【Redis】九种数据类型及应用场景

前言
Redis是一个开源的,基于内存的数据结构存储系统,可以用作数据库、缓存和消息中间件。它支持多种数据类型,包括字符串(String)、哈希表(Hash)、列表(List)、集合(Set)、有序集合(ZSet )、地理空间(Geo)、位图(Bitmaps)、基数统计(HyperLogLog)、流信息(Streams)。下面是这些类型的详细介绍以及它们的操作和应用场景。
一、字符串(String)
1. 简介
-
String 类型是 Redis 最基本的数据类型,一个 key 对应一个 value。
-
String 类型是二进制安全的,意思是 redis 的 string 可以包含任何数据。比如jpg图片或者序列化的对象。
-
默认情况下,单个 Redis 字符串的最大值为 512 MB。
2. 常用命令

3. 使用场景
String类型一般用于缓存、限流、计数器、分布式锁、分布式Session。
4. 使用例子
1). 缓存token
redisTemplate.opsForValue().set("ZHANGSAN", "92c48b47-573f-455c-8f37-3746f85bf6a5", 30, TimeUnit.MINUTES);2). 计数器
redisTemplate.opsForValue().increment("views_num", 1);二、哈希表(Hash)
1. 简介
Redis Hash是一个string类型的field和value的映射表,hash特别适用于存储对象。每个hash可以存储232 - 1(42亿左右)键值对。可以看成KEY和VALUE的MAP容器。
2. 常用命令

3. 使用场景
通常用来存储对象型数据,如用户信息的对象数据 人(属性,值,属性,值)。
4. 使用例子
//设置哈希字段的值
redisTemplate.opsForHash().put("myhash", "field1", "value1");
//设置多个哈希字段的值
Map map = new HashMap<>();
map.put("field1", "value1");
map.put("field2", "value2");
redisTemplate.opsForHash().putAll("myhash", map);
//获取哈希字段的值
redisTemplate.opsForHash().get("myhash", "field1");
//获取多个哈希字段的值
redisTemplate.opsForHash().multiGet("myhash", Arrays.asList("field1", "field2"));
//判断哈希中是否存在指定的字段
redisTemplate.opsForHash().hasKey("myhash", "field1");
//获取哈希的所有字段
redisTemplate.opsForHash().keys("myhash");
//获取哈希的所有值
redisTemplate.opsForHash().values("myhash");
//获取哈希的所有字段和对应的值
redisTemplate.opsForHash().entries("myhash");
//将指定字段的值增加指定步长
redisTemplate.opsForHash().increment("myhash", "field1", 5);
//删除指定的字段
redisTemplate.opsForHash().delete("myhash", "field1"); 三、列表(List)
1. 简介
Redis List是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)一个列表最多可以包含 2^32^ - 1 个元素 (4294967295, 每个列表超过40亿个元素)。
2. 常用命令

3. 使用场景
List类型一般用于简单队列、列表显示、关注列表、粉丝列表、留言评价…分页、热点新闻等。
4. 使用例子
//从列表的左侧插入一个或多个元素
redisTemplate.opsForList().leftPush("mylist", "value1");
//从列表的右侧插入一个或多个元素
redisTemplate.opsForList().rightPush("mylist", "value1");
//移除并返回列表最左侧的元素
redisTemplate.opsForList().leftPop("mylist");
//移除并返回列表最右侧的元素
redisTemplate.opsForList().rightPop("mylist");
//获取列表指定范围内的元素
redisTemplate.opsForList().range("mylist", 0, -1);
//获取列表中指定索引处的元素
redisTemplate.opsForList().index("mylist", 1);
//获取列表的长度
redisTemplate.opsForList().size("mylist");
//截取指定范围内的元素,保留指定范围内的元素,其它元素将被删除
redisTemplate.opsForList().trim("mylist", 0, 2);
//移除列表中指定数量的元素
redisTemplate.opsForList().remove("mylist", 2, "value1");
//设置列表中指定索引处的元素的值
redisTemplate.opsForList().set("mylist", 2, "newvalue");四、集合(Set)
1. 简介
Redis Set 是 String 类型的无序集合。集合中成员是唯一的,这就意味着集合中不能出现重复的数据。Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。集合中最大的成员数为 2^32^ - 1 (4294967295)。
2. 常用命令

3. 使用场景
-
Set类型一般用于赞、踩、标签、好友关系等;
-
利用唯一性统计独立IP等;
-
利用对交集、并集、差集的计算对数据进行过滤处理,如共同好友、推荐信息的数据过滤等。
4. 使用例子
//向集合中添加一个或多个元素
redisTemplate.opsForSet().add("myset", "value1", "value2", "value3");
//获取集合中的所有成员
redisTemplate.opsForSet().members("myset");
//获取集合的大小
redisTemplate.opsForSet().size("myset");
//判断元素是否是集合的成员
redisTemplate.opsForSet().isMember("myset", "value1");
//获取集合中的随机元素
redisTemplate.opsForSet().randomMember("myset");
//弹出并返回集合中的一个随机元素
redisTemplate.opsForSet().pop("myset");
//从集合中移除一个或多个元素
redisTemplate.opsForSet().remove("myset", "value1", "value2");
//计算多个集合的交集,并返回结果集合
redisTemplate.opsForSet().intersect("set1", "set2");
//计算多个集合的并集,并返回结果集合
redisTemplate.opsForSet().union("set1", "set2");
//计算两个集合的差集,并返回结果集合
redisTemplate.opsForSet().difference("set1", "set2");五、有序集合(ZSet )
1. 简介
Redis 有序集合和集合一样也是string类型元素的集合且不允许重复的成员。不同的是每个元素都会关联一个==double类型的分数==。redis正是通过分数来为集合中的成员进行从小到大的排序。有序集合的成员是唯一的,但分数(score)却可以重复。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。集合中最大的成员数为 2^32^ - 1 (4294967295)。
2. 常用命令

