SLAM中的二进制词袋生成过程和工作原理

长期视觉SLAM (Simultaneous Localization and Mapping)最重要的要求之一是鲁棒的位置识别。经过一段探索期后,当长时间未观测到的区域重新观测时,标准匹配算法失效。
当它们被健壮地检测到时,回环检测提供正确的数据关联以获得一致的地图。用于环路检测的相同方法可用于机器人在轨迹丢失后的重新定位,例如由于突然运动,严重闭塞或运动模糊。
词袋的基本技术包括从机器人在线收集的图像中建立一个数据库,以便在获取新图像时检索最相似的图像。如果它们足够相似,则检测到闭环。传统的文本分类主要采用基于词袋(bag of words)模型的方法。但BoW模型存在一个重要问题,即数据稀疏性。
由于文本中的单词通常非常多,而一篇文本中只包含其中的很小一部分,所以BoW模型构建的特征向量大多是零向量,非常稀疏。这会导致分类效果不佳和计算效率低下。BoBW模型(二进制词袋)克服了BoW模型的稀疏性问题。为解决BoW模型的稀疏性问题,研究者提出了基于二进制特征的bag of binary words(BoBW)模型。BoBW方法使用固定大小的二进制码(binary codes)表示文本,而不是高维的词频向量。
这样一来就克服了BoW模型中的稀疏性问题。BoBW模型还可以提高计算效率,由于BoBW模型使用低维的二进制特征,大大减少了计算量和内存需求。这使得BoBW模型在分类速度和效率上具有明显优势。
二进制词袋是一种特征表示方法,将文本中的词映射为有限长度的二进制向量。具体而言:首先,为文本设定一个词表,将文本中出现的所有不重复单词作为词表中的单词。然后, 对于特定文本,检查其中是否出现词表中的每个单词。如果出现,则为1;否则为0。这样便构建出一个固定长度的二进制向量来表示该文本,其中每个元素对应词表中的一个单词。
二进制特征表示使用FAST算法检测角点,FAST算法通过比较角点周围一个半径为3的Bresenham圆 的像素灰度来检测角点。这样只需比较少量像素,计算效率高。为每个FAST角点计算BRIEF描述子。BRIEF描述子是二值向量,每个元素是角 点周边patch中两个像素点亮度比较的结果。BRIEF描述子公式:
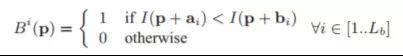
其中Bi(p) 是描述子的第i个元素,I()是像素处的亮度,ai和bi 是比较的两个像素点相对于patch中心的偏移量。给出patch大小S_b和元素数L_b,a_i 和 b_i在离线阶段随机选择。两个BRIEF描述子之间的距离使用汉明距离计算。使用二进制构建Bag of Words模型,通过二值聚类(k-medians)将二值描述子空间离散化为视觉词汇。实现了直接索引和反向索引,加快了相似图像检索和几何验证过程。通过考虑与之前匹配的一致性,有效处理了语义相似问题。最终算法的特征提取和语义匹配只需22ms,比SURF等特征快一个数量级。
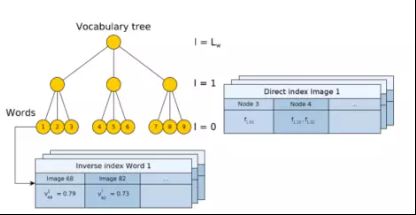
图1 :词汇树和组成图像数据库的正反索引的例子。词汇是树的叶节点。逆指数存储单词在其出现的图像中的权重。直接索引将图像的特征及其关联节点存储在词汇树的某个级别上。
一、图像数据库建模
这一节介绍使用Bag of Words模型将图像特征转换为稀疏数字向量,方便处理大量图像。采用词汇树(vocabulary tree)将描述子空间离散化为W个视觉单词。不同于其他特征,这里离散的是二值描述子空间,建模更紧凑。语义树通过层次的k-medians聚类建立。
先对训练样本做k-medians聚类,取中心。然后递归地对每个聚类分支重复,建立Lw层语义树,W个叶节点作为最终视觉单词。每个语义单词根据其在训练语料中的频繁程度赋予权重,抑制高频低区分度的单词。使用tf-idf值。图像It转换为 bag-of-words向量vt,它的二值描述子从根开始遍历语义树,选择每一层与它汉明距离最小的中间节点,最终达到叶节点。两个bag-of-words 向量v1和v2的相似性计算为:
![]()
除了bag of words和反向 索引外,文章还提出使用直接索引,存储每个图像的单词及其对应特征。直接索引用于快速计算对应点,只比较属于同一个层次的祖先节点的特征。
二、回环检测
1.数据库查询
当获取最新图像It时,将It转换为bag-of-words向量vt。搜索数据库,结果是与vt最相似的图像
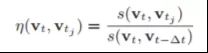
其中s(vt,vt-∆t)是与前一张图像的分数,用于近似It的最高分。
2.匹配分组
为了防止连续图像竞争,将相似的连续图像分组。如果两个图像之间的时间差小,那么它们就属于同一个组。计算组的得分:

