数据库内核那些事|一文Get PolarDB IMCI如何对半结构化数据进行高效分析
1. 背景
随着应用场景多样化与快速迭代,业务系统常采用半结构化数据类型进行存储与分析。PolarDB作为阿里云自研的新一代云原生HTAP数据库,其列存索引(In Memory Column Index,IMCI)推出完备虚拟列与列式 JSON 等功能,可以快速处理大数据和支持多种数据类型(包括结构化与半结构化数据),并提供高效的数据分析、查询与流计算能力,适用于数据分析、数据仓库与扩展流计算等应用场景。
针对海量半结构化数据计算与分析,本文将以半结构化数据 JSON 为例,首先简述传统数据库与数据仓库的解决方案,然后详细描述 PolarDB IMCI 列式JSON、虚拟列、秒级加减列与表列数扩展等技术点,最后给出 PolarDB IMCI 列式 JSON 实时分析与扩展流计算解决方案。
2. 方案
业务系统采用 JSON 类型主要在于半结构化数据的灵活性,往往也要求高效分析半结构化数据。如此,灵活性与高性能就成为衡量海量半结构化数据分析的解决方案好坏的关键指标。
2.1 传统数据库解决方案
传统关系型数据库(MySQL、PostgreSQL与ClickHouse等)在处理 JSON 数据时往往将原始 JSON 数据编码成二进制数据并存储到表的 JSON 类型列中,查询时使用 JSON 函数对整个 JSON 列数据进行实时解析与计算等。
JSON 作为半结构化数据类型,可以按需增删改 JSON 属性。当业务需求变更时,业务系统只需要针对新 JSON 列数据进行动态增删改相关属性即可,而不需要修改表结构,有效降低维护和管理表结构的成本。但业务查询时需要读取完整 JSON 列数据并进行实时解析,不仅占用大量 IO 资源,而且可能存在重复解析和计算问题。此外也无法针对 JSON 列数据指定字段建立和使用二级索引等。
select product.item->"$.name"
from product, purchase
where product.id = purchase.item->"$.id"
group by product.item->"$.name";传统数据库执行上述 SQL 时,当使用 NestedLoopJoin 算子时,每一product表每一行均需要重复读取purchase表的item整列数据,同时反复解析 JSON 列数据并抽取出指定字段,其查询效率可想而知。
2.2 传统数仓解决方案
数据仓库的处理流程通常包括以下步骤:
1. 数据抽取(Extraction):从各个数据源中抽取需要的数据,包括数据库、文件、Web服务等,并进行清洗、转换和过滤。
2. 数据转换(Transformation):对抽取的数据进行转换,使其符合数据仓库的数据模型和规范。包括数据清洗、数据整合、数据转换、数据增强和数据聚合等操作。
3. 数据加载(Loading):将经过转换的数据加载到数据仓库中,包括维度表和事实表。
4. 数据管理(Management):对数据仓库中的数据进行管理,包括数据备份、数据恢复、数据安全等操作。
5. 数据分析(Analysis):通过数据仓库中的数据进行多维分析,包括查询、报表、数据挖掘等操作。
业务系统的生产数据一般会经过中间ETL任务按需处理后再导入到数据仓库。
在处理 JSON 数据时,为了提高查询性能,数仓往往在 ETL 任务中预先解析 JSON 数据且按需计算出对应值,然后作为表的单独一列插入到表中,即将 JSON 数据一些属性按需处理后构成大宽表。查询时不再需要读取和解析整个 JSON 列数据,直接读取对应普通列即可,节省大量 IO 资源。此外也可以针对该列建立和使用索引,有效提高查询性能。
但当业务需求变更时,业务系统按需增删改 JSON 数据的属性后,数仓需要修改中间 ETL 作业和表结构来适配上游的生产数据,比如重新发布 ETL 作业、DDL 加列或删列等。因此,数据仓库往往需要同时维护 ETL 作业逻辑和业务表结构,而频繁发布 ETL 作业常常会影响上游数据消费和下游结果入仓,且在不支持 INSTANT DDL 时修改大表结构代价相对比较高,容易影响正常查询业务。
总体来说,传统数仓解决方案虽然能够提供高效查询,但缺乏灵活性,维持成本高。
2.3 IMCI 技术方案
在应对海量半结构化数据的分析场景时,传统数据库与数据仓库均无法同时满足查询性能和灵活架构,因此业界迫切需要新解决方案:PolarDB IMCI。
为此,PolarDB IMCI 开发列式JSON、虚拟列、秒级加减列与表列数扩展等一系列相关功能,下面将依次描述各个技术点:
▶︎ 列式JSON
半结构化数据是介于结构化数据和非结构化数据之间的一种数据形式,具有部分结构化的特点,但不像结构化数据那样具有明确的数据模式。半结构化数据可以通过标签、标记、元数据等方式进行描述和组织,但其结构与组织方式也可以随着数据内容的变化而动态调整。半结构化数据通常存在于 Web 页面、XML、JSON、NoSQL数据库等场景中,其灵活性和易扩展性使其成为大数据时代中不可或缺的一部分。
