MySQL进阶第八章
八.日志系统
| 日志类型 | 写入日志的信息 |
|---|---|
| 二进制日志 | 记录了对MySQL数据库执行更改的所有操作 |
| 慢查询日志 | 记录所有执行时间超过 long_query_time 秒的所有查询或不使用索引的查询 |
| 错误日志 | 记录在启动,运行或停止mysqld时遇到的问题 |
| 通用查询日志 | 记录建立的客户端连接和执行的语句 |
| 中继日志 | 从复制主服务器接收的数据更改 |
1.bin log日志
1.概述
binlog日志是二进制日志(binnary log),以时间形式记录了对MySQL数据库修改的所有操作。
binlog只记录数据库的增删改的操作,查看数据的操作不记录,因为这类操作没有对数据库进行修改的操作。
binlog是mysql server层维护的,跟使用什么引擎没有关系,binlog实在事务最终commit之前写入的。
binlog有两个常用的使用场景:
- 主从复制:我们会专门有一个章节代领大家搭建一个主从同步的两台mysql服务。
- 数据恢复:通过mysqlbinlog工具来恢复数据。
mysql8中的binLog默认是开启的,5.7默认是关闭的,可以通过参数log_bin控制。
2.数据恢复
(1).确认binlog开启
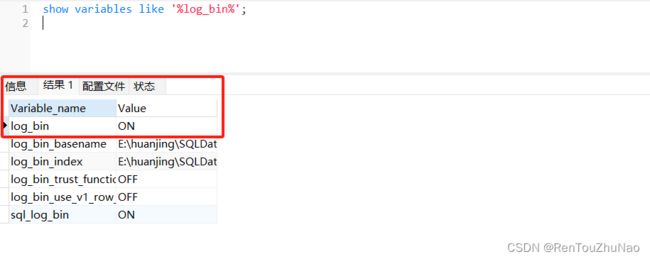
(2).刷新日志以防旧的日志产生影响。
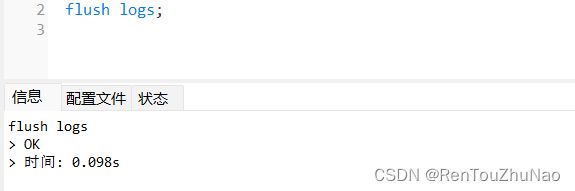
(3)查看所有binlog日志列表:
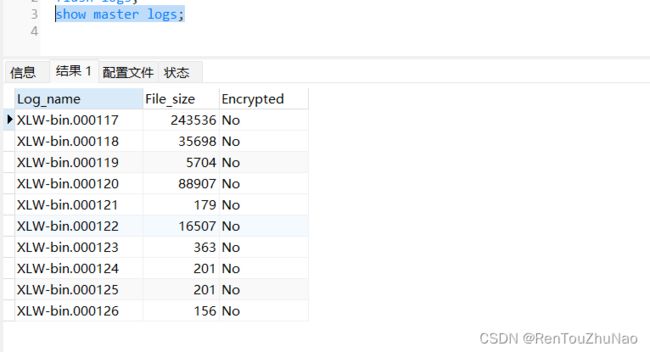
(4).当我们误删数据库的数据之后,就可以使用mysqlbinlog工具来进行数据恢复,首先需要我们查看binlog的日志文件,因为binlog的日志文件是二进制文件,只能使用mysqlbinlog来查看,查看日志查找到误删操作的位置,执行恢复操作,语句如下:1111为误删操作之前的位置。
/www/server/mysql/bin/mysqlbinlog -v XLW-bin.000126 --stop-position=1111 -v | mysql -uroot -p
*注意当执行恢复操作的时候,会执行这个数据库的一开始的全部操作,如果数据库已经存在,会提示我们数据库已经存在,当然我们也可以指定范围来恢复数据。
# 指定位置范围
/usr/bin/mysqlbinlog -v XLW-bin.000126 --start-position=0 --stop-position=986
# 指定时间范围
/usr/bin/mysqlbinlog -v XLW-bin.000126 --start-datetime="2023-12-22 11:18:00" --stop-datetime="2023-12-22 12:18:00"
3.格式分类
binlog 有三种格式, 使用变量binlog_format查看当前使用的是哪一种:
- Statement(Statement-Based Replication,SBR):每一条会修改数据的 SQL 都会记录在 binlog 中。
- Row(Row-Based Replication,RBR):不记录 SQL 语句上下文信息,仅保存哪条记录被修改。
- Mixed(Mixed-Based Replication,MBR):Statement 和 Row 的混合体,当前默认的选项,5.7中默认row。

Statement和Row的优劣比较:
- Statement 模式只记录执行的 SQL,不需要记录每一行数据的变化,因此极大的减少了 binlog 的日志量,避免了大量的 IO 操作,提升了系统的性能。
