【数据采集与预处理】数据传输工具Sqoop
目录
一、Sqoop简介
二、Sqoop原理
三、Sqoop安装配置
(一)下载Sqoop安装包并解压
(二)修改配置文件
(三)拷贝JDBC驱动
(四)验证Sqoop
(五)测试Sqoop是否能够成功连接数据库
四、导入数据
(一)RDBMS到HDFS
(二)RDBMS到HBase
(三)RDBMS到Hive
五、导出数据
HDFS/Hive到RDBMS
六、Sqoop常用命令及参数
(一)常用命令列举
(二)公用参数
一、Sqoop简介
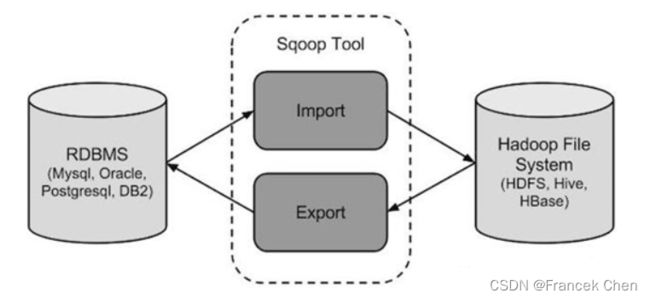
Sqoop 是一款开源的工具,主要用于在 Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL,Oracle,Postgres 等)中的数据导进到 Hadoop 的 HDFS 中,也可以将 HDFS 的数据导进到关系型数据库中。
Sqoop 项目开始于 2009 年,最早是作为 Hadoop 的一个第三方模块存在,后来为了让使用者能够快速部署,也为了让开发人员能够更快速的迭代开发,Sqoop 独立成为一个 Apache 项目。
Sqoop2 的最新版本是 1.99.7。请注意,2 与 1 不兼容,且特征不完整,它并不打算用于生产部署。
二、Sqoop原理
将导入或导出命令翻译成 mapreduce 程序来实现。
在翻译出的 mapreduce 中主要是对 inputformat 和 outputformat 进行定制。

三、Sqoop安装配置
安装 Sqoop 的前提是已经具备 Java 和 Hadoop 的环境。
我的环境:JDK1.8;Hadoop3.1.3
(一)下载Sqoop安装包并解压
下载地址:https://archive.apache.org/dist/sqoop/

并上传到虚拟机中。
解压缩到“/usr/local”目录下,执行如下命令:
[root@bigdata local]# cd /usr/local/uploads/
[root@bigdata uploads]# tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /usr/local
[root@bigdata local]# mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz sqoop
(二)修改配置文件
1、复制重命名配置文件
Sqoop的配置文件与大多数大数据框架类似,在sqoop根目录下的conf目录中。
[root@bigdata sqoop]# cd /usr/local/sqoop/conf
[root@bigdata conf]# cp sqoop-env-template.sh sqoop-env.sh
2、修改配置文件
[root@bigdata conf]# vi sqoop-env.sh
export HADOOP_COMMON_HOME=/usr/local/servers/hadoop
export HADOOP_MAPRED_HOME=/usr/local/servers/hadoop
export HIVE_HOME=/usr/local/hive
export ZOOKEEPER_HOME=/usr/local/servers/zookeeper
export ZOOCFGDIR=/usr/local/servers/zookeeper
export HBASE_HOME=/usr/local/servers/hbase
(三)拷贝JDBC驱动
拷贝jdbc驱动到sqoop的lib目录下:
[root@bigdata lib]# cp /usr/local/uploads/mysql-connector-java-5.1.40-bin.jar .
(四)验证Sqoop
我们可以通过某一个command来验证sqoop配置是否正确:
[root@bigdata sqoop]# bin/sqoop help
(五)测试Sqoop是否能够成功连接数据库
[root@bigdata sqoop]# bin/sqoop list-databases --connect jdbc:mysql://bigdata:3306?useSSL=false --username root --password MYsql123!
连接成功结果:

若上面命令中不加“?useSSL=false”,则可能会报如下错误:

