论文笔记-‘Confidence-Guided Self Refinement for Action Prediction in Untrimmed Videos’
论文笔记:‘Confidence-Guided Self Refinement for Action Prediction in Untrimmed Videos’
Author:Jingyi Hou,Xinxiao Wu,Ruiqi Wang,Jiebo Luo,Yunde Jia
URL:https://ieeexplore.ieee.org/document/9070175
Abstract
现有的动作预测 (action prediction) 任务大多是识别修剪的视频中的早期部分。本文中,我们从未修剪的视频中预测动作,而这些动作可能在视频的刚开始阶段并没有发生。由于视频早期部分的动作信息不明确甚至没有动作信息,预测此类未修剪视频中的动作极具挑战性。为了解决这个问题,文中提出了一种评估预测模型决策质量的预测置信度。在置信度的引导下,模型随着观察到的视频帧数的增加,不断地自行细化预测结果。具体来说,我们构建了一个自我预测细化网络(SPR-Net),它逐步学习动作预测的置信度。SPR-Net由三个模块构成:a temporal hybrid network, an incremental confidence learner, and a self-refining Gumbel softmax sampler.(一个时间聚合网络,一个增量的置信度学习器,一个自我修正的Gumbel-softmax采样器)。时间聚合网络通过整合静态场景和动态运动信息生成动作类别分布。 增量置信学习器以增量方式计算预测的置信度,判断时间聚合网络应该相信其预测结果的程度。 自精炼的 Gumbel softmax 采样器对预测置信度和类别分布之间的相互关系进行建模,这使它们能够以端到端的方式联合学习。还提出了一种稀疏自注意力机制,将局部时空特征编码到帧级运动表示中,以进一步提高预测性能。在五个数据集上进行了实验(UT-Interaction, BIT-Interaction, UCF101, THUMOS14, and ActivityNet)。
1. Introduction
现有的多数工作针对的是修剪过的视频。而现实中,在预测之前对正在进行的视频修剪是不可能的。
我们处理一个更实用和更一般的任务,即在未修剪和修剪的视频中预测动作。挑战在于视频早期部分的动作信息不明确甚至没有动作信息。但在动作发生前的早期视频帧中,一些信息丰富且与动作相关的线索可以在一定程度上帮助预测类别标签。然而,在动作预测的过程中,观察到的信息是否足以推断出正确的类别标签对预测器来说仍然是不可知的,这与动作识别和多媒体事件检测等典型的认知任务有很大不同。在实践中,决策信息的充足性对于人类来说并不是绝对不可知的,因为人类的大脑可以产生一种自我评估,即信心,来调整决策(在心理学中称为元认知)。因此更适合将动作预测视为涉及元认知的动态过程,而不仅仅是在部分可用的视频中识别动作的认知任务。
我们认为预测任务的三个问题:①(when)什么时候观察到的信息对于预测来说是足够的。在视频早期,由于信息的不充分,可能会导致错误预测。所以我们引入了预测置信度来评估预测质量。②(what)视频中的哪些信息应该被用来做预测。由于视频中存在噪声,例如杂乱的背景和不相关的动作,这会降低预测性能,因此从观察到的视频流中学习判别特征表示成为准确预测动作的重要问题。③如何充分建立上述两个两个问题的联系。一方面,置信度指导预测模型学习鲁棒的判别表示。另一方面,特征表示的学习过程会影响置信度的值。所以“when”和“what”的联合学习可以提升预测性能。
为了解决上述三个问题,我们提出了Self Prediction Refining Network (SPR-Net),它逐步学习置信度值以自动优化动作预测的结果。 我们将预测任务分解为通过增量置信学习器估计预测的置信度和通过时间聚合网络学习分类的判别表示,分别解决“何时”和“什么”的问题。为了共同学习这两个子任务,使它们相互受益,提出了一种自我改进的 Gumbel softmax 采样器,它可以处理“如何”问题。 图 1 说明了 SPR-Net 的动作预测过程。
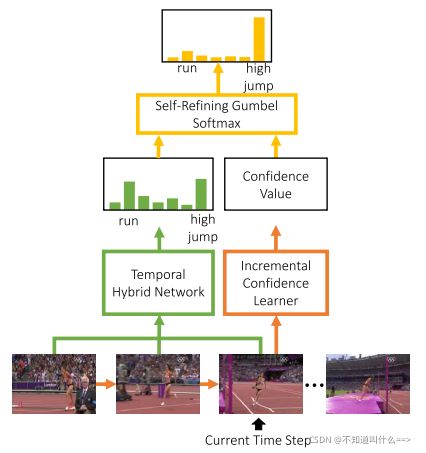
图1. 已观测到的动作类别分布由Temporal hybrid network生成。预测置信度由预测置信度和类别分布之间的相互关系计算,由自调整的 Gumbel softmax 采样器建模。 通过 SPR-Net 的反向传播,可以学习置信度值来细化最终的预测。
具体来说,预测置信度是信息量的体现,随着信息量的增加而变高。 直观上,每个时间步的置信度值的增量取决于当前信息的关键程度。因此,我们提出增量置信学习器来动态更新置信度。