PolarDB MySQL 本身是一个关系型数据库管理系统,其存储的数据通常是结构化数据,但也原生支持存储和查询半结构化数据,如 XML 和 JSON 格式数据。PolarDB IMCI 也全面支持 JSON 数据类型及其列式函数,采用二进制 JSON 格式来存储半结构化数据,支持通过列式 JSON 函数来实现 JSON 文档的解析、查询、修改和删除等操作,与 MySQL 语法完全兼容。
PolarDB IMCI 采用精简二进制方式存储 JSON 列存数据,且使用 RapidJSON 库解析 JSON 数据,处理过程中按需读取数据且利用列存压缩技术等有效减少 IO 量,同时充分利用 SIMD 和向量化及并行等加速运算。
以实际测试数据为例展示列存中 JSON 用法及其行列存性能对比:
1. 创建表并添加 JSON 列及其列索引
create table produce (
id bigint(20) NOT NULL,
attributes json DEFAULT NULL
) comment='columnar=1';2. 使用列式 JSON 函数进行查询
select count(*)
from produce
where attributes->"$.delivery.width" > 10 and attributes->"$.delivery.height" > 10 and attributes->"$.delivery.weight" > 10;列存执行计划:
Project | Exprs: temp_table1.COUNT(0)
HashGroupby | OutputTable(1): temp_table1 | Grouping: None | Output Grouping: None | Aggrs: COUNT(0)
CTableScan | InputTable(0): produce | Pred: ((JSON_EXTRACT(produce.attributes, "$.delivery.width") > "10(json)") AND (JSON_EXTRACT(produce.attributes, "$.delivery.height") > "10(json)") AND (JSON_EXTRACT(produce.attributes, "$.delivery.weight") > "10(json)"))在千万级produce表 PolarDB 行列存时间:

测试实验表明 PolarDB 列存可以高效分析 JSON 数据,接近行存两个数量级。由于数据集与查询模式均不同,线上业务的性能收益可能存在一定差异,需要以实际情况为准。
▶︎ 虚拟列
虚拟列(Virtual Columns)作为一种特殊类型的列,其值不是通过插入或更新的方式进行存储,而是根据表中其他列的值动态计算、合并或者筛选得出。虚拟列可以用于查询和索引,但不能被直接修改或删除。虚拟列提供了一个快速访问和处理数据的方法,而无需在每次查询时重新计算这些数据,因此常用来优化查询和简化操作。
PolarDB IMCI 实现完整虚拟列功能,支持两种 Generated Column:Virtual Generated Column(默认) 与 Stored Generated Column。其中 Virtual 只会将 Generated Column 计算后值持久化到列存,但不会持久化到行存,每次行存读取时会重新实时计算;Stored 则会将 Generated Column 计算后值持久化到行存和列存,但会占用更多磁盘空间。在 PolarDB IMCI 生态中推荐使用默认Virtual Generated Column,在节省磁盘空间同时还有列存高性能。
虚拟列语法:
col_name data_type [GENERATED ALWAYS] AS (expr)
[VIRTUAL | STORED] [NOT NULL | NULL]
[UNIQUE [KEY]] [[PRIMARY] KEY]
[COMMENT 'string']以实际测试数据为例展示列存中虚拟列用法及其行列存性能对比:
1. 创建表并添加虚拟列及其列索引
create table produce (
id bigint(20) NOT NULL,
attributes json DEFAULT NULL,
`delivery_volume` double GENERATED ALWAYS AS (((json_extract(`attributes`,'$.delivery.width') * json_extract(`attributes`,'$.delivery.height')) * json_extract(`attributes`,'$.delivery.weight'))) VIRTUAL
