强化学习12——策略梯度算法学习
Q-learning、DQN算法是基于价值的算法,通过学习值函数、根据值函数导出策略;而基于策略的算法,是直接显示地学习目标策略,策略梯度算法就是基于策略的算法。
策略梯度介绍
将策略描述为带有参数 θ \theta θ 的连续函数,可以将策略学习的目标函数定义为:
J ( θ ) = E s 0 [ V π θ ( s 0 ) ] J(\theta)=\mathbb{E}_{s_0}[V^{\pi_\theta}(s_0)] J(θ)=Es0[Vπθ(s0)]
我们将目标函数对参数 θ \theta θ 求导,得到导数,就可以用梯度上升方法来最大化目标函数,从而得到最优策略。
我们使用 ν π \nu^{\pi} νπ 表示策略 π \pi π 下的状态访问分布,得到如下式子:
∇ θ J ( θ ) ∝ ∑ s ∈ S ν π θ ( s ) ∑ a ∈ A Q π θ ( s , a ) ∇ θ π θ ( a ∣ s ) = ∑ s ∈ S ν π θ ( s ) ∑ a ∈ A π θ ( a ∣ s ) Q π θ ( s , a ) ∇ θ π θ ( a ∣ s ) π θ ( a ∣ s ) = E π θ [ Q π θ ( s , a ) ∇ θ log π θ ( a ∣ s ) ] \begin{aligned} \nabla_{\theta}J(\theta)& \propto\sum_{s\in S}\nu^{\pi_\theta}(s)\sum_{a\in A}Q^{\pi_\theta}(s,a)\nabla_\theta\pi_\theta(a|s) \\ &=\sum_{s\in S}\nu^{\pi_\theta}(s)\sum_{a\in A}\pi_\theta(a|s)Q^{\pi_\theta}(s,a)\frac{\nabla_\theta\pi_\theta(a|s)}{\pi_\theta(a|s)} \\ &=\mathbb{E}_{\pi_\theta}[Q^{\pi_\theta}(s,a)\nabla_\theta\log\pi_\theta(a|s)] \end{aligned} ∇θJ(θ)∝s∈S∑νπθ(s)a∈A∑Qπθ(s,a)∇θπθ(a∣s)=s∈S∑νπθ(s)a∈A∑πθ(a∣s)Qπθ(s,a)πθ(a∣s)∇θπθ(a∣s)=Eπθ[Qπθ(s,a)∇θlogπθ(a∣s)]
上式中期望的下标是 π θ \pi_{\theta} πθ ,因此对应的是使用当前策略 π θ \pi_{\theta} πθ 进行采样并计算梯度,通过梯度的修改,让策略更多地采样到较高Q值的动作。
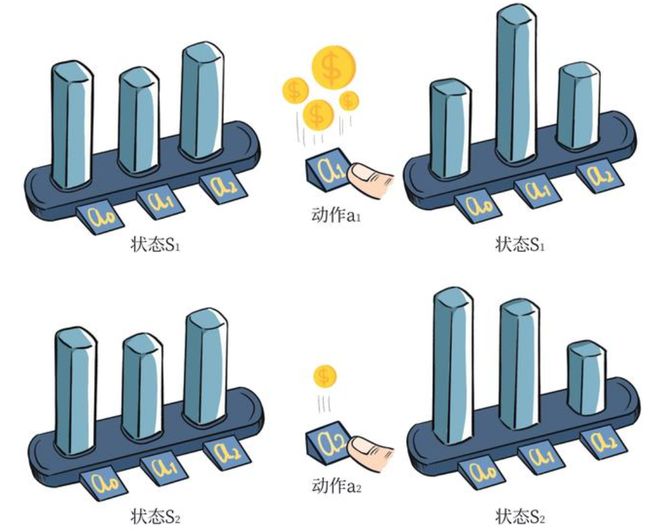
如上图所示,如果动作a1可以带来的价值更高,那么a1的概率会增大,对应的是a1的柱子变高。
在REINFORCE算法中,采用蒙特卡洛方法来估计 Q π θ ( s , a ) Q^{\pi_{\theta}}(s,a) Qπθ(s,a) ,对于一个有限步数的环境,该算法如下式所示:
∇ θ J ( θ ) = E π θ [ ∑ t = 0 T ( ∑ t ′ = t T γ t ′ − t r t ′ ) ∇ θ log π θ ( a t ∣ s t ) ] \nabla_\theta J(\theta)=\mathbb{E}_{\pi_\theta}\left[\sum_{t=0}^T\left(\sum_{t'=t}^T\gamma^{t'-t}r_{t'}\right)\nabla_\theta\log\pi_\theta(a_t|s_t)\right] ∇θJ(θ)=Eπθ[t=0∑T(t′=t∑Tγt′−trt′)∇θlogπθ(at∣st)]
REINFORCE算法介绍
具体流程如下所示:
- 初始化策略参数 θ \theta θ
- for 序列 e = 1 → E e=1\to E e=1→E do:
- 用当前策略 π θ \pi_{\theta} πθ 采样轨迹 { s 1 , a 1 , r 1 , s 2 , a 2 , r 2 , … s T , a T , r T } \{s_{1},a_{1},r_{1},s_{2},a_{2},r_{2},\ldots s_{T},a_{T},r_{T}\} {s1,a1,r1,s2,a2,r2,…sT,aT,rT}
- 计算当前轨迹每个时刻的回报 ∑ t ′ = t T γ t ′ − t r t ′ \sum_{t^{\prime}=t}^T\gamma^{t^{\prime}-t}r_{t^{\prime}} ∑t′=tTγt′−trt′ ,记为 ψ t \psi_{t} ψt
- 对 θ \theta θ 进行更新, θ = θ + α ∑ t T ψ t ∇ θ log π θ ( a t ∣ s t ) \theta=\theta+\alpha\sum_t^T\psi_t\nabla_\theta\log\pi_\theta(a_t|s_t) θ=θ+α∑tTψt∇θlogπθ(at∣st)
- end for
代码实践
import gymnasium as gym
import torch
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
import rl_utils
# 定义一个策略网络,输入是某个状态,输出是该状态下的动作概率分布
# 通过softmax函数,输出概率分布
class PolicyNet(torch.nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim):
super(PolicyNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
return F.softmax(self.fc2(x), dim=1)
定义REINFORCE算法,以策略回报的1负数来表示损失函数,即 − ∑ t ψ t ∇ θ log π θ ( a t ∣ s t ) -\sum_t\psi_t\nabla_\theta\log\pi_\theta(a_t|s_t) −∑tψt∇θlogπθ(at∣st)
class REINFORCE:
def __init__(self, state_dim, hidden_dim, action_dim,learning_rate,gamma,device):
