Hbase
1. 什么是Hbase?
HBASE是一个数据库----可以提供数据的实时随机读写(MySQL就不行)
HBASE与mysql、oralce、db2、sqlserver等关系型数据库不同,它是一个NoSQL数据库(非关系型数据库)
HBASE相比于其他NoSQL数据库(mongodb、redis、cassendra、hazelcast)的特点:
Hbase的表数据存储在HDFS文件系统中
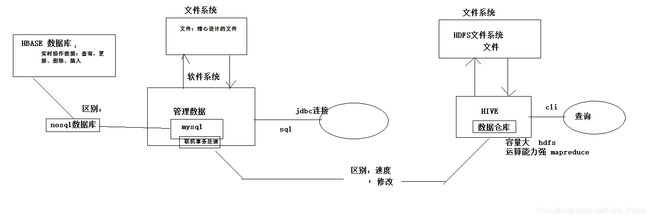
从而,hbase具备如下特性:存储容量可以线性扩展; 数据存储的安全性可靠性极高!
2. Hbase表
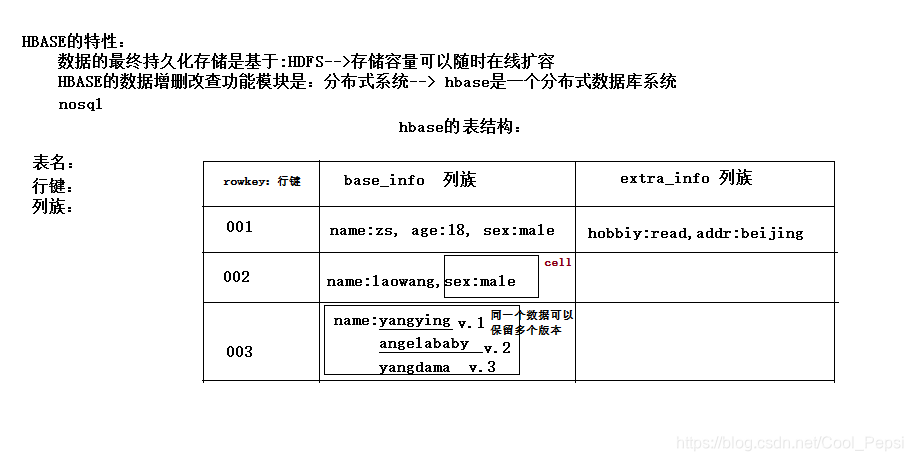
2.1 表模型
要点:
1、一个表,有表名
2、一个表可以分为多个列族(不同列族的数据会存储在不同文件中)
3、表中的每一行有一个“行键rowkey”,而且行键在表中不能重复
4、表中的每一对key-value数据称作一个cell,可以存储任意多个kv;这里的key可理解为列
值得注意的是 列族名+列名(key) 才是Hbase表中的key,例如 base_info:name
5、hbase可以对数据存储多个历史版本–时间戳(历史版本数量可配置)
6、整张表由于数据量过大,会被横向切分成若干个region(用rowkey范围标识),不同region的数据也存储在不同文件中
2.2 表存储的数据类型
hbase中只支持byte[]
此处的byte[] 包括了: rowkey,key,value,列族名,表名
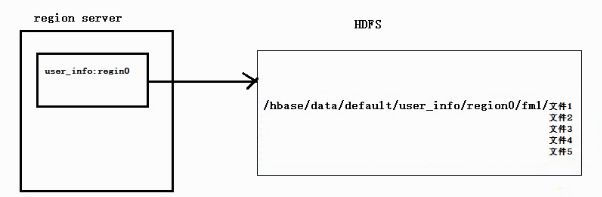
2.3 表的存储的物理结构
注意上图中说的:数据的最终持久化存储是基于HDFS
最终?那hbase的数据会暂存在哪里?