时间聚合网络由带有 GRU 的 RNN 层和一维卷积层 (Conv1D) 组成,用于利用与动作相关的信息来生成动作类别的分布。 带有 GRU 的 RNN 表示观察到的视频流中的上下文场景信息,Conv1D 通过卷积运算描述视频的静态信息。
自调整的 Gumbel softmax 采样器对预测置信度和类别分布的相互关系进行建模。该采样器通过重新参数化程序根据预测置信度调整类别分布的平滑度。在包含模糊动作模式的前几帧中,采样器生成相对较低的置信度值以及 Gumbel 随机变量,以使输出均匀分布,以探索更多可能的动作类别。当涉及包含关键信息的帧时,增加的置信度将强制分布逼近 one-hot 向量,这有助于更容易地收敛训练。通过自调整的 Gumbel softmax 采样器的学习,调整后的置信度有助于为正确的类别分布发现更多的判别信息,而精炼的类别分布通过迫使模型尽早生成高置信度来促进及时预测。
我们还将 Sparse Self-Attention (SSA) 模块集成到 SPR-Net 中以表示每个时间步的运动信息。 SSA 模块执行多个 self-attention 操作,将局部时空运动特征融合为统一的帧级特征。使用sparsemax进行注意力权重调整。
本文贡献主要有三点:
①我们提出了预测置信度,通过将动作预测看作元认知过程来预测未修剪视频中具有低观察率的动作。
②我们构建了一个名为 SPR-Net 的新型深度神经网络,用于基于置信度的动作预测,包括增量置信度学习器、时间聚合网络和自我完善的 Gumbel softmax 采样器,可以以端到端的方式进行训练。
③我们开发了一个新的稀疏自注意力模块来有效地表示动作的运动信息,也可以很容易地集成到其他网络中进行动作分析。
2. Related work
Action prediction
…
Decision confidence
the confidence coding and the decision-making are in separate areas.
Attention mechanism for video representation
Our sparse self-attention module can capture multiple aspects of action videos using repetitive attention operations. It is more reasonable because a video clip might contain multiple features worthy of attention, and only one attention operation is not adequate for capturing all the information.
3.Self Prediction Refining Network (SPR-Net)

每一帧的场景信息特征由ResNet生成。运动信息由Res3D生成,并经过了SSA增强。时空特征和运动特征通过Tempral hybrid network(绿色框)聚合。
Temporal hybrid network
由一层带GRU的RNN和一层Conv1D组成。RNN with GRUs用来记录历史帧的场景信息。用GRU是为了加速计算。由于多层卷积操作具有表示用于分类的各种判别模式的良好特性,因此我们在 GRU 之后使用 Conv1D 来生成动作类别分布。
具体来说,帧级的场景特征通过RNN来获得上下文信息。然后和帧级的运动信息做concatenation。concat之前做了特征归一化。因为这两种特征在尺度上不一致,在训练过程中直接进行concatenation会导致损失函数陷入NaN。

归一化操作如式1,s[t]代表某个时间帧,维度为D,μ和σ代表每一维的平均值和标准差。α和β是可学习的参数。层归一化后的特征对于它们之前的尺度是不变的,因为 μ 的减运算和 σ 的除法运算使特征与尺度去相关。之后经过Conv1D生成类别分布。如图3所示。

Incremental confidence learner
渐进置信度学习器的思想是当前置信度取决于当前观察到的信息之前是否发生过和当前观察到的信息是否有助于预测动作类别。第t帧的置信度c^(t)计算如下:
Δ(t)是由帧级的运动特征v(t)和场景特征r(t)得到的渐进式的置信度。将用于生成置信度的特征f(t)定义为:
![]()
渐进置信度Δ(t)由f(t)得到:
![]()
其中 g(·) 将 f(t) 从高维向量空间映射到正实数空间 R+ 以保证置信度值随时间单调非递减。ω(t) 是衡量当前和先前时间步长之间帧差异的比例因子:
d(.,.)计算距离:
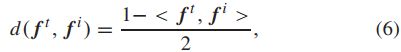
< >表示余弦相似度。为了保持置信值的范围,我们将置信值限制为:![]()
γ和η用来控制sigmoid的范围和斜率。
