GAN生成对抗网络介绍
GAN简介
GAN 全称是Generative Adversarial Networks,即生成对抗网络。
“生成”表示它是一个生成模型,而“对抗”代表它的训练是处于一种对抗博弈状态中的。
一个可以自己创造数据的网络!
判别模型与生成模型
判别模型(Discriminative Model)
主要目标是对给定输入数据直接进行建模,以便预测输出的标签或类别。
判别模型学习得到的是条件概率分布 p ( y ∣ x ) p(y|x) p(y∣x),给定x后使得正确标签y的概率最大。
常见的判别模型包括逻辑回归、支持向量机(SVM)、神经网络等。
当输入一张训练集图片x时,判别模型输出分类标签y。模型学习的是输入图片x与输出的类别标签的映射关系。即学习的目的是在输入图片x的条件下,尽量增大模型输出分类标签y的概率。
生成模型(Generative Model)
主要目标是学习输入数据的分布,以便能够生成与输入数据类似的新数据。
生成模型学习得到的是联合概率分布 p ( x , y ) p(x,y) p(x,y),即特征x和标签y共同出现的概率;根据贝叶斯公式: p ( x , y ) = p ( y ∣ x ) ∗ p ( x ) p(x,y) = p(y|x) * p(x) p(x,y)=p(y∣x)∗p(x),它得学习p(x);关心数据和如何产生,如何分布,最终学会拟合训练数据的分布
典型的生成模型有朴素贝叶斯、隐马尔可夫模型(HMM)、生成对抗网络(GAN)等。
没有约束条件的生成模型是无监督模型,将给定的简单先验分布π(z)(通常是高斯分布),映射为训练集图片的像素概率分布p(x),即输出一张服从p(x)分布的具有训练集特征的图片。模型学习的是先验分布π(z)与训练集像素概率分布p(x)的映射关系。
山羊绵羊的例子
要确定一只羊是山羊还是绵羊
判别模型:用判别式模型的方法是从历史数据中学习到模型,然后通过提取这只羊的特征来预测出这只羊是山羊的概率,是绵羊的概率。
生成模型:则是根据山羊的特征首先学习出一个山羊的模型,根据绵羊的特征学习出一个绵羊的模型,然后从这只羊中提取特征,放到山羊模型中看概率是多少,再放到绵羊模型中看概率是多少,哪个大就是哪个。

从图中可以看出,判别模型就是在不同的类别中划分一条界限(决策边界),
而生成模型就是用不同的区域(概率分布函数)把不同类型的数据"围住" 。
为什么需要GAN?
GAN与前面CNN、RNN的最主要区别在训练方式上——无监督学习。
一句话来概括 GAN 的设计动机就是——自动化。
1.从人工提取特征——到自动提取特征
- 深度学习最特别最厉害的地方就是能够自己学习特征提取。
- 机器的超强算力可以解决很多人工无法解决的问题。自动化后,学习能力更强,适应性也更强。
2.从人工判断生成结果的好坏——到自动判断和优化- 监督学习中,训练集需要大量的人工标注数据,这个过程是成本很高且效率很低的。
- 而人工判断生成结果的好坏也是如此,有成本高和效率低的问题。
- 而 GAN 能自动完成这个过程,且不断的优化,这是一种效率非常高,且成本很低的方式。
监督学习与无监督学习
监督学习:在有监督学习中,模型通过输入数据和相应的标签进行训练。训练数据包含了输入-输出对,模型的目标是学习将输入映射到正确的输出。需要人工标注数据,人类去告诉算法该做什么和不该做什么,限制了算法的潜力。
无监督学习:在无监督学习中,模型接收的训练数据没有标签。模型的目标通常是从无标签的数据中学习并发现数据的内在结构和潜在模式,不依赖标签数据进行学习。
GAN的基本结构

GAN的基本结构
生成器 + 判别器 = GAN
我们现在拥有大量的手写数字的数据集,我们希望通过GAN生成一些能够以假乱真的手写字图片。
主要由如下两个部分组成:
定义一个模型来作为生成器(上图中蓝色部分Generator),能够输入一个向量,输出手写数字大小的像素图像。
定义一个分类器来作为判别器(上图中红色部分Discriminator)用来判别图片是真的还是假的(或者说是来自数据集中的还是生成器中生成的),输入为手写图片,输出为判别图片的标签。
生成器的目标是生成尽可能真实的数据,以欺骗判别器,
而判别器的目标是尽可能准确地区分出真实数据和生成器生成的假数据。
举例——GAN在生成手写数字识别数据上的应用
GAN性能的提升从生成器G和判别器D进行左右互搏、交替完善的过程得到的。
所以其生成G网络和判别D网络的能力应该设计得相近,复杂度也差不多。
使用全连接神经网络实现GAN
生成器G中首先是输入一个 100 × 1 100 × 1 100×1 的随机噪音Z ,然后通过三个隐藏层,最终在输出层输出一个尺寸为 784 × 1 784 × 1 784×1 的假样本。
而在判别器D中,首先是输入一个 784 × 1 784 × 1 784×1 的真实样本 x 或 生成的假样本 G(z),然后通过三个隐藏层,最终在输出层输出一个 1 × 1 1 × 1 1×1 的值,也就是输出一个数值,这个值就相当于判别器给真实样本 x 或生成的假样本 G(z)的分值。

