Presto
目录
- 1. 什么是Presto?
- 2. 架构
- 3. SQL执行过程
- 4. 数据模型
- 5. 优化
- 参考
1. 什么是Presto?
Presto是一个facebook开源的,完全基于内存的并行计算的分布式SQL查询引擎,是一种Massively parallel processing (MPP)架构,多个节点管道式执行,适用于交互式分析查询,数据量支持GB到PB字节,presto的查询速度比hive快5-10倍。
适合做什么?
- PB级海量数据复杂分析
- 交互式SQL查询
- 支持跨数据源查询
不适合做什么?
多个大表的join操作,因为presto是基于内存的,多张大表在内存里可能放不下,并且就算放得下,查询过大的话,会占用整个集群的资源,这会导致你后续的查询是没有资源进行查询的,这跟presto的设计理念是冲突的。
和hive的对比
- hive是一个数据仓库,是一个交互式比较弱一点的查询引擎,交互式没有presto那么强,而且只能访问hdfs的数据
- presto是一个交互式查询引擎,可以在很短的时间内返回查询结果,秒级,分钟级,能访问很多数据源
2. 架构
hive架构:

hive: client将查询请求发送到hive server,它会和metastor交互,获取表的元信息,如表的位置结构等,之后hive server会进行语法解析,解析成语法树,变成查询计划,进行优化后,将查询计划交给执行引擎(默认是MR),然后翻译成MR,在YARN上执行,得出结果
Presto架构:



这里有三个服务
Coordinator(master)
负责meta管理,worker管理,query的解析和调度
Worker
负责计算和读写,是一个真正的计算的节点,执行任务的节点,它接收到task后,就会到对应的数据源里面,去把数据提取出来,提取方式是通过各种各样的connector。
Discovery service
是将coordinator和woker结合到一起的服务
1、Worker节点启动后向Discovery Server服务注册
2、Coordinator从Discovery Server获得Worker节点
对于presto的容错,如果某个worker挂掉了,discovery server会发现并通知coordinator
但是对于一个query,是没有容错的,一旦一个work挂了,那么整个qurey就是败了
因为对于presto,他的查询时间是很短的,与其查询这里做容错能力,不如重新执行来的快来的简单
3. SQL执行过程
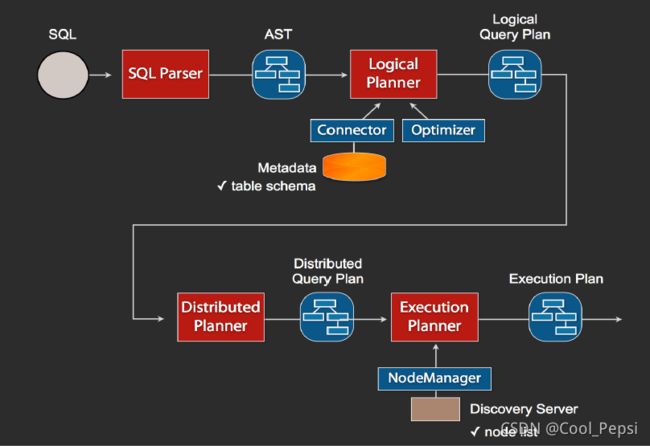
1、当我们执行一条sql查询,coordinator接收到这条sql语句以后,它会有一个sql的语法解析器去把sql语法解析变成一个抽象的语法树AST,这抽象的语法书它里面只是进行一些语法解析,如果你的sql语句里面,比如说关键字你用的是int而不是Integer,就会在语法解析这里给暴露出来
2、如果语法是符合sql语法规范,之后会经过一个逻辑查询计划器的组件,他的主要作用是,比如说你sql里面出现的表,他会通过connector的方式去meta里面把表的schema,列名,列的类型等,全部给找出来,将这些信息,跟语法树给对应起来,之后会生成一个物理的语法树节点,这个语法树节点里面,不仅拥有了它的查询关系,还拥有类型的关系,如果在这一步,数据库表里某一列的类型,跟你sql的类型不一致,就会在这里报错
3、如果通过,就会得到一个逻辑的查询计划,然后这个逻辑查询计划,会被送到一个分布式的逻辑查询计划器里面,进行一个分布式的解析,分布式解析里面,他就会去把对应的每一个查询计划转化为task
4、在每一个task里面,他会把对应的位置信息全部给提取出来,交给执行的plan,由plan把对应的task发给对应的worker去执行,这就是整个的一个过程
总的来说:
presto cli发送查询请求到coordinator -> coordinator接收到sql语句后解析查询计划 -> 查询计划会被送到分布式的逻辑查询计划器中进行分布式解析,从而将查询计划转化为task -> task会被送到对应的worker中执行 -> worker通过connector从数据源中取需要的数据 -> coordinator从worker取结果并返回给cli

task是放在每个worker上该执行的,每个task执行完之后,数据是存放在内存里了,而不像mr要写磁盘,然后当多个task之间要进行数据交换,比如shuffle的时候,直接从内存里处理
4. 数据模型

