探索数据的奥秘:一份深入浅出的数据分析入门指南
数据分析
书籍推荐
入门读物
- 深入浅出数据分析
- 啤酒与尿布
- 数据之美
- 数学之美
数据分析
- Scipy and Numpy
- Python for Data Analysis
- Bad Data Handbook
- 集体智慧编程
- Machine Learning in Action
- 机器学习实战
- Building Machine Learning Systems with Python
- 数据挖掘导论
- Machine Learning for Hackers
专业读物
- Introduction to Semi-Supervised Learning
- Learning to Rank for Information Retrieval
- Learning to Rank for Information Retrieval and Natural Language Process
- 推荐系统实战
- Graphical Models, Exponential Families and Variational Inference
- Natural Language Processing with Python
机器学习教材
- The Elements of Statistical Learning
- 统计学习基础
- 统计学习方法
- Machine Learning(Kevin Murrphy)
- Machine Learning: An Algorithmic Perspective
- Pattern Recognition And Machine Learning
- Bayesian Reasoning and Machine Learning
- Probabilistic Graphical Models
- Convex Optimization
数据网站
- Monthly Bulletin of Statistics Online:数据来源顾名思义,来自各个国家统计局和组织
- World Development Indicators:世界银行的数据
- CIA world factbook: 中央情报局收集的数据
- IPUMS: 普查数据的集成网站
- ICPSR: Umich的数据中心收集的数据集
- Kaggle:竞赛网站
量化
- 语言要求:
- 效率语言:C,C++, Java
- 快,编程复杂度高,维护难
- 不支持向量计算
- 胶水语言:Python, Ruby
- 实现简单,编程复杂度高,维护相对简单,支持向量运算
- 科学类语言:Matlab, R, S
- 支持向量计算
- 快速验证想法
- Alpha演算类语言:Lisp, Clojure
- 查询类语言:SQL, Q
- 效率语言:C,C++, Java
数据分析,数据挖掘,数据统计,OLAP之间的关系
- 数据分析:用适当的统计方法对收集来的大量第一手资料和第二手资料进行分析,以求最大化地开发数据资料的功能,发挥数据的作用。提取有用信息和形成结论而对数据加以详细研究和概括总结的过程。此方向更偏产品一些,极大的依赖分析经验和对数据的敏感度。
- 代表人物:
- Justin Cutroni: http://cutroni.com/blog/
- Joegh:http://webdataanalysis.net/
- 宋星: http://www.chinawebanalytics.cn/
- 蓝鲸:http://bluewhale.cc/
- 代表人物:
- 数据挖掘:据挖掘主要是面向决策,从海量数据中挖掘不为人知、无法直观得出的结论。例如内容推荐、相关度计算等。此工作更注重数据内在联系,数据仓库组建,分析系统开发,挖掘算法设计,甚至很多时候要亲力而为的从ETL开始处理原始数据,因此对计算机水平有较高要求。一般广度上不及数据分析,但深度上更为深入。使用工具除海量数据库如Oracle,分布式计算Hadoop,C++,Java,Python等编程语言外,也有可能会用到第三方挖掘工具如Weka。更偏向于技术
- 代表人物:
- Jeff Hammerbacher,编写《数据之美》
- 探索推荐引擎内部的秘密
- 代表人物:
- 数据统计:注于建模及统计分析,通过概率、统计、离散等数学知识建立合理模型,充分发掘数据内容。例如用回归分析,充分利用网站历史数据,进行评估、预测、反向预测、发掘因素。利用贝叶斯方法建立模型来进行机器学习、聚类、垃圾邮件过滤等。常用工具如:SAS,R,SPSS,更偏向于数学,在互联网,金融,医疗领域应用广泛
- OLAP:建立数据系统的方法,核心思想就是建立多维度的数据立方体,以维度(Dimension)和度量(Measure)为基本概念,辅以元数据,实现可以钻取、切片、切块、旋转等灵活、系统、直观的数据展现。严格使用OLAP的一般都是些制造业、零售业等相对传统的行业,作为BI的延伸,对公司决策提供有力支撑