使用卷积神经网络实现GAN——DCGAN(深度卷积生成对抗网络)
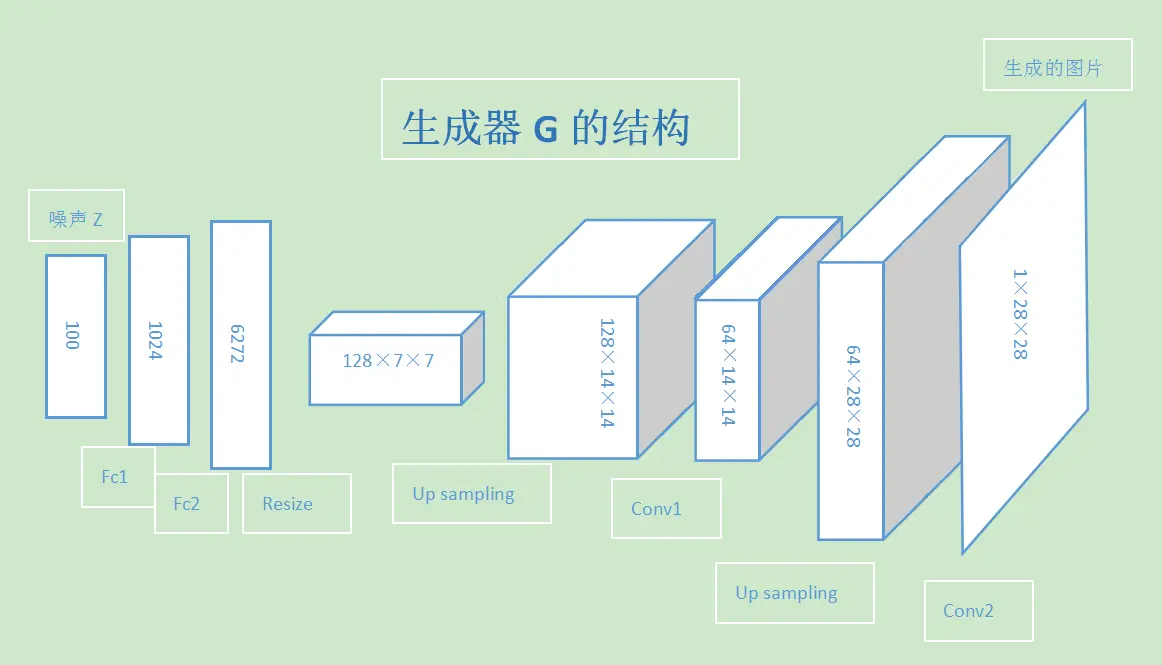
这个项目中的生成器,采用了两个全连接层接两组上采样和转置卷积层,将输入的噪声Z逐渐转化为 1 × 28 × 28 1×28×28 1×28×28的单通道图片输出。
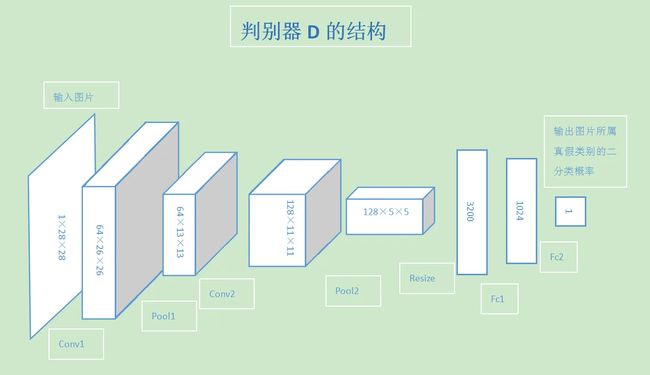
判别器的结构正好相反,先通过两组卷积和池化层将输入的图片转化为越来越小的特征图,再经过两层全连接层,输出图片是真是假的二分类结果。
GAN的基本思想
GAN的基本思想是训练两个互相对抗的神经网络,一个是生成器(Generator)用来生成伪造的数据,另一个是判别器(Discriminator)用来鉴别数据。
它们被设计为竞争对手。判别器经过训练后,可以将训练集中的数据分类为真实数据,将生成器产生的数据分类为伪造数据;生成器在训练后,能创建可以以假乱真的数据来欺骗判别器。最终要得到的是 效果提升到很高很好的生成模型。通过学习和对抗,最终达到一种纳什均衡的状态
GAN的核心思想是通过学习真实训练数据,生成“以假乱真”的数据。
Tips: 之所以要训练k次(k为大于等于1的整数)判别器,再训练生成器,是因为要先拥有一个好的判别器,使得能够较好地区分出真实样本和生成样本之后,才好更为准确地对生成器进行更新
纳什均衡,它是指博弈中这样的局面,对于每个参与者来说,只要其他人不改变策略,他就无法改善自己的状况。对应的,对于GAN,情况就是生成器 G 恢复了训练数据的分布(造出了和真实数据一模一样的样本),判别器再也判别不出来结果,准确率为 50%,约等于乱猜。这时双方网络都得到利益最大化,不再改变自己的策略,也就是不再更新自己的权重。)