) comment='columnar=1';2.分别使用普通列和虚拟列进行查询
(1) 普通列查询
select count(*)
from produce
where (attributes->"$.delivery.width" * attributes->"$.delivery.height" * attributes->"$.delivery.weight") > 1000;列存执行计划:
Project | Exprs: temp_table1.COUNT(0)
HashGroupby | OutputTable(1): temp_table1 | Grouping: None | Output Grouping: None | Aggrs: COUNT(0)
CTableScan | InputTable(0): produce | Pred: ((CAST JSON_EXTRACT(produce.attributes, "$.delivery.width")/JSON as DOUBLE(38, 31)) * (CAST JSON_EXTRACT(produce.attributes, "$.delivery.height")/JSON as DOUBLE(38, 31)) * (CAST JSON_EXTRACT(produce.attributes, "$.delivery.weight")/JSON as DOUBLE(38, 31)) > 1000.000000)在千万级produce表普通列PolarDB行列存时间:

(2) 虚拟列查询
select count(*)
from produce
where delivery_volume > 1000;列存执行计划:
Project | Exprs: temp_table1.COUNT(0)
HashGroupby | OutputTable(1): temp_table1 | Grouping: None | Output Grouping: None | Aggrs: COUNT(0)
CTableScan | InputTable(0): produce | Pred: (produce.delivery_volume > 1000.000000)在千万级produce表虚拟列PolarDB行列存时间:

测试实验表明PolarDB列存的虚拟列功能可以有效提高查询性能。由于数据集与查询模式均不同,线上业务的性能收益可能存在一定差异,需要以实际情况为准。
总之,PolarDB MySQL的虚拟列是一种灵活且强大的功能,尤其处理半结构化数据(如 JSON 类型数据等)时可以直接将不规则的数据存储为结构化数据,避免中间 ETL 额外处理逻辑,并且可以使用传统的 SQL 查询语言进行查询与分析。虚拟列有助于简化复杂的计算和查询,提高架构灵活性;不仅可以避免行存数据数据冗余,而且在虚拟列上建立列存索引且充分利用列存pruner机制进行过滤,切实提高查询性能。
▶︎ 秒级加减列
上小节展示出 PolarDB IMCI 在处理半结构化数据时高效且灵活虚拟列功能,但虚拟列终究还是表的一列。当半结构化数据因业务需求而增删 JSON 列时,业务表则按需通过 DDL 加列或删列来修改表结构,此时高效增删列就成为必不可少功能。当然也不是每次半结构化数据发生结构变化时均得更改表结构,可以在查询频率不高时直接通过 JSON 列式函数实时计算。尤其在 PolarDB IMCI JSON列存版本实现加持下,大部分情况下实时计算也能满足查询性能。
PolarDB IMCI 实现列存表的秒级加减虚拟列 INSTANT DDL 功能,可以在瞬间完成加减虚拟列,不会阻塞读写,基本不会影响正常查询业务。
秒级加虚拟列功能:
alter table produce add column delivery_volume DOUBLE AS (attributes->"$.delivery.width" * attributes->"$.delivery.height" * attributes->"$.delivery.weight");秒级删虚拟列功能:
alter table produce drop column delivery_volume;▶︎ 列数扩展
当半结构化数据相关属性通过虚拟列转换为大宽表的列时,大宽表的列数会随着半结构化数据属性增加而不断扩大。而原生 MySQL 的有最大列数限制,一般取决于表的存储引擎的限制,比如 InnoDB 存储引擎支持最大列数为 1017 列(约 1K 列)。
对于行存而言,目前表最大列数基本满足绝大多数业务需求。设计关系型数据库表结构时一般尽量避免使用大宽表,因为过多的列往往加重 IO 和内存负担而影响性能,比如即使只需要少部分列数据时仍然要读取整个行而导致大量无效 IO;一般会考虑通过拆分表或使用关联表等方式来优化表结构。但对于列存来说大宽表反而成为查询利器,避免表关联;由于列存是按列进行存储,有更好压缩效果,且读取指定列时只需要读取对应列即可,有效减少 IO 量。
