03-Flink内存模型
如何处理缓存和高效处理
1 自主管理内存
Flink从一开始就选择了使用自主的内存管理,避开了JVM内存管理在大数据场景下的问题,提升了计算效率.
1.1 JVM内存管理的不足
1.1.1 有效数据密度低
存储:对象头、实例数据、对齐填充部分
导致JVM中有效信息的存储密度很低
1.1.2 垃圾回收
Full GC会严重影响性能以及和集群中的心跳信息超时,使得无法进行调优
1.1.3 OOM问题影响稳定性
1.1.4 缓存未命中问题
CPU和内存访问效率和计算是差了很多
1.2 自主管理
- 内存管理
- 定制得序列化工具
- 缓存友好的数据结构和算法
- 堆外内存等
MemorySegment 是一段固定长度的内存(默认是32KB)并且提供了非常高效的读写,可以直接操作二进制数据,不需要反序列化就可以执行。
堆上内存:java Byte数组中
堆外内存:ByteBuffer中
每条数据记录都会以序列化的形式存储在一个或多个 MemorySegment 中。
堆上内存如果处理的数据超出了内存限制,则会将部分数据存储到硬盘上,操作多块MemorySegment 就想操作一块大的连续内存一样,Flink会使用逻辑视图(AbstractPagedInputView)方便操作。
2.1.1 堆上内存的不足
1)超大内存(上百GB)JVM的启动需要很长时间,Full GC 可以达到分钟级别,使用堆外内存,可以将大量的数据保存在堆外,极大的减少了堆内存,避免GC和内存溢出的问题。
2)高效的IO操作,堆外内存在写磁盘或网络传输时是zero-copy,而堆上内存则至少需要1次内存复制。
3)堆外内存是进程间共享的,也就是说,即使JVM进程崩溃也不会丢失数据,可以用来做故障恢复(Flink暂时没有利用这项功能,不过未来很困难会去做)。
2.1.2 堆外内存的不足
堆外内存提供了更好的性能和更可控的内存管理,但是也存在几个问题:
1)堆上内存的使用、监控、调试简单,堆外内存出现问题后的诊断则较为复杂。
2)Flink有时需要分配短生命周期的MemorySegment,在堆外内存是哪个分配比在堆上内存开销更高。
3)在Flink的测试中,部分操作在堆外内存会比堆上内存慢
同时为了提高效率,Flink在计算中采用了DBMS的 Sort 和 Join 算法,直接操作二进制数据,避免数据反复序列化带来的开销。
2 内存模型
Flink 1.10 以前的版本中内存模型存在一些缺陷,导致优化资源利用率比较困难:
- 流和批处理内存占用的配置模型不同、配置参数多、关系乱。
- 流处理中的RocksDBStateBackend需要依赖用户进行复杂的配置。
2.1 TaskManager内存布局
TaskManager是Flink中执行计算的核心组件,是用来运行用户代码的java进程,其中大量使用了堆外内存。
注意:托管内存也叫管理内存。
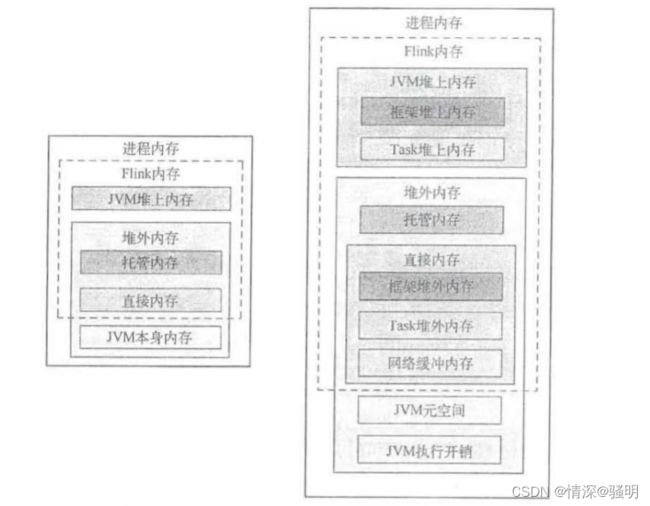
2.1 Flink 使用的内存
(1) 堆上内存
- taskmanager.memory.framework.heap.size=128MB
- taskmanager.memory.task.heap.size=无穷
(2)堆外内存
- taskmanager.memory.framework.off-heap.size=128MB
- taskmanager.memory.task.off-heap.size=0
- taskmanager.memory.network[64/1024/0.1].size
默认是min、max、fraction=0.1 - taskmanager.memory.managed.[size/fraction]
默认fraction=0.4
(3)JVM 本身使用的内存
- taskmanager.memory.jvm-metaspace=96MB
- taskmanager.memory.jvm-overhead=[min/max/fraction]