-
Catalog:就是数据源。每个数据源连接都有一个名字,一个Catalog可以包含多个Schema,可以通过show catalogs 命令看到Presto已连接的所有数据源。
-
Schema:相当于一个数据库实例,一个Schema包含多张数据表。通过以下方式可列出catalog_name下的所有 Schema: show schemas from ‘catalog_name’
-
Table:数据表,与RDBMS上的数据库表意义相同。通过以下方式可查看’catalog_name.schema_name’下的所有表:
show tables from ‘catalog_name.schema_name’
presto的存储单元包括:
- Page: 多行数据的集合,包含多个列的数据,内部仅提供逻辑行,实际以列式存储。
- Block:一列数据,根据不同类型的数据,通常采取不同的编码方式,了解这些编码方式,有助于自己的存储系统对接presto。
5. 优化
1)数据存储
- 合理设置分区:与 Hive 类似, Presto 会根据元数据信息读取分区数据,合理的分区能减少 Presto 数据读取量,提升查询性能。
- 使用列式存储:Presto 对 ORC 文件读取做了特定优化,因此在 Hive 中创建 Presto 使用的表时,建议采用 ORC 格式存储。相对于 Parquet, Presto 对 ORC 支持更好。
- 使用压缩:数据压缩可以减少节点间数据传输对 IO 带宽压力,对于即时查询需要快速解压,建议采用 Snappy 压缩。
注意:若使用hive,因为Hive 的SQL会转化为MR任务,如果该文件是用ORC存储,Snappy压缩的,因为Snappy不支持文件分割操作,所以压缩文件「只会被一个任务所读取」,如果该压缩文件很大,那么处理该文件的Map需要花费的时间会远多于读取普通文件的Map时间,这就是常说的「Map读取文件的数据倾斜」。
那么为了避免这种情况的发生,就需要在数据压缩的时候采用bzip2和Zip等支持文件分割的压缩算法。但恰恰ORC不支持刚说到的这些压缩方式,所以这也就成为了大家在可能遇到大文件的情况下不选择ORC的原因,避免数据倾斜。
在Hive on Spark的方式中,也是一样的,Spark作为分布式架构,通常会尝试从多个不同机器上一起读入数据。要实现这种情况,每个工作节点都必须能够找到一条新记录的开端,也就需要该文件可以进行分割,但是有些不可以分割的压缩格式的文件,必须要单个节点来读入所有数据,这就很容易产生性能瓶颈。
「所以在实际生产中,使用Parquet存储,lzo压缩的方式更为常见,这种情况下可以避免由于读取不可分割大文件引发的数据倾斜。 但是,如果数据量并不大(预测不会有超大文件,若干G以上)的情况下,使用ORC存储,snappy压缩的效率还是非常高的。」
2)查询SQL
-
只选择使用的字段:由于采用列式存储,选择需要的字段可加快字段的读取、减少数据量。避免采用*读取所有字段。
-
过滤条件必须加上分区字段:对与对分区的表,where语句中优先使用分区字段进行过滤。
-
Group By语句优化:合理安排 Group by 语句中字段顺序对性能有一定提升。将 Group By 语句中字段按照每个字段 distinct 数据多少进行降序排列。
-
使用join语句将大表放在左边:Presto 中 join 的默认算法是 broadcast join,即将 join 左边的表分割到多个 worker,然后将 join右边的表数据整个复制一份发送到每个worker 进行计算。如果右边的表数据量太大,则可能会报内存溢出错误。
3)内存优化
Presto有三种内存池,分别为GENERAL_POOL、RESERVED_POOL、SYSTEM_POOL。
-
GENERAL_POOL:用于普通查询的physical operators。GENERAL_POOL值为 总内存(Xmx值)- 预留的(max-memory-per-node)- 系统的(0.4 * Xmx)。
-
SYSTEM_POOL:系统预留内存,用于读写buffer,worker初始化以及执行任务必要的内存。大小由config.properties里的resources.reserved-system-memory指定。默认值为JVM max memory * 0.4。
-
RESERVED_POOL:大部分时间里是不参与计算的,只有当同时满足如下情形下,才会被使用,然后从所有查询里获取占用内存最大的那个查询,然后将该查询放到 RESERVED_POOL 里执行,同时注意RESERVED_POOL只能用于一个Query。大小由config.properties里的query.max-memory-per-node指定,默认值为:JVM max memory * 0.1。


注意点:
(必须) query.max-total-memory-per-node * work节点数 <= JVM最大内存
(必须) query.max-total-memory-per-node > query.max-memory-per-node
(建议) query.max-total-memory-per-node >= query.max-memory-per-node * 2
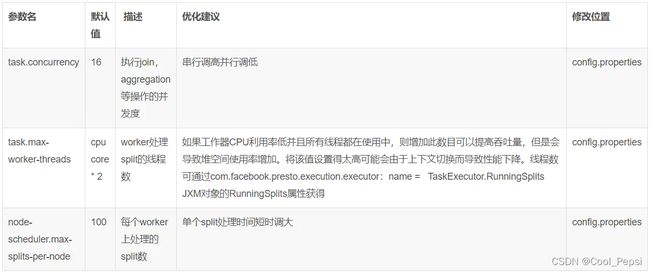
4) 并行度优化
参考
https://zhuanlan.zhihu.com/p/101366898
https://blog.csdn.net/u011596455/article/details/86558218
https://blog.csdn.net/weixin_38255444/article/details/105419445
代码:
http://t.zoukankan.com/barneywill-p-10478959.html