- 由于 Statement 模式只记录 SQL,而如果一些 SQL 中 包含了函数,那么可能会出现执行结果不一致的情况。比如说 uuid() 函数,每次执行的时候都会生成一个随机字符串,在 master 中记录了 uuid,当同步到 slave 之后,再次执行,就得到另外一个结果了。所以使用 Statement 格式会出现一些数据一致性问题。
- 从 MySQL5.1.5 版本开始,binlog 引入了 Row 格式,Row 格式不记录 SQL 语句上下文相关信息,仅仅只需要记录某一条记录被修改成什么样子了。
- 不过 Row 格式也有一个很大的问题,那就是日志量太大了,特别是批量 update、整表 delete、alter 表等操作,由于要记录每一行数据的变化,此时会产生大量的日志,大量的日志也会带来 IO 性能问题。
4.日志格式
- binlog文件以一个值为0Xfe62696e的魔数开头,这个魔数对应0xfebin。
- binlog由一系列的binlog event构成。每个binlog event包含header和data两部分。
- header部分提供的是event的公共的类型信息,包括event的创建时间,服务器等等。
- data部分提供的是针对该event的具体信息,如具体数据的修改。
常见的事件类型有:
- FORMAT_DESCRIPTION_EVENT:该部分位于整个文件的头部,每个binlog文件都必定会有唯一一个该event
- WRITE_ROW_EVENT:插入操作。
- DELETE_ROW_EVENT:删除操作。
- UPDATE_ROW_EVENT:更新操作。记载的是一条记录的完整的变化情况,即从前量变为后量的过程
- ROTATE_EVENT:Binlog结束时的事件,用于说明下一个binlog文件。
5.binlog刷盘
二进制日志文件并不是每次写的时候同步到磁盘。因此当数据库所在操作系统发生宕机时,可能会有最后一部分数据没有写入二进制日志文件中,这给恢复和复制带来了问题。 参数sync_binlog=[N]表示每写多少次就同步到磁盘。如果将N设为1,即sync_binlog=1表示采用同步写磁盘的方式来写二进制日志,这时写操作不使用操作系统的缓冲来写二进制日志。(备注:该值默认为0,采用操作系统机制进行缓冲数据同步)。
6.binlog实现主从同步
略
2.其他日志
1.通用查询日志,默认关闭
MySQL通用查询日志,它是记录建立的客户端连接和执行的所有DDL和DML语句(不管是成功语句还是执行有错误的语句),默认情况下,它是不开启的。请注意,它也是一个文本文件。
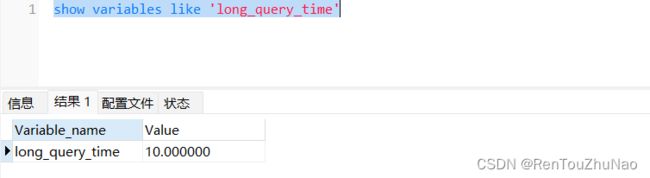
2.慢查询日志
慢查询日志就是记录我们执行sql语句时,那些比较慢的数据,也就是超过我们设定的查询时间的sql语句,通过以下语句可以查看设定的时间:
3.错误日志
错误日志(Error Log)主要记录 MySQL 服务器启动和停止过程中的信息、服务器在运行过程中发生的故障和异常情况等。即使是MySQL服务器启动失败,该日志也会记录错误原因。
3.redo log日志
redo log(重做日志)的设计主要是为了防止因系统崩溃而导致的数据丢失,其实解决因系统崩溃导致数据丢失的思路如下:
1、每次提交事务之前,必须将所有和当前事务相关的【buffer pool中的脏页】刷入磁盘,但是,这个效率比较低,可能会影响主线程的效率,产生用户等待,降低响应速度,因为刷盘是I/O操作,同时一个事务的读写操作也不是顺序读写。