会暂存在 负责该数据操作所在的region service的机器内存中,凡是经过访问(增删改查)的数据都会先暂存在内存中,此时这些数据称为热数据;当内存满了或者过了一段时间这些数据没有访问变“冷”,就会写到HDFS中。

在HDFS中会先有个hbase文件目录,然后下两级是 data/defalut(默认的库或者自定义的库),然后依次按表、region、列族来存储数据。最后的StoreFile并不是只有一个;
2.3.1 布隆过滤器
例如文件1中经过了插入user_info:username:zhangsan的操作,由于内存满了写到HDFS中;但是由于HDFS中的文件不可修改,下次想修改username:lisi的时候,不会修改文件1,而是再写多一个文件2;如此反复,文件1 ~ 文件n 中肯定存在很多相同的key但不同value值,当然版本也不一样;当我们想查询username时,怎么办?
最蠢的办法就是遍历每一个文件查询username,然后返回版本最新的那一个value值。但是并不是每一个文件都有username这个key的存在(例如这些文件根本就没有对username这个key进行任何操作,所以就没有写入该文件中),这样遍历岂不是浪费很多时间?
解决方法:设置布隆过滤器。这里就不介绍布隆过滤器了。
3. Hbase工作机制
需要以下功能组件:
- HDFS – 存储数据的
- 许多个Region服务器
- 一个或两个Master主服务器(2个或多个是为了实现高可用)
- zookeeper
Master服务器
主服务器Master主要负责表和Region的管理工作:
- 实现不同Region服务器之间的负载均衡
- 在Region分裂或合并后,负责重新调整Region的分布
- 对发生故障失效的Region服务器上Region进行迁移
Region服务器
Region服务器是Hbase中最核心的模块,负责维护分配给自己的Region,并响应用户的读写请求。
ZooKeeper
- 监管region services和master services的状态
- 存储meta表信息,meta表内存储的是region的信息(哪一个范围的行键属于哪一个region,该region在哪一个region service上)
3.1 数据存储原理
- 一个HRegionServer会负责管理很多个region,HRegionServer就是分布在HDFS上的DataNodes节点上,数据也最终存在在对应的节点上
- 一个region包含很多个store,一个列族就划分成一个store。如果一个表中只有1个列族,那么每一个region中只有一个store;如果一个表中有N个列族,那么每一个region中有N个store
- 一个store里面只有一个memstore,memstore是一块内存区域,写入的数据会先写入memstore进行缓冲,然后再把数据刷到磁盘
- 一个store里面有很多个StoreFile, 最后数据是以很多个HFile这种数据结构的文件保存在HDFS上。StoreFile是HFile的抽象对象,每次memstore刷写数据到磁盘,就生成对应的一个新的HFile文件出来
3.2 读数据流程
HBase集群,只有一张meta表,此表只有一个region,该region数据保存在一个HRegionServer上
- 客户端首先与zk进行连接;从zk找到meta表的region位置,即meta表的数据存储在某一HRegionServer上;客户端与此HRegionServer建立连接,然后读取meta表中的数据;meta表中存储了所有用户表的region信息,我们可以通过scan 'hbase:meta’来查看meta表信息
- 根据要查询的namespace、表名和rowkey信息。找到写入数据对应的region信息
- 找到这个region对应的regionServer,然后发送请求
- 查找并定位到对应的region
- 先从memstore查找数据,如果没有,再从BlockCache上读取。HBase上Regionserver的内存分为两个部分一部分作为Memstore,主要用来写;另外一部分作为BlockCache,主要用于读数据;
- 如果BlockCache中也没有找到,再到StoreFile上进行读取从storeFile中读取到数据之后,不是直接把结果数据返回给客户端,而是把数据先写入到BlockCache中,目的是为了加快后续的查询;然后在返回结果给客户端。
下图时取数据的流程:

3.2 写数据流程

1、客户端首先从zk找到meta表的region位置,然后读取meta表中的数据,meta表中存储了用户表的region信息
2、根据namespace、表名和rowkey信息。找到写入数据对应的region信息
3、找到这个region对应的regionServer,然后发送请求
4、把数据分别写到HLog(write ahead log)和memstore各一份
5、memstore达到阈值后把数据刷到磁盘,生成storeFile文件
6、删除HLog中的历史数据
4. Hbase客户端API操作
4.1 DDL
public class HbaseClientDDLDemo {
Connection conn = null;
@Before
public void getConn() throws Exception{
//构建一个连接对象
Configuration conf = HBaseConfiguration.create();
// 设置zookeeper在哪?