可以将“useSSL=false”添加到连接字符串中以禁用SSL连接。
提示:若测试链接时出现如下类似的报错:

原因:集群没有安装HCatalog 和Accumulo
解决方法:修改sqoop安装目录bin文件夹下的configure-sqoop文件,找到如下位置并注释:

四、导入数据
在Sqoop中,“导入”概念指:从非大数据集群(RDBMS)向大数据集群(HDFS,Hive,HBase)中传输数据,叫做:导入,即使用import关键字。
(一)RDBMS到HDFS
1、确定Mysql服务开启正常
[root@bigdata zhc]# systemctl start mysqld.service
[root@bigdata zhc]# systemctl status mysqld.service
[root@bigdata zhc]# mysql -u root -p
2、在Mysql中新建一张表并插入一些数据
mysql> create database company;
mysql> use company;
mysql> create table company.staff(id int(4) primary key not null auto_increment, name varchar(255), sex varchar(255));
mysql> insert into company.staff(name, sex) values('Thomas', 'Male');
mysql> insert into company.staff(name, sex) values('Catalina','FeMale');

3、启动Hadoop的组件
[root@bigdata sqoop]# start-all.sh

4、导入数据
[root@bigdata sqoop]# bin/sqoop import \
> --connect jdbc:mysql://bigdata:3306/company?useSSL=false \
> --username root \
> --password MYsql123! \
> --table staff \
> --target-dir /user/company \
> --delete-target-dir \
> --num-mappers 1 \
> --fields-terminated-by "\t"

查看并验证结果:
[root@bigdata servers]# hdfs dfs -ls /user/company/
[root@bigdata servers]# hdfs dfs -cat /user/company/part-m-00000