2、把当前事务中修改的数据内容在日志中记录下来,日志记录是顺序写,性能很高。其实mysql就是这么做的,这个日志被称为redo log。执行事务中,每执行一条语句,就可能有若干redo日志,并按产生的顺序写入磁盘,redo日志占用的空间非常小,当redo log空间满了之后又会从头开始以循环的方式进行覆盖式的写入。
redo log的格式比较简单,包含一下几个部分:
-
type:该日志的类型,在5.7版本中,大概有53种不同类型的redo log,占用一个字节
-
space id:表空间id
-
page number:页号
-
data:日志数据
1.MTR
在innodb执行任务时,有很多操作,必须具有原子性,我们把这一类操作称之为MIni Transaction。
在我们向B+树中插入一条记录的时候,需要定位这条数据将要插入的【数据页】,因为插入的位置不同,可能会有以下情况:
1、待插入的页拥有【充足的剩余空间】,足以容纳这条数据,那就直接插入就好了,这种情况需要记录一条【MLOG_COMP_REC_INSERT类型】的redo日志就好了,这种情况成为乐观插入。
2、待插入的页【剩余空间不足】以容纳该条记录,这样就比较麻烦了,必须进行【页分裂】了。必须新建一个页面,将原始页面的数据拷贝一部分到新页面,然后插入数据。这其中对应了好几个操作,必须记录多条rede log,包括申请新的数据页、修改段、区的信息、修改各种链表信息等操作,需要记录的redo log可能就有二三十条,但是本次操作必须是一个【原子性操作】,在记录的过程中,要全部记录,要么全部失败,这种情况就被称之为一个MIni Transaction(最小事务)。
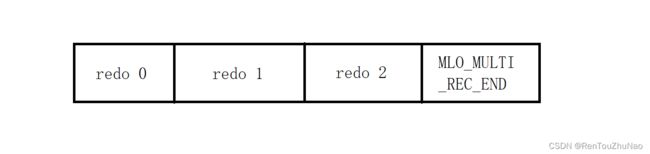
(1).MTR的按组写入
对于一个【MTR】操作必须是原子的,为了保证原子性,innodb使用了组的形式来记录redo 日志,在恢复时,要么这一组的的日志全部恢复,要么一条也不恢复。innodb使用一条类型为MLO_MULTI_REC_END类型的redo log作为组的结尾标志,在系统崩溃恢复时只有解析到该项日志,才认为解析到了一组完整的redo log,否则直接放弃前边解析的日志。
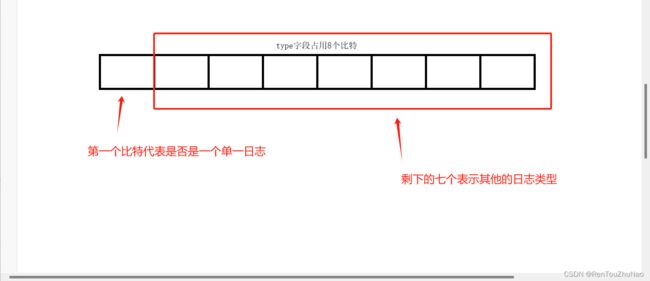
(2).单条redolog的标识方法
有些操作只会产生一条redo log,innodb是通过【类型标识】的第一个字符来判断,这个日志是单一日志还是组日志,如下图:
(3).事务、sql、MTR、redolog的关系如下
- 一个事务包含一条或多条sql
- 一条sql包含一个或多个MTR
- 一个MTR包含一个或多个redo log
2.log buffer
任何可能产生大量I/O的操作,一般情况下都会设计【缓冲层】,mysql启动时也会向操作系统申请一片空间作为redo log的【缓冲区】,innodb使用一个变量buf_free来标记下一条redo log的插入位置(标记偏移量),log buffer会在合适的时机进行刷盘:
- log buffer空间不足。logbuffer的容量由
innodb_log_buffer_size指定,当写入log buffer的日志大于容量的50%,就会进行刷盘。 - 提交事务时,如果需要实现崩溃恢复,保证数据的持久性,提交事务时必须提交redo log,当然你也可以为了效率不去提交,可以通过修改配置文件设置该项目。
- 后台有独立线程大约每隔一秒会刷新盘一次。
- 正常关闭服务器。
- 做checkpoint时。
3.checkpoint