conf.set("hbase.zookeeper.quorum", "hadoop100:2181,hadoop101:2181,hadoop102:2181");
conn = ConnectionFactory.createConnection(conf);
}
/**
* DDL
* @throws Exception
*/
// 建表
@Test
public void testCreateTable() throws Exception{
// 从连接中构建一个DDL操作器
Admin admin = conn.getAdmin();
// 创建一个表定义描述对象
HTableDescriptor hTableDescriptor = new HTableDescriptor(TableName.valueOf("user_info"));
// 创建列族定义描述对象
HColumnDescriptor hColumnDescriptor_1 = new HColumnDescriptor("base_info");
hColumnDescriptor_1.setMaxVersions(3);//设置该列族中存储的数据的最大版本数,默认1
HColumnDescriptor hColumnDescriptor_2 = new HColumnDescriptor("extra_info");
// 将列族信息对象添加到表中
hTableDescriptor.addFamily(hColumnDescriptor_1);
hTableDescriptor.addFamily(hColumnDescriptor_2);
// 用ddl操作器对象:admin来建表
admin.createTable(hTableDescriptor);
admin.close();
conn.close();
}
// 删除
@Test
public void testDropTable() throws Exception{
Admin admin = conn.getAdmin();
// 停用表
admin.disableTable(TableName.valueOf("user_info"));
// 删除表
admin.deleteTable(TableName.valueOf("user_info"));
admin.close();
conn.close();
}
// 修改表定义 -- 添加一个列族
public void testAlterTable() throws Exception{
Admin admin = conn.getAdmin();
// 取出旧的表定义信息
HTableDescriptor tableDescriptor = admin.getTableDescriptor(TableName.valueOf("user_info"));
// 新构造一个列族定义
HColumnDescriptor hColumnDescriptor = new HColumnDescriptor("other_info");
hColumnDescriptor.setBloomFilterType(BloomType.ROW);
// 将列族定义对象添加到表定义对象中
tableDescriptor.addFamily(hColumnDescriptor);
admin.modifyTable(TableName.valueOf("user_info"),tableDescriptor );
admin.close();
conn.close();
}
}
4.2 DML
/**
* DML
*/
public class HbaseClienDMLtDemo {
Connection conn = null;
@Before
public void getConn() throws Exception{
//构建一个连接对象
Configuration conf = HBaseConfiguration.create();
// 设置zookeeper在哪?