Self-refining gumbel softmax
用{pi(i,t) | i=1,2, … ,L}来表示第t帧的类别概论分布,L为类别数。为了充分利用动作分布信息,我们通过使用 Gumbel max 技巧从分布中采样来预测动作类别,该技巧已成功用于训练生成模型和强化学习。Gumbel max定义如下:
onehot(i,L)返回长度为L,第i个元素为1的onehot向量,g(i,t)是从Gumbel(0, 1) 分布中抽取的随机变量,彼此相互独立。
式(8)不能作为最终的预测结果有三个原因。第一,y^(t)是不可微的,所以无法通过反向传播训练网络。第二,不同的one-hot向量之间应该有其他动作类别分布向量,因为早期阶段很难决定正确预测。第三,应考虑式(7)中的时间步长的置信度,即这项工作中的类别分布应该随着观察者的预测置信度的增长而不是训练时期的增长从连续收敛到离散。
基于以上考虑,我们提出了一种自我完善的 Gumbel softmax 采样器,用于联合学习类别分布和预测置信度。 在时间步长t,第i个类别的输出分布通过置信度ct进行细化,表示为:
可以观察到,yt 等于对ct·y’t 进行softmax 变换,它是可微的,用于逼近Eq(8) 中的算子。当输出概率接近均匀分布时,g^it 使得选择具有非最大概率的动作标签成为可能。一旦预测正确,置信度值就会变大,这意味着潜在的信息被发现了。当 ct 变大时,输出分布将变得更尖锐并接近于 one-hot 分布,因为![]()
通过使用自精炼 Gumbel softmax 优化 SPRNet 来联合学习预测置信度和类别分布。在训练过程中,通过置信度对类别分布进行细化使模型能够学习更多用于动作预测的判别特征,因为当自细化的 Gumbel 采样器生成更清晰的预测分布时,学习的特征会获得更多的关注和更高的置信度。此外,类别分布的预测也对置信度有积极影响,使所提出的模型能够及时做出正确的决策。特别是,预测指导训练期间置信度的调整,这有助于模型定位视频中最早可以在测试阶段在视频中产生较大置信度增量的帧。因此,预测类别分布和学习预测置信度的过程互惠互利,具有高预测精度和低观察延迟。
Sparse self-attention (SSA) of motions
为了有效地利用与动作预测任务密切相关的运动信息,我们提出了一种稀疏自注意力模型来学习帧级运动特征,如图 4 所示。这种机制允许由 Res3D 提取的局部时空特征在每个时间步聚合成帧级运动特征。由于只需要与预测相关的动作信息,所提出的 SSA 模块被集成到 SPR-Net 中,以端到端的方式用于学习突出最有用的局部特征并去除嘈杂的特征。考虑到视频片段中存在多个显著的局部特征,SSA 在每个时间步对每组局部特征多次应用注意力操作,并将输出的注意力特征连接到帧级运动特征中。引入了稀疏机制和惩罚项以通过 sparsemax 生成注意力权重以减少冗余。惩罚项在每个时间步保持注意力操作的多样性。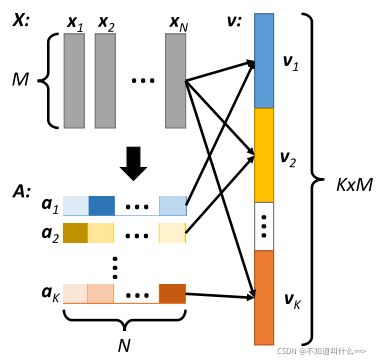
图4. 提出的稀疏自注意力模块。注意力权重向量 a1, . . . , aK 由具有局部时空特征 x1, . . , x N 作为输入,经过不同非线性函数生成。通过注意力向量对局部时空特征进行 K 次加权相加后,我们得到 v1, . . . , vK 并将它们连接成一个向量 v 用于最终的运动表示。
具体来说,视频中第i帧的局部时空特征是通过将第(i-15)到第i帧作为Res3D的输入获得的。当 i ≤ 15 时,输入帧用视频的第一帧填充。每帧的局部时空特征由矩阵 X = [x1, x2, . . . , xN]∈R(M×N)表示,其中xn ∈ R(M×1) 表示第n 个空间网格的特征向量,N 是空间网格的数量,M 是特征图的数量。输入X,经过K次注意力操作,得到特征v1,v2,…,vK,vK代表经过K次注意力操作后得到的特征向量:![]()
ak=[ak1, · · · , akN]∈ R(1×N),表示第k个注意力权重。每个时间步的帧级运动特征 v 由 vk (k = 1, 2,…, K) 的串联描述。
K组注意力权重是通过使用K个非线性映射函数来计算的。每一个注意力权重A=[a1T, a2t, …, aKT]^T:
W1,W2是权重矩阵,b1,b2是偏置矩阵。
sparsemax按行操作,对于a^k,sparsemax优化:![]()
(这部分优化没看明白)大概就是注意力权重经过sparsemax变得稀疏,然后不同的权重对应注意的局部特征不同。与softmax注意力激活相比更容易优化。
Experiments and discussion
dataset
UT-Interaction, BIT-Interaction, UCF101, THUMOS14, ActivityNet
Implementation details
(1)Feature representation.