redolog日志文件容量是有限的,需要循环使用,redo log的作用仅仅是为了在崩溃时恢复脏页数据使用的,如果脏页已经刷到磁盘上,其对应的redo log也就没用了,他也就可以被重复利用了。checkpoint的作用就是用来标记哪些旧的redo log可以被覆盖。
我们已经知道,判断redo log占用的磁盘空间是否可以被重新利用的标志就是,对应的脏页有没有被刷新到磁盘。为了实现这个目的,我们需要了解一下下边几个记录值的作用:
(1)lsn
lsn(log sequence number)是一个全局变量。mysql在运行期间,会不断的产生redo log,日志的量会不断增加,innodb使用lsn来记录当前总计写入的日志量,lsn的初始值不是0,而是8704,原因未知。系统在记录lsn时是按照【偏移量】不断累加的。lsn的值越小说明redo log产生的越早。
每一组redo log都有一个唯一的lsn值和他对应,可以理解为lsn是redo log的年龄。
(2)flush_to_disk_lsn
flush_to_disk_lsn也是一个全局变量,表示已经刷入磁盘的redo log的量,他小于等于lsn,举个例子:
1、将redo log写入log buffer,lsn增加,假如:8704+1024 = 9728,此时flush_to_disk_lsn不变。
2、刷如512字节到磁盘,此时flush_to_disk_lsn=8704+512=9256。
如果两者数据相同,说明已经全部刷盘。
(3)flush链中的lsn
其实要保证数据不丢失,核心的工作是要将buffer pool中的脏页进行刷盘,但是刷盘工作比较损耗性能,需要独立的线程在后台静默操作。
回顾一下flush链,当第一次修改某个已经加载到buffer pool中的页面时,他会变成【脏页】,会把他放置在flush链表的头部,flush链表是按照第一次修改的时间排序的。在第一次修改缓冲页时,会在【缓冲页对应的控制块】中,记录以下两个属性:
- oldest_modification:第一次修改缓冲页时,就将【修改该页面的第一组redo log的lsn值】记录在对应的控制块。
- newest_modification:每一次修改缓冲页时,就将【修改该页面的最后组redo log的lsn值】记录在对应的控制块。
既然flush链表是按照修改日期排序的,那么也就意味着,oldest_modification的值也是有序的。
(4)checkpoint过程
执行一个check point可以分为两个步骤
**第一步:**计算当前redo log文件中可以被覆盖的redo日志对应的lsn的值是多少:
1、flush链是按照第一次修改的时间排序的,当然控制块内的【oldest_modification】记录的lsn值也是有序的。
2、我们找到flush链表的头节点上的【oldest_modification】所记录的lsn值,也就找到了一个可以刷盘的最大的lsn值,小于这个值的脏页,肯定已经刷入磁盘。
3、所有小于这个lsn值的redo log,都可以被覆盖重用。
4、将这个lsn值赋值给一个全局变量checkpoint_lsn,他代表可以被覆盖的量。
**第二步:**将checkpoint_lsn与对应的redo log日志文件组偏移量以及此次checkpoint的编号(checkpoint_no也是一个变量,记录了checkpoint的次数)全部记录在日志文件的管理信息内。
4.系统崩溃的影响
(1)log buffer中的日志丢失,log buffer中的日志会在每次事务前进行刷盘,如果在事务进行中崩溃,事务本来就需要回滚。
(2)buffer pool中的脏页丢失,崩溃后可以通过redo log恢复,通过checkpoint操作,我们可以确保,内存中脏页对应的记录都会在redo log日志中存在。