conf.set("hbase.zookeeper.quorum", "hadoop100:2181,hadoop101:2181,hadoop102:2181");
conn = ConnectionFactory.createConnection(conf);
}
/**
* 增
* 改(覆盖)
*/
@Test
public void testPut() throws IOException{
// 获取一个操作指定表的table对象,进行DML操作
Table table = conn.getTable(TableName.valueOf("user_info"));
// 构造要插入的数据为一个Put类型的对象(一个put对象只能对应一个rowkey)
Put put = new Put(Bytes.toBytes(1));
put.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("username"), Bytes.toBytes("xxx"));
put.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("age"), Bytes.toBytes("18"));
put.addColumn(Bytes.toBytes("extra_info"), Bytes.toBytes("salary"), Bytes.toBytes("20k"));
Put put2 = new Put(Bytes.toBytes(1));
put2.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("username"), Bytes.toBytes("xxx"));
put2.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("age"), Bytes.toBytes("18"));
put2.addColumn(Bytes.toBytes("extra_info"), Bytes.toBytes("salary"), Bytes.toBytes("20k"));
ArrayList<Put> puts = new ArrayList<>();
puts.add(put);
puts.add(put2);
table.put(puts);
table.close();
conn.close();
}
/**
* 删
* @throws IOException
*/
@Test
public void testDelete() throws IOException{
Table table = conn.getTable(TableName.valueOf("user_info"));
// 删除整行
Delete delete1 = new Delete(Bytes.toBytes("001"));
// 删除某个列族信息的某个key
Delete delete2 = new Delete(Bytes.toBytes("001"));
delete2.addColumn(Bytes.toBytes("extra_info"), Bytes.toBytes("salary"));
ArrayList<Delete> dels = new ArrayList<>();
dels.add(delete1);
dels.add(delete2);
table.delete(dels);
table.close();
conn.close();
}
/**
* 查
* @throws Exception
*/
@Test
public void testGet() throws Exception{
Table table = conn.getTable(TableName.valueOf("user_info"));
// 单行查询
Get get = new Get("001".getBytes());
Result result = table.get(get);
// 取单个值
byte[] value = result.getValue("base_info".getBytes(), "age".getBytes());
// 遍历整行结果中的所有kv单元格
CellScanner cellScanner = result.cellScanner();
while(cellScanner.advance()){
Cell cell = cellScanner.current();
byte[] rowArray = cell.getRowArray();
byte[] familyArray = cell.getFamilyArray();
byte[] qualifierArray = cell.getQualifierArray();
byte[] valueArray = cell.getValueArray();
// 注意:列族名+列名 才是hbase的key
// 因为hbase中一条数据有自己存储的数据之外还有附加信息,所以要指定从哪里开始到哪里结束,这才是我们要的数据
System.out.println("行键:"+new String(rowArray,cell.getRowOffset(),cell.getRowLength()));
System.out.println("列族名:"+new String(familyArray,cell.getFamilyOffset(),cell.getFamilyLength()));
System.out.println("列名:"+new String(qualifierArray,cell.getQualifierOffset(),cell.getQualifierLength()));
System.out.println("value:"+new String(valueArray,cell.getValueOffset(),cell.getValueLength()));
table.close();
conn.close();
}
}
/**
* 按行键范围查询数
*/
@Test
public void testScan() throws Exception{
Table table = conn.getTable(TableName.valueOf("user_info"));
// 从哪一行开始,到哪一行结束
// 包含起始行键但不包含结束行键
// 但是如果真的想查出末尾的行键,可以在末尾行键上凭借一个不可见的字节 \000
Scan scan = new Scan("001".getBytes(), "005\000".getBytes());
ResultScanner scanner = table.getScanner(scan);
Iterator<Result> iterator = scanner.iterator();
while(iterator.hasNext()){
Result result = iterator.next();
// 遍历整行结果中的所有kv单元格
CellScanner cellScanner = result.cellScanner();
while(cellScanner.advance()){
Cell cell = cellScanner.current();
byte[] rowArray = cell.getRowArray();
byte[] familyArray = cell.getFamilyArray();
byte[] qualifierArray = cell.getQualifierArray();
byte[] valueArray = cell.getValueArray();
// 因为hbase中一条数据有自己存储的数据之外还有附加信息,所以要指定从哪里开始到哪里结束,这才是我们要的数据
System.out.println("行键:"+new String(rowArray,cell.getRowOffset(),cell.getRowLength()));
System.out.println("列族名:"+new String(familyArray,cell.getFamilyOffset(),cell.getFamilyLength()));
System.out.println("列名:"+new String(qualifierArray,cell.getQualifierOffset(),cell.getQualifierLength()));
System.out.println("value:"+new String(valueArray,cell.getValueOffset(),cell.getValueLength()));
}
System.out.println("---------------------------");
}
}
}