3. 使用场景
Zset类型一般用于排行榜、商品进行排序显示等。
4. 使用例子
//向有序集合中添加一个成员,同时指定该成员的分数
redisTemplate.opsForZSet().add("myzset", "member1", 0.5);
redisTemplate.opsForZSet().add("myzset", "member2", 0.8);
redisTemplate.opsForZSet().add("myzset", "member3", 1.2);
//获取有序集合中指定范围内的成员集合(按分数从低到高排序)
redisTemplate.opsForZSet().range("myzset", 0, -1);
//获取有序集合中指定范围内的成员集合(按分数从高到低排序)
redisTemplate.opsForZSet().reverseRange("myzset", 0, -1);
//获取有序集合中的成员数量
redisTemplate.opsForZSet().zCard("myzset");
//获取有序集合中指定成员的分数
redisTemplate.opsForZSet().score("myzset", "member1");
//从有序集合中移除指定的成员
redisTemplate.opsForZSet().remove("myzset", "member1", "member2");
//统计有序集合中指定分数范围内的成员数量
redisTemplate.opsForZSet().count("myzset", 1.0, 2.0);
//将指定成员的分数增加指定数值
redisTemplate.opsForZSet().incrementScore("myzset", "member1", 0.2);
//获取指定成员在有序集合中的排名(按分数从低到高排序)
redisTemplate.opsForZSet().rank("myzset", "member1");
//获取指定成员在有序集合中的排名(按分数从高到低排序)
redisTemplate.opsForZSet().reverseRank("myzset", "member1");六、地理空间(GEO)
1. 简介
Redis 3.2 中增加了对GEO类型的支持。GEO,Geographic,地理信息的缩写。该类型,就是元素的2维坐标,在地图上就是经纬度。redis基于该类型,提供了经纬度设置,查询,范围查询,距离查询,经纬度Hash等常见操作。
2. 常用命令

3. 使用场景
地理空间索引,附件商家、酒店等
4. 使用例子
//添加一个或多个地理位置到指定的Geo键中
redisTemplate.opsForGeo().add("mygeo", new Point(116.397128, 39.916527), "Beijing");
redisTemplate.opsForGeo().add("mygeo", new Point(121.472641, 31.231707), "Shanghai");
redisTemplate.opsForGeo().add("mygeo", new Point(113.264435, 23.129163), "Guangzhou");
//获取指定成员的地理位置
redisTemplate.opsForGeo().position("mygeo", "Beijing");
//计算两个成员之间的距离(默认以米为单位)
redisTemplate.opsForGeo().distance("mygeo", "Beijing", "Shanghai");
//获取指定成员的Geohash值
redisTemplate.opsForGeo().hash("mygeo", "Beijing");
//根据给定的中心点,返回与中心点距离在指定范围内的成员(按距离由近到远排序)
Circle circle = new Circle(new Point(116.397128, 39.916527), new Distance(200, Metrics.KILOMETERS));
redisTemplate.opsForGeo().radius("mygeo", circle);
//根据给定的成员,返回与该成员距离在指定范围内的其他成员(按距离由近到远排序)
redisTemplate.opsForGeo().radiusByMember("mygeo", "Beijing", new Distance(200, Metrics.KILOMETERS));
//从指定的Geo键中移除一个或多个成员
redisTemplate.opsForGeo().remove("mygeo", "Beijing", "Shanghai");
七、位图(Bitmaps)
1. 简介
Redis 6 中提供了 Bitmaps 这个“数据类型”可以实现对位的操作。
Bitmaps本身不是一种数据类型,实际上它就是字符串(key-value),但是它可以对字符串的位进行操作。
由于字符串是二进制安全的,最大长度是512MB,转换成位可以设置 2^32不同的位。位图的最大优点之一,存储信息时可以节省大量空间。
Bitmaps单独提供了一套命令,所以在Redis中使用Bitmaps和使用字符串的方法不太相同。可以把Bitmaps想象成一个以位为单位的数组, 数组的每个单元只能存储0和1, 数组的下标在Bitmaps中叫做偏移量。
2. 常用命令