上图中: 黑色点线为训练集数据分布曲线 蓝色点线为判别器输出的分布曲线 绿色实线为生成器输出的分布曲线
z表示噪声,展示的是生成器映射前的简单概率分布(一般是高斯分布)的范围和密度 x展示的是z通过生成器映射后学到的训练集的概率分布的范围和密度
(a) 判别器与生成器均未训练呈随机分布
(b) 判别器经过训练,输出的分布在靠近训练集“真”数据分布的区间趋近于1(真),在靠近生成器生成的“假”数据分布的区间趋近于0(假)
© 生成器根据判别器输出的(真假)分布,更新参数,使自己的输出分布趋近于训练集“真”数据的分布。
经过**(b)©(b)©…**步骤的循环交替。判别器的输出分布随着生成器输出的分布与训练集分布的接近而更加平缓;生成器输出的分布则在判别器输出分布的指引下逐渐趋近于训练集“真”数据的分布。
(d) 训练完成时,生成器输出的分布完美拟合了训练集数据的分布,判别器的输出由于生成器的完美拟合而无法判别生成器输出的真伪而呈一条取值约为0.5(真假之间)的直线。
GAN的训练
训练判别器
- 判别器对真实数据和来自生成器生成的假数据进行分类
- 判别器的损失函数将惩罚由判别器产生的误判,比如把真实实例判定成假,或者把假的实例判定为真
- 判别器通过对来自于判别器网络损失函数计算的损失进行反向传播,使用误差反向传播机制来计算损失和更新权重参数
在判别器训练时,生成器不会训练,即在生成器为判别器生成示例数据时,生成器的权重保持恒定,pytorch中通过使用detach()不计算生成器的梯度
训练生成器——使用判别器训练生成器
- 随机噪音采样作为输入
- 生成器从采样的随机噪音采样里生成输出
- 让判断器判断上述输出是“真”或“假”,以此作为生成器的输出
- 从判别器的分类输出计算误差损失
- 穿过判别器和生成器的反向传播,从而获得梯度
- 使用梯度来更新生成器的权重
交替训练
生成器和判别器有不同的训练流程,那么如何才能作为一个整体来训练GAN呢?GAN的训练有交替阶段,
- 判别器训练一个或者多个迭代。
- 生成器训练一个或者多个迭代。
- 不断重复1和2步来训练生成器和判别器。
在判别器训练的阶段,保持生成器不变。因为判别器训练会尝试从仿冒数据里分辨出真实数据,判别器必须学习如何识别生成器的缺陷。这就是经过完整训练的生成器和只能生成随机输出的未训练生成器的不同之处。
类似地,在生成器训练的阶段,保持判别器不变。否则,生成器像尝试击中移动目标一样,可能永远无法收敛。
收敛
随着训练进行,生成器不断改善,相对地,由于不能再轻易地识别出真实数据和假冒数据的,判别器的表现越来越差。当生成器生成数据具有和真实数据相同的分布时,判别器的正确率只有50%。基本上和抛一枚硬币来预测正反一样的概率一样。





三步训练循环
第1步——用实际数据集训练判别器;向判别器展示一个真实的样本数据,告诉它该样本的分类应该是1.0【正面样本】
第2步——用生成数据集训练判别器;向判别器显示一个生成器的输出,告诉它该样本的分类应该是0.0【负面样本】
第3步——训练生成器;向判别器显示一个生成器的输出,告诉生成器结果应该是1.0
怎样进行权重更新?
BP误差反向传播算法+梯度下降法,调整参数
