ES自动补全
安装IK分词器
要实现根据字母做补全,就必须对文档按照拼音分词。在GitHub上恰好有elasticsearch的拼音分词插件。地址:GitHub - medcl/elasticsearch-analysis-pinyin: This Pinyin Analysis plugin is used to do conversion between Chinese characters and Pinyin.
或者:
链接:https://pan.baidu.com/s/1IH6YEaa0ol039plev1wnag?pwd=dvl5
提取码:dvl5
安装方式与IK分词器一样,分三步:
①解压,命名为py
②上传到虚拟机中,elasticsearch的plugin目录
③重启elasticsearch④测试
详细安装步骤可以参考IK分词器的安装过程:怎么安装IK分词器-CSDN博客

测试用法如下:

结果:

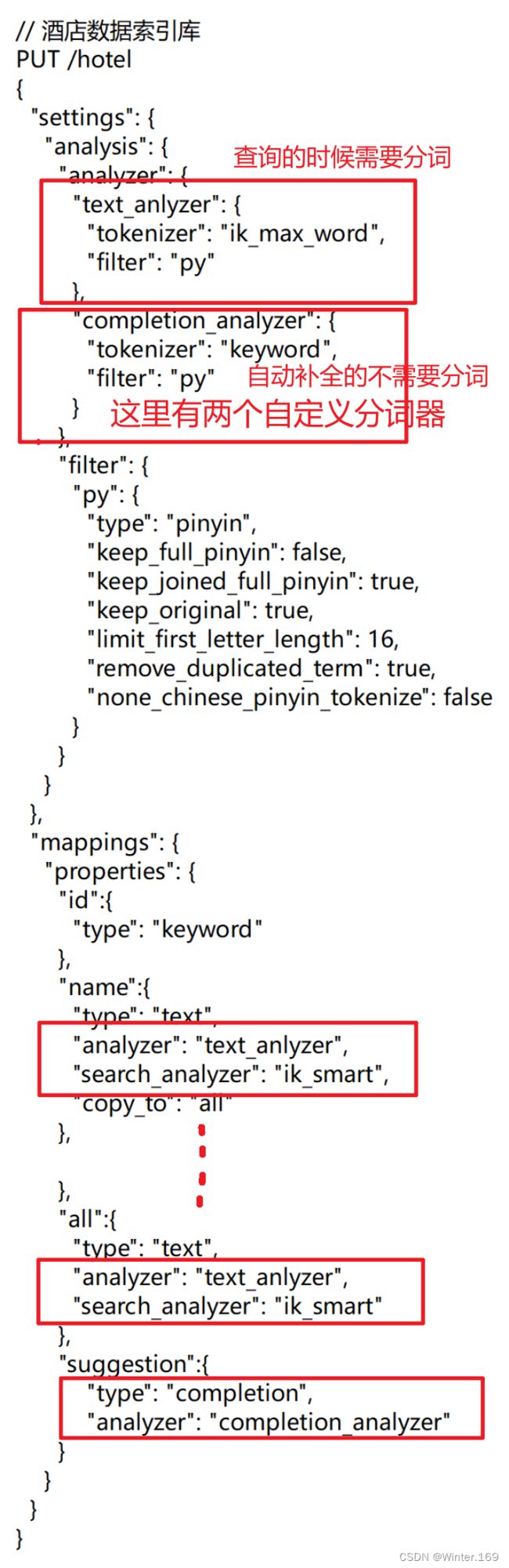
自定义分词器
默认的拼音分词器会将每个汉字单独分为拼音,而我们希望的是每个词条形成一组拼音,需要对拼音分词器做个性化定制,形成自定义分词器。
elasticsearch中分词器(analyzer)的组成包含三部分:
-
character filters:在tokenizer之前对文本进行处理。例如删除字符、替换字符
-
tokenizer:将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词;还有ik_smart
-
tokenizer filter:将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等
文档分词时会依次由这三部分来处理文档:



PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_smart"
},
"id":{
"type": "keyword"
}
}
}
}
DELETE /test
#测试分词器:
POST /test/_doc/1
{
"id": 1,
"name": "狮子"
}
POST /test/_doc/2
{
"id": 2,
"name": "虱子"
}
GET /test/_search
{
"query": {
"match": {
"name": "掉入狮子笼咋办"
}
}
}
自动补全查询
elasticsearch提供了Completion Suggester查询来实现自动补全功能。这个查询会匹配以用户输入内容开头的词条并返回。为了提高补全查询的效率,对于文档中字段的类型有一些约束:
-
参与补全查询的字段必须是completion类型。
-
字段的内容一般是用来补全的多个词条形成的数组。
比如,一个这样的索引库:
#创建一个索引库
PUT test2
{
"mappings": {
"properties": {
"title":{
"type": "completion"
}
}
}
}
#添加3个数据
POST test2/_doc
{
"title": ["Sony", "WH-1000XM3"]
}
POST test2/_doc
{
"title": ["SK-II", "PITERA"]
}
POST test2/_doc
{
"title": ["Nintendo", "switch"]
}
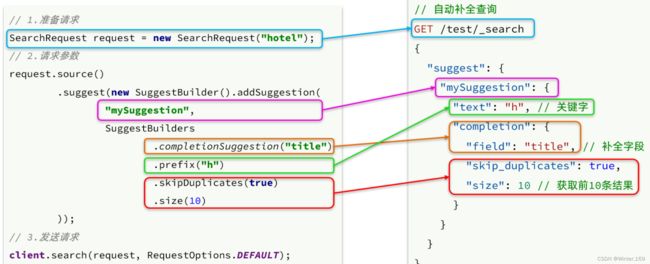
#自动补全查询
POST /test2/_search
{
"suggest": {
"title_suggest": {
"text": "s",
"completion": {
"field": "title",
"skip_duplicates": true,
"size": 10
}
}
}
}
自动补全查询的JavaAPI
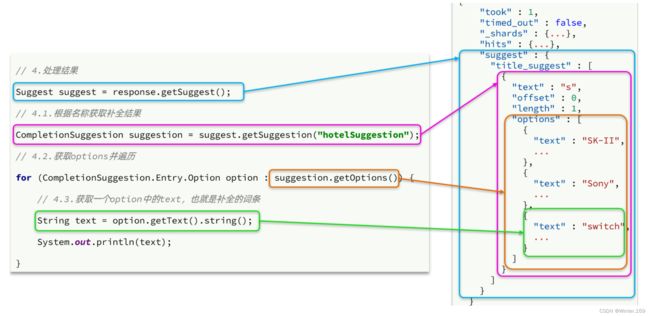
而自动补全的结果也比较特殊,解析的代码如下:
//自动补全
public List getSuggestions(String prefix) {
try {
//1.准备Request
SearchRequest request = new SearchRequest("hotel");
//2.准备DSL
request.source().suggest(new SuggestBuilder().addSuggestion(
"mySuggestion",
SuggestBuilders.completionSuggestion("suggestion")
.prefix(prefix)
.skipDuplicates(true)
.size(10)
));
//3,发起请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4,解析结果
Suggest suggest = response.getSuggest();
CompletionSuggestion completionSuggestion=suggest.getSuggestion("mySuggestion");
//获取options并遍历
List result =new ArrayList<>();
for (CompletionSuggestion.Entry.Option option : completionSuggestion.getOptions()) {
//获取一个option中的text,也就是补全的词条
String string = option.getText().string();
result.add(string);
}
return result;
} catch (IOException e) {
throw new RuntimeException(e);
}
}