redo log保证了崩溃后,数据不丢失,但是一个事务进行中,如果一部分redo log已经刷盘,那么系统会将本应回滚的数据同样恢复,为了解决回滚的问题,innodb提出了undo log。
4.undo log日志
1.概述
undo log(也叫撤销日志或者回滚日志),他的主要作用是为了实现回滚操作。同时,他是MVCC多版本控制的核心模块。undo log保存在共享表空间【ibdata1文件】中。
*8.0以后undolog有了独立的表空间
2.事务id(trx_id)
在innodb的行数据中,会自动添加两个隐藏列,一个是【trx_id】,一个是【roll_pointer】,如果该表中没有定义主键,也没有定义【非空唯一】列,则还会生成一个隐藏列【row_id】,是为了生成聚簇索引使用的。
小知识:
- 事务id保存在一个全局变量【MAX_TRX_ID】上,每次事务需要分配事务id,就会从这个全局变量中获取,然后自增1。
- 该变量每次自增到256的倍数会进行一个落盘(保存在表空间页号为5的页面中),发生服务停止或者系统崩溃后,再起启动服务,会读取这个数字,然后再加256。这样做既保证不会有太多I/O操作,还能保证id的有序增长。比如:读到256进行落盘,后来又涨到302,突然崩溃了,下次启动后,第一个事务的id就是256+256=512,保证新的事务id一定大。
3.roll_pointer
undo log在记录日志时是这样记录的,每次修改数据,都会将修改的数据标记一个【新的版本】,同时,这个版本的数据的地址会保存在修改之前的数据的roll_pointer列中。
4.分类
当我们对数据库的数据进行一个操作时必须记录之前的信息,将来才能回滚,如下:
- 插入一条数据时,至少要把这条数据的主键记录下来,以后不想要了直接根据主键删除。
- 删除一条数据时,至少要把这个数据所有的内容全部记录下来,以后才能全量恢复。但事实上不需要,每行数据都有一个delete_flag,事务中将其置1,记录id,如需要回滚根据id复原即可,提交事务后又purge线程处理垃圾。
- 修改一条数据时,至少要将修改前后的数据都保存下来。
innodb将undo log分为两类:
- 一类日志只记录插入类型的操作(insert)
- 一类日志只记录修改类型的操作(delete,update)
什么分为这两类呢?
- 插入型的记录不需要记录版本,事务提交以后这一片空间就可以重复利用了。
- 修改型的必须将每次修改作为一个版本记录下来,即使当前事务已经提交,也不一定能回收空间,应为其他事务可能在用。
5.物理存储结构
undo同样是以页的形式进行存储的,多个页是使用链表的形式进行管理,针对【普通表和临时表】,【插入型和修改型】的数据。
6.记录流程
-
开启事务,执行【增删改】时获得【事务id】。
-
在系统表空间中第5号页中,分配一个回滚段,回滚段是轮动分配的,比如,当前事务使用第5个回滚段,下个事务就使用第6个。
【回滚段】是一个【数据页】,里边划分了1024个undo slot,用来存储日志链表的头节点地址。
-
在当前回滚段的cached链表(回收可复用的)和空闲solt中,找到一个可用的slot,找不到就报错。
-
创建或复用一个undo log页,作为first undo page,并把他的地址写入undo solt中。
7.回滚过程
- 服务再次启动时,通过表空间5号页面定位到128个回滚段的位置,
- 遍历所有的slot,找到所有状态不为空闲的slot,并且通过undolog的标记为找到现在活跃(未提交)的所有的事务id
- 根据undo log的记录,将数据全部回滚