(二)RDBMS到HBase
[root@bigdata sqoop]# bin/sqoop import \
> --connect jdbc:mysql://bigdata:3306/company?useSSL=false \
> --username root \
> --password MYsql123! \
> --table staff \
> --columns "id,name,sex" \
> --column-family "info" \
> --hbase-create-table \
> --hbase-row-key "id" \
> --hbase-table "hbase_company" \
> --num-mappers 1 \
> --split-by id
提示:sqoop1.4.6 只支持 HBase1.0.1 之前的版本的自动创建 HBase 表的功能。
解决方案:手动创建 HBase 表
hbase:001:0> create 'hbase_staff,'info'在 HBase 中 scan 这张表得到如下内容:
hbase:002:0> scan 'hbase_staff'(三)RDBMS到Hive
[root@bigdata sqoop]# bin/sqoop import \
> --connect jdbc:mysql://bigdata:3306/company?useSSL=false \
> --username root \
> --password MYsql123! \
> --table staff \
> --num-mappers 1 \
> --hive-import \
> --fields-terminated-by "\t" \
> --hive-overwrite \
> --hive-table staff_hive
提示:该过程分为两步,第一步将数据导入到 HDFS,第二步将导入到 HDFS 的数据迁移到
Hive 仓库,第一步默认的临时目录是/user/atguigu/表名。
五、导出数据
在Sqoop中,“导出”概念指:从大数据集群(HDFS,HIVE,HBASE)向非大数据集群(RDBMS)中传输数据,叫做:导出,即使用export关键字。
HDFS/Hive到RDBMS
1、先登录Mysql
mysql> use company;
mysql> show tables;
mysql> truncate table staff; # 存在数据先把数据清空2、运行脚本
[root@bigdata sqoop]# bin/sqoop export \
> --connect jdbc:mysql://bigdata:3306/company?useSSL=false \
> --username root \
> --password MYsql123! \
> --table staff \
> --num-mappers 1 \
> --export-dir /user/hive/warehouse/staff_hive \
> --input-fields-terminated-by "\t"
六、Sqoop常用命令及参数
(一)常用命令列举
| 序号 | 命令 | 类 | 说明 |
|---|---|---|---|
| 1 | import | ImportTool | 将数据导入到集群 |
| 2 | export | ExportTool | 将集群数据导出 |
| 3 | codegen | CodeGenTool | 获取数据库中某张表数据生成Java并打包Jar |
| 4 | create-hive-table | CreateHiveTableTool | 创建Hive表 |
| 5 | eval | EvalSqlTool | 查看SQL执行结果 |
| 6 | import-all-tables | ImportAllTablesTool | 导入某个数据库下所有表到HDFS中 |
| 7 | job | JobTool | 用来生成一个sqoop的任务,生成后,该任务并不执行,除非使用命令执行该任务。 |
| 8 | list-databases | ListDatabasesTool | 列出所有数据库名 |
| 9 | list-tables | ListTablesTool | 列出某个数据库下所有表 |
| 10 | merge | MergeTool | 将HDFS中不同目录下面的数据合在一起,并存放在指定的目录中 |
| 11 | metastore | MetastoreTool | 记录sqoop job的元数据信息,如果不启动metastore实例,则默认的元数据存储目 录为:~/.sqoop,如果要更改存储目录,可以在配置文件sqoop-site.xml中进行更改。 |
| 12 | help | HelpTool | 打印sqoop帮助信息 |
| 13 | version | VersionTool | 打印sqoop版本信息 |
(二)公用参数
1、公用参数:数据库连接
| 序号 | 参数 | 说明 |
|---|---|---|
| 1 | –connect | 连接关系型数据库的URL |
| 2 | –connection-manager | 指定要使用的连接管理类 |
| 3 | –driver | Hadoop根目录 |
| 4 | –help | 打印帮助信息 |
| 5 | –password | 连接数据库的密码 |
| 6 | –username | 连接数据库的用户名 |
| 7 | –verbose | 在控制台打印出详细信息 |
2、公用参数:import
| 序号 | 参数 | 说明 |
|---|---|---|
| 1 | –enclosed-by | 给字段值前加上指定的字符 |
| 2 | –escaped-by | 对字段中的双引号加转义符 |
| 3 | –fields-terminated-by | 设定每个字段是以什么符号作为结束,默认为逗号 |
| 4 | –lines-terminated-by | 设定每行记录之间的分隔符,默认是\n |
| 5 | –mysql-delimiters | Mysql默认的分隔符设置,字段之间以逗号分隔,行之间以\n分隔,默认转义符是\,字段值以单引号包裹。 |
| 6 | –optionally-enclosed-by | 给带有双引号或单引号的字段值前后加上指定字符。 |
3、公用参数:export
| 序号 | 参数 | 说明 |
|---|---|---|
| 1 | –input-enclosed-by | 对字段值前后加上指定字符 |
| 2 | –input-escaped-by | 对含有转移符的字段做转义处理 |
| 3 | –input-fields-terminated-by | 字段之间的分隔符 |
| 4 | –input-lines-terminated-by | 行之间的分隔符 |
| 5 | –mysql-delimiters | Mysql默认的分隔符设置,字段之间以逗号分隔,行之间以\n分隔,默认转义符是\,字段值以单引号包裹。 |
4、公用参数:hive
| 序号 | 参数 | 说明 |
|---|---|---|
| 1 | –hive-delims-replacement | 用自定义的字符串替换掉数据中的\r\n和\013 \010等字符 |
| 2 | –hive-drop-import-delims | 在导入数据到hive时,去掉数据中的\r\n\013\010这样的字符 |
| 3 | –map-column-hive | 生成hive表时,可以更改生成字段的数据类型 |
| 4 | –hive-partition-key | 创建分区,后面直接跟分区名,分区字段的默认类型为string |
| 5 | –hive-partition-value | 导入数据时,指定某个分区的值 |
| 6 | –hive-home | hive的安装目录,可以通过该参数覆盖之前默认配置的目录 |
| 7 | –hive-import | 将数据从关系数据库中导入到hive表中 |
| 8 | –hive-overwrite | 覆盖掉在hive表中已经存在的数据 |
| 9 | –create-hive-table | 默认是false,即,如果目标表已经存在了,那么创建任务失败。 |
| 10 | –hive-table | 后面接要创建的hive表,默认使用MySQL的表名 |
| 11 | –table | 指定关系数据库的表名 |