self.state_dim = state_dim
self.action_dim = action_dim
# 初始化策略网络
self.policy_net = PolicyNet(state_dim, hidden_dim, action_dim).to(device)
self.optimizer = torch.optim.Adam(params=self.policy_net.parameters(), lr=learning_rate)
self.gamma = gamma
self.device = device
def take_aciton(self, state):
# 根据动作概率分布随机采样
state = torch.tensor([state],dtype=torch.float).to(self.device)
action_prob = self.policy_net(state)
# 根据每个动作的概率进行采样
action_dist = torch.distributions.Categorical(action_prob)
action = action_dist.sample()
# 返回是哪个动作,类型为标量
return action.item()
def update(self, transition_dict):
reward_list = transition_dict['rewards']
state_list = transition_dict['states']
action_list = transition_dict['actions']
G=0
self.optimizer.zero_grad()
for i in reversed(range(len(reward_list))): #从最后一步算起
reward=reward_list[i]
G=reward+self.gamma*G
state=torch.tensor([state_list[i]],dtype=torch.float).to(self.device)
action=torch.tensor([action_list[i]]).view(-1,1).to(self.device)
log_prob = torch.log(self.policy_net(state).gather(1, action))
loss=-log_prob*G #每一步的损失哈桑农户
loss.backward() # 反向传播计算梯度
self.optimizer.step() # 梯度下降
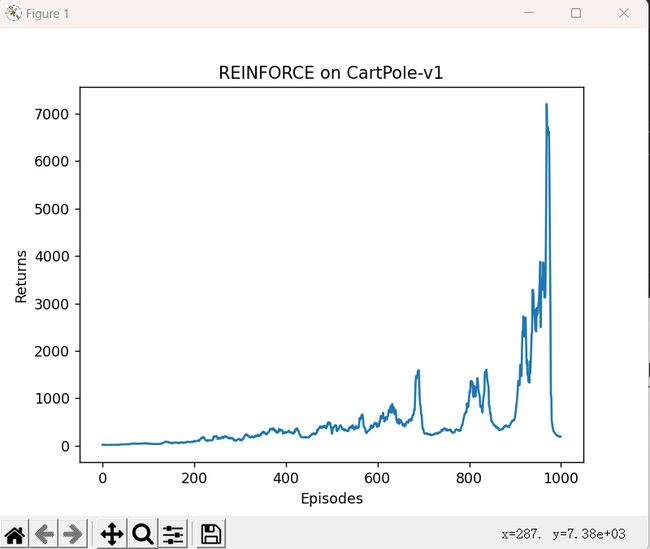
由于采用蒙特卡洛方法,REINFORCE算法的梯度估计的方差很大,会产生不稳定性,造成回报曲线的抖动。在我们对结果进行平滑处理后,可以得到较为光滑的曲线。
learning_rate = 1e-3
num_episodes = 1000
hidden_dim = 128
gamma = 0.98
device = torch.device("cuda") if torch.cuda.is_available() else torch.device(
"cpu")
env_name = "CartPole-v1"
env = gym.make(env_name)
torch.manual_seed(0)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
agent = REINFORCE(state_dim, hidden_dim, action_dim, learning_rate, gamma,
device)
return_list = []
for i in range(10):
with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes / 10)):
episode_return = 0
transition_dict = {
'states': [],
'actions': [],
'next_states': [],
'rewards': [],
'dones': []
}
state = env.reset()[0]
done = False
while not done:
action = agent.take_action(state)
next_state, reward, done, info, _= env.step(action)
transition_dict['states'].append(state)
transition_dict['actions'].append(action)
transition_dict['next_states'].append(next_state)
transition_dict['rewards'].append(reward)
transition_dict['dones'].append(done)
state = next_state
episode_return += reward
return_list.append(episode_return)
agent.update(transition_dict)
if (i_episode + 1) % 10 == 0:
pbar.set_postfix({
'episode':
'%d' % (num_episodes / 10 * i + i_episode + 1),
'return':
'%.3f' % np.mean(return_list[-10:])
})
pbar.update(1)
episodes_list = list(range(len(return_list)))
plt.plot(episodes_list, return_list)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('REINFORCE on {}'.format(env_name))
plt.show()
mv_return = rl_utils.moving_average(return_list, 9)
plt.plot(episodes_list, mv_return)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('REINFORCE on {}'.format(env_name))
plt.show()