3. 使用场景
Bitmaps一般用于记录状态,比如登录状态、签到等,并可以对状态进行统计。
4. 使用例子
//给指定key的值的第offset赋值val
redisTemplate.opsForValue().setBit("key",1,false);
//获取指定key的第offset位
redisTemplate.opsForValue().getBit("key",1);
//获取多个数据
BitFieldSubCommands command = BitFieldSubCommands.create()
.get(BitFieldSubCommands.BitFieldType.unsigned(1)).valueAt(1)
.get(BitFieldSubCommands.BitFieldType.unsigned(1)).valueAt(2)
.get(BitFieldSubCommands.BitFieldType.unsigned(1)).valueAt(3)
.get(BitFieldSubCommands.BitFieldType.unsigned(1)).valueAt(4)
.get(BitFieldSubCommands.BitFieldType.unsigned(1)).valueAt(5)
.get(BitFieldSubCommands.BitFieldType.unsigned(1)).valueAt(6)
.get(BitFieldSubCommands.BitFieldType.unsigned(1)).valueAt(7);
redisTemplate.opsForValue().bitField("key",command);八、基数统计(HyperLogLog)
1. 简介
属于一种概率算法,(LC,LLC,HLL)三种越来越节省内存,降低误差率。
HyperLogLog优点,在输入元素的数量或者体积非常大时。计算基数所需的空间总是固定很小的。每个HyperLogLog的键只需要花费12KB内存,在标准误差0.81%的前提下,就可以计算接近2^64个不同的基数。
用bitmap存储1一亿个统计数据大概需要12M内存;而在HLL中,只需要不到1K内存就能做到。
HyperLogLog只会根据输入元素来计算基数,而不会存储元素本身,所以不能返回各个元素。
HLL比 bitmap更节省内存,但有一定误差( 标准误差 0.81%)
2. 常用命令
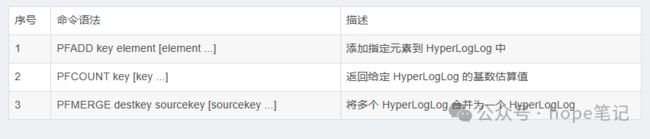
3. 使用场景
常用来统计一个集合中不重复的元素个数,例如网站PV(Page View 页面浏览量)、UV(UniqueVisitor,独立访客),搜索关键词数量,数据分析、网络监控及数据库优化等领域。
4. 使用例子
// 新增元素
redisTemplate.opsForHyperLogLog().add("key", "V1");
// 获取估算数量
redisTemplate.opsForHyperLogLog().size("key");
// 合并
redisTemplate.opsForHyperLogLog().union("newKey", "key1", "key2");九、流信息(Streams)
1. 简介
Stream是Redis 5.0引入的一种新数据类型,是一个新的强大的支持多播的可持久化的消息队列。
相比于现有的PUB/SUB、BLOCKED LIST,其虽然也可以在简单的场景下作为消息队列来使用,但是Redis Stream无疑要完善很多。Redis Stream提供了消息的持久化和主备复制功能、新的RadixTree数据结构来支持更高效的内存使用和消息读取、甚至是类似于Kafka的Consumer Group功能。
它以更抽象的方式对日志数据结构进行建模,但是日志的本质仍然完好无损:像日志文件一样,通常实现为仅在追加模式下打开的文件, Redis流主要是仅追加数据结构。至少从概念上讲,由于Redis是流式传输在内存中表示的抽象数据类型,因此它们实现了更强大的操作,以克服日志文件本身的限制。
尽管数据结构本身非常简单,但Redis流却成为最复杂的Redis类型的原因在于它实现了其他非强制性功能:一组阻止操作,使消费者可以等待生产者将新数据添加到流中,此外还有一个称为“ 消费群体”的概念。
消费者群体最初是由流行的称为Kafka(TM)的消息传递系统引入的。Redis用完全不同的术语重新实现了一个类似的想法,但是目标是相同的:允许一组客户合作使用同一消息流的不同部分。
2. 常用命令
-
XADD 将新条目添加到流中。
-
XREAD 读取一个或多个条目,从给定位置开始并按时间向前移动。
-
XRANGE 返回两个提供的条目 ID 之间的条目范围。
-
XLEN 返回流的长度。
3. 使用场景
消息队列,和kafka, RocketMq ,RabbitMq等各种消息中间件要按照当前环境的情况和要求合理使用。
4. 使用例子
//向指定Stream键中添加一条消息
MapRecord message = StreamRecords.newRecord().ofStrings()
.withStreamKey("mystream")
.withStreamId(StreamOffset.create("mystream", "0-0"))
.withValues("field1", "value1", "field2", "value2");
redisTemplate.opsForStream().add(message);
//获取指定范围内的消息
List> messages = redisTemplate.opsForStream().range("mystream", Range.unbounded());
//删除指定的Stream键
redisTemplate.opsForStream().delete("mystream");
//获取Stream中消息的数量
Long size = redisTemplate.opsForStream().size("mystream");
//使用消费者组从指定偏移量开始读取消息
StreamReadOptions options = StreamReadOptions.empty()
.block(Duration.ofMillis(1000))
.count(10);
List> messages = redisTemplate.opsForStream()
.read(Consumer.from("consumerGroup", "consumerName"), options, StreamOffset.create("mystream", ReadOffset.lastConsumed())); 