将在“数据漂移的处理”一节中详细论述。