PolarDB IMCI 处理半结构化数据时往往会将半结构化数据中一些属性按需转换为表的单独虚拟列,若属性数目过多时就可能突破表的目前最大列数限制。因此 PolarDB IMCI 在原生 MySQL 基础上对 InnoDB 和 列存表的最大列数进行扩展,目前支持最大列数 4089 列(约 4K 列)。
3. 实时分析
针对半结构化数据分析,PolarDB IMCI 实现列式 JSON 与列存虚拟列等技术,本小节将以GitHub实时事件数据(2023年7月份)来验证 PolarDB IMCI JSON 实时数据分析能力。
GitHub实时事件 JSON 数据可以从 GH Archive 获取,如 wget 下载2023年7月份每个小时的数据;下载后解析并插入github_events表中。
根据GitHub event types定义github_events表:
create table github_events (id bigint, type varchar(16), public bit, payload json, repo json, actor json, org json, created_at datetime);从Everything You Always Wanted To Know About GitHub选择并改写出两条测试 SQL:
查询一周内最流行编程语言:
SELECT
repo_language AS language,
count(*) AS total
FROM
github_events
WHERE
created_at >= "2023-07-25 00:00:00"
AND created_at <= "2023-07-31 23:59:59"
AND repo_language IS NOT NULL
GROUP BY
repo_language
ORDER BY
total DESC
LIMIT 10;给 linux 仓库所有关注者按 star 数进行排名:
SELECT repo_name, count(*) AS stars
FROM github_events
WHERE (type = 'WatchEvent') AND (actor_login IN
(
SELECT actor_login
FROM github_events
WHERE (type = 'WatchEvent') AND (repo_name IN ('torvalds/linux')) AND created_at >= "2023-07-31 00:00:00" AND created_at <= "2023-07-31 23:59:59"
)) AND (repo_name NOT IN ('torvalds/linux')) AND created_at >= "2023-07-31 00:00:00" AND created_at <= "2023-07-31 23:59:59"
GROUP BY repo_name
ORDER BY stars DESC
LIMIT 10;创建github_events表列索引,并结合上述SQL给其添加actor_login、repo_name与 repo_language等虚拟列。
alter table github_events add column actor_login varchar(256) generated always as (json_unquote(json_extract(`actor`,'$.login'))) virtual, add column repo_name varchar(256) generated always as (json_unquote(json_extract(`repo`,'$.name'))) virtual, add column repo_language varchar(32) generated always as (json_unquote(json_extract(`payload`,'$.pull_request.base.repo.language'))) virtual, comment 'columnar=1';配置行存缓存为 500G,列存缓存为 128G,在热数据情况下测试结果如下:

如上表所见,PolarDB IMCI列式JSON实时分析性能远高于行存,可以有效应对海量半结构化数据的分析场景。
4. 扩展流计算
结合上述列式JSON、虚拟列、秒级加减列与列数扩展等一系列新功能,PolarDB IMCI 提供出一套基于海量半结构化数据的分析场景的自动化解决方案:扩展流计算。