JVM 在执行自身需要的内存,包括线程堆栈、IO、编译缓存等所使用的内存,min=192MB、max=1GB、fraction=0.1
(4)总体内存
- taskmanager.memory.flink.size
Flink使用内存:堆上、堆外内存 - taskmanager.memory.process.size
进程使用内存=Flink使用内存+JVM使用的内存
(5)JVM内存控制参数
1)JVM堆上内存,使用 ----> -Xmx和-Xms
2)JVM直接内存,使用 -----> -XX:MaxDirectMemorySize
3)托管/管理内存,使用 ----> Unsafe.allocateMemory()申请,不受参数的控制
4)JVM MetaSpace 使用 ----> -XX:MaxMetaspaceSize进行控制
3 内存计算
1)在Standalone部署模式下,内存的计算在启动脚本中实现
2)在容器中,计算在ResourceManager中进行
flink-1.7.1/bin/flink run \
-m yarn-cluster \
-yD hostname=wn18ddzxjap1002 \
-yD job.inst.id=103989 \
-yD security.kerberos.login.principal=5D7... \
-yD security.kerberos.login.keytab=/etc/security/keytabs/5D7....keytab \
-yD metrics.reporters=sla \
-yD metrics.reporter.sla.class=com.ksyun.dc.metrics.flink.CollectMetrics \
-yD metrics.reporter.sla.url=http://ops-platform.internal-bigdata.com:9080/api/metrics/streaming/batch -yD metrics.reporter.sla.interval='60 SECONDS' \
-ynm store_goods_amount_join_done \
-c com.ksyun.dc.streaming.framework.ApplicationOnScheduler -\
yn 1 -ys 1 -p 1 -yjm 1024 -ytm 3072 \
-yqu ksccd365... \
-yt /tmp/flink/yarnship/1180 \
-n -d /flink-1.7.1/framework/streaming-dist-1.0-SANPSHOT-fat.jar
命令行参数:
-c:指定程序入口类
-p:指定多少个并发度
-yD:动态自定义参数
-m yarn-cluster -yn 1:使用yarn集群启动1个tm
-yjm:指定jm的内存大小
-ytm:指定tm的内存大小
-ys:每个tm的slot数量
-yqu:指定yarn资源队列
-d:以detached模式运行
flink list:查看进群上运行的job
flink cancel:取消job
flink list --all:查看所有job,包括cancel的
(1)TaskManager堆上内存和托管内存
如果手动配置了网络缓冲区内存大小,则使用该参数,如果没有明确配置,则使用分配稀疏fraction * 总体Flink使用的内存计算网络缓冲区大小
(2)总的Flink内存
如果配置了该选项,而没有配置(1),则从总体Flink内存中划分网络缓冲区内存和托管内存,剩余的内存作为Task堆上内存
如果手动设置了网络缓冲区,则使用其值,否则使用默认的分配系数 fraction * 总体Flink 内存
如果手动设置了托管内存,则使用其值,否则使用默认的分配系数fraction * 总体 Flink 内存
(3)总体进程使用内存
如果只配置了总体进程使用内存,则从总体进程中扣除JVM元空间和JVM执行开销内存,剩余的内存作为总体使用内存