分别用ResNet152和Res3D提取帧的场景和局部时空特征。
(2)Data augmentation. 主要为了避免过拟合。
(3)Parameter setting. 网络具体结构的参数设置。
Results on untrimmed video datasets
(1)comparison with state-of-the-art
(2)self-refining 机制对比实验
self-refining mechanism 具体结构由 self-refining Gumbel softmax sampler 和 incremental confidence learner构成。
将self-refining Gumbel softmax loss和其他三个loss做了对比实验:softmax loss, anticipation loss, memory loss. 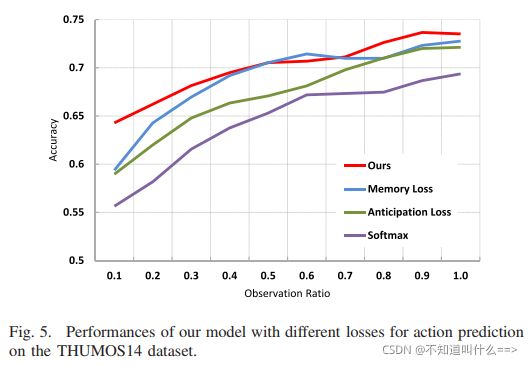
还验证了单调非递减的置信度学习器的影响,即非递减约束。
置信度的增加率与预测准确性呈正相关。预测损失使用的是学习到的置信度信息,而不是时间信息。
(3)Evaluation on the Temporal Hybrid Network
比较了四种时间聚合网络:
(4)Evaluation on SSA
比较了attention操作K的数量、sparsemax、式(17)中惩罚项。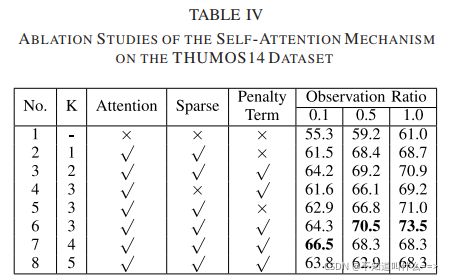
第一行没有attention,第2、5、6行验证了惩罚项的重要性,3、6、7、8行比较了不同的注意力操作次数K。
Results on Trimmed Video Datasets
(1)Comparison With State-of-the-Art Methods
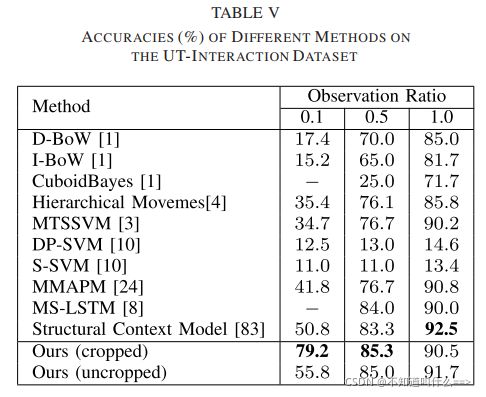

(2)Comparison of Different Features
在UCF101用了三种不同特征进行了实验:2D CNN、two-stream CNN、3D CNN
Conclusion
提出action prediction的核心是产生自我评估(置信度)来判断已有信息是否足以推断出正确的动作标签,并根据自我评估来调整决策,就像人类的元认知过程。提出的SPR-Net有三个模块,增量置信学习器,它可以动态学习用于预测的置信值。同时,时间混合网络学习用于生成动作类别分布的动作表示。自我预测细化机制可以通过对预测置信度和类别分布之间的关系进行建模,具体是由自我细化的 Gumbel softmax 采样器来完成。 此外,我们还构建了一个 Sparse Self-Attention (SSA) 模块,该模块可轻松插入其他网络,以将局部时空特征编码为帧级运动表示。