流计算作为一种实时数据处理技术,主要是基于连续的数据流进行实时计算与分析。而扩展流计算可以理解为一种轻量级的流计算,其主要关注于快速处理数据流并提供实时的计算结果,同时尽可能地减少计算资源使用和降低系统复杂度。与传统的流计算系统相比,扩展流计算更加注重轻量级、快速响应与自动化程度高等方面的特点。
PolarDB IMCI 扩展流计算主要是通过 SQL 语句在表结构中用计算表达式或函数来定义数据流处理逻辑并记录为虚拟列,然后扩展流计算框架会自动根据业务数据流实时计算出结果并持久化到列存表中,查询时则应用列存索引快速读取结果值。整个扩展流计算流程均已内置到 PolarDB IMCI,用户只需要通过 SQL DDL 来定义不同数据流处理逻辑(即虚拟列)即可;当业务需求发生变化时同样也只需要通过 SQL DDL 来增加改虚拟列。
具体到海量半结构化数据的分析场景,用户可以根据业务需求用 JSON 函数和 JSON 列数据属性定义虚拟列(即数据流处理逻辑),并给该虚拟列添加列索引即可,随后业务持续的数据流实时计算和存储将由 PolarDB IMCI 自动完成,不断更新大宽表。业务查询时可以直接使用指定虚拟列,不但可以应用列存索引而且还能避免重新读取和解析完整 JSON 列数据等,有效提高查询效率。即使查询时直接使用 JSON 函数方式,PolarDB 优化器也会根据 JSON 函数和 JSON 列来查询是否存在匹配的虚拟列,若匹配则会优先选择该虚拟列以提高查询性能。
当业务需求变更时,业务系统按需增删改 JSON 列数据属性后,用户只需使用 INSTANT DDL 来秒级加减列即可,不需要类似传统数仓那样额外维护 ETL 作业逻辑,同时秒级加减列功能可以瞬间完成表结构更改。不仅可以灵活应对业务需求变化,基本没有额外维持成本,也不会影响正常业务。若新需求的查询频率不高则可以不更改表结构,查询时可以直接用列存版本 JSON 函数实时解析,也能够满足大部分业务需求。
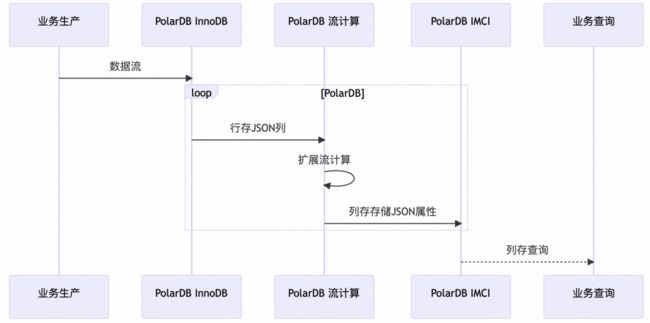
总之,应对海量半结构化数据的分析场景时,PolarDB IMCI扩展流计算具有传统数据库的灵活性与数据仓库的高性能。
5. 案例
5.1 视频平台
某视频是中国最受欢迎的在线视频平台之一,提供电影、电视剧与综艺节目及直播等视频或功能,用户可以通过付费会员获得更好的观影体验。
在海量会员基础上,视频平台每天会员交易数据量迅速膨胀,其会员交易业务的数据独立为实时表,主要用于业务补偿与校验、实时监控订单扭转状态、自动补单与发送权益等,实现无人工处理,自动化处理权益延时到账等。
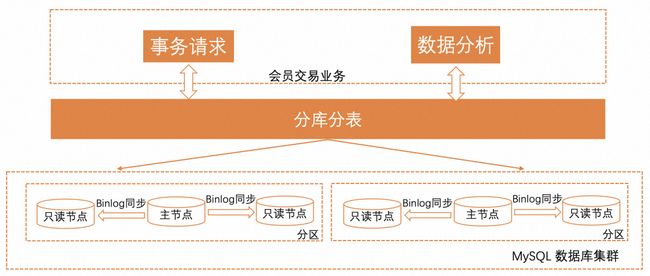
会员交易业务原数据库系统采用的MySQL分库分表方案,每一库表基于MySQL集群一写多读部署方案,通过增加分区数和只读节点的方式扩展数据库集群来应对业务发展需求,节点间采用Binlog同步。为了应对快速迭代,交易业务大量采用的半结构化JSON类型。随着业务快速发展,现有数据库架构难于支撑大表高并发JSON查询,只能通过不断增加数据库和分区数来应对,因此不仅运维复杂和影响业务,其成本也逐步增长。
简化运维和降本增效成为该视频平台会员交易业务数据库新架构的主要目标。新数据库架构采用PolarDB HTAP一体化解决方案,充分利用实时分析列存技术来提升海量JSON数据分析性能,同时有效简化运维。

5.2 金融电商平台
某金融电商平台是一家总部位于新加坡的金融科技公司,在东南亚地区提供消费金融服务,目前已拥有数百万用户,并且已经成为东南亚领先的消费金融服务提供商之一。
该平台的订单业务系统主要分为事务处理与数据分析两大类,业务事务系统大量采用 JSON 数据来存储各类业务属性,而业务分析系统则需要计算与分析大量业务属性。
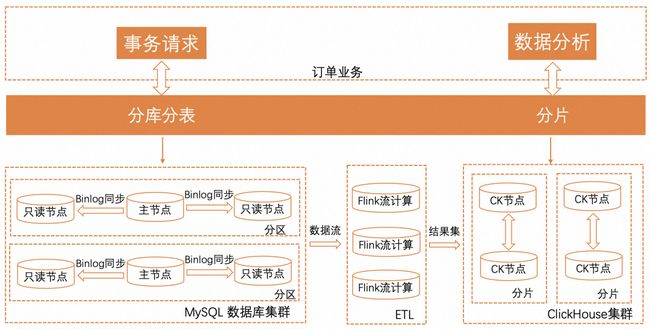
订单业务原数据库系统主要采用的 MySQL 集群处理业务事务,用 ClickHouse 集群进行业务分析,Apache Flink 用于订阅 MySQL 数据流并将 JSON 数据按需转换为结构化数据进而构造出大宽表,再实时插入到 ClickHouse 集群。由于现有数据库架构复杂性,业务经常遇到中间链接丢失数据、分析实时性不高与查询性能不佳及运维复杂等。尤其因业务需求更改而增删改 JSON 属性时,数据库业务需要不断修改 Flink 处理逻辑与更改 ClickHouse 表结构,而 ClickHouse 无法做到秒级加减列,在修改大表时不仅耗时长且影响查询性能等。随着业务快速发展,系统稳定性、简化运维、分析性能与节约成本成为架构师的当务之急。
具备一体化的实时事务处理和实时数据分析 PolarDB HTAP 云原生数据库成为不二之选。新数据库方案具备极简架构,由 MySQL、DTS、Flink 与 ClickHouse 等多套系统简化为一套 PolarDB。新方案利用 PolarDB IMCI 扩展流计算代替 Flink 实现半结构化数据到结构化数据的自动转换、秒级加减列功能简化运维、列数扩展支撑业务极速发展与列存提升分析性能等。