取分数最高的组作为初始匹配。
3.时间一致性
连续查询的一致性检查。匹配
4.有效几何一致性
当给出一个匹配的图像对
参数l是一个权衡匹配点数量和时间成本的因子。当l = 0时,仅比较属于同一个单词的特征(速度最快),但得到的对应点较少。当l = Lw时,对应点数量不受影响但时间也没有获得改进。一旦获得足够的对应点,我们用RANSAC算法找出基础矩阵。虽然我们只需要基础矩阵来验证匹配,但计算出基础矩阵后,我们可以毫无额外代价地为SLAM算法提供图像间的数据关联。
三、实验测试
评估内容包括:使用5个公开数据集,涵盖室内外、静态动态环境。手动创建环回 ground truth ,包含匹配时间间隔。使用精确率和召回率度量正确性。使用不同的数据集调参和评价效果,证明算法鲁棒性。
与SURF进行比较,结果显示:BRIEF效果与SURF接近,在Bicocca25b上优于SURF64和U-SURF128。BRIEF更快,但对尺度和旋转变化敏感。BRIEF更适合匹配远距离对象,SURF适用于近距离变化大。
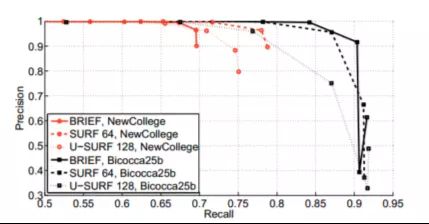
图2:在不进行几何检验的情况下,BRIEF、SURF64和U-SURF128在训练数据集上得到的Precision-recall曲线。
其次,需要一定数量的时间一致检测才能检测环回。k=3 的结果最佳,对于不同频率稳定。如下图所示:
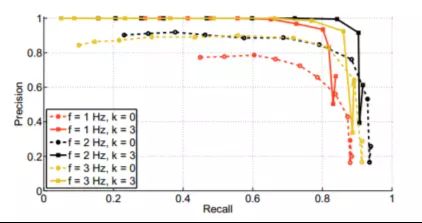
图3 相似阈值α、时间一致匹配数k和处理频率f
在时间耗时方面,完整算法只需22ms,比SURF慢一个数量级。提取特征花费时间最多。使用大型词汇表虽花更多时间转换,但查询更快。

图4 使用BRIEF(左侧成对)和SURF64描述符(右侧成对)匹配的单词示例
四、结论
二进制特征在词袋方法中是非常有效和极其高效的。特别是,结果表明FAST+BRIEF特征与SURF(64维或128维且没有旋转不变性)一样可靠,用于解决移动机器人中常见的平面内相机运动的环路检测问题。
在不需要特殊硬件的情况下,执行时间和内存需求要小一个数量级。公共数据集描述了室内、室外、静态和动态环境,包括正面或侧面摄像头。与大多数以前的工作不同,为了避免过度调优,我们限制自己使用从独立数据集获得的相同词汇表和从一组训练数据集获得的相同参数配置来呈现所有结果,而不窥视评估数据集。
因此,我们可以声称我们的系统在广泛的实际情况下提供了健壮和高效的性能,而无需任何额外的调优。该技术的主要限制是使用缺乏旋转和尺度不变性的特征。