统计学分析-Python VS R
R主要在学术界流行,python(numpy scipy)在工程方便比较实用。
- 性能:
- R处理文本文件很慢
- python很容易变得更快,pypy,cython,或者直接ctypes挂C库
- 并行计算:
- R v15 之后有了自带的parallel包,使用挺轻松的
- Python有multiprocessing,可以共享数据
- 学习曲线:
- R一开始还是很容易上手的,查到基本的命令,如果要自己写算法、优化性能的时候,学习难度陡增。
- Python-挺好学的,丰富的包供使用
- 画图:
- R自带的那些工具就挺好用,ggplot这种非常优美的得力工具
- python 有matplotlib比R自带的好一些些,界面基于QT,跨平台支持
- IDE:
- Rstudio非常不错,提供类matlab环境
- Python:Vscode,Pycharm
- 建议:
- 如果只是处理(小)数据的,用R
- 要自己搞个算法、处理大数据、计算量大的,用python
值得推荐的R语言的书
初学者入门
- R in Action
- The Art of_R Programming
- learning R
统计进阶
- A Handbook of Statistical Analyses Using R
- Modern Applied Statistics With S
科学计算
- Introduction to Scientific Programming and Simulation Using R
数据挖掘
- Data Mining with R Learning with Case Studies
- Machine Learning for Hackers
- An Introduction to Statistical Learning
数据绘图
- ggplot2 Elegant Graphics for Data Analysis
- R Graphics Cookbook
参考手册
- R Cookbook
- R in a Nutshell
高级编程
- R Programming for Bioinformatics
- software for data analysis programming with R
- Advanced R programming
Python应学习的包
- Pandas
- Numpy
- Scipy
- Matplotlib
- Scikit Learn
大数据如何处理
-
UC Berkeley Course Lectures: Analyzing Big Data With Twitter
-
第一、分解数据:需要根据具体情况分析,可以把大CSV原始数据拆解成每年每个月的(以yyyyMM.csv的格式储存),那子文件的数据量就可以降一到两个数量级,这样就可以用Matlab来处理,同时也间接完成了索引的工作。
-
第二、如果数据实在是非常巨型(100GB+),我建议采用非关系型数据库(MonoDB等)来处理
-
海量数据分成两块,一是系统建设技术,二,海量数据应用。
- 系统建设技术:现在主流的技术是HADOOP,主要基于mapreduce的分布式框架。
- 海量数据应用:主要是数据挖掘和机器算法。

数据分析师的主要工作有哪些?发展前景如何?需要掌握哪些相关知识?
-
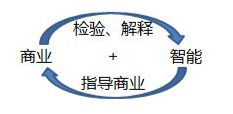
商业智能:商业智能=商业+智能
- 首先是商业检验智能技术。商业目标以及商务流程,限定了你能选用的分析方法。
- 其次是智能技术指导商业行为。业务人员不懂技术,技术人员不懂业务。
-
数据和数据仓库
- 数据是数据分析的基础,数据库是数据的承载,数据仓库是有主题的数据库。
- 数据质量又可以分成两大块,“脏”数据的处理和数据来源口径的追溯。garbage in garbage out。
- 报表:首先是确定报表的目的,这样才能定下报表是清单级还是汇总级;其次选择字段。再次是对字段做维度聚类,并做重要性排序。
-
数据挖掘:BI=图表+数据挖掘的理解
-
算法:
- 程序=数据结构+算法
- 要成为一名高级分析师,那肯定得有一定深度的研究。知道针对特定的数据集,选用什么样的算法,如何抽取样本,抽取多大量的样本(样本出问题,整个项目都完蛋),算法适用条件是什么,比如线性回归的:独立性、常方差、正态性,怎么理解,哪些必须满足。
- 二是客户问到一些问题,知道如何去解释,比如用决策树计算出来的得分,为什么很多样本得分是一样的?客户细分中,有没有算法可以使得同一个客户细分至两个不同的客户群
- 三是你能写出针对特定问题的算法,现实中许多问题拥有其他问题一样的共性,也有它自己的个性,某些时候针对个性的东西越强,分析效果越好,这就需要你手写算法解决。
- 级的数据分析师,算法与数据结构的知识必不可少。搜索,排序,树,图之所以经典,是因为它们简单有效而且通用。
-
统计学与其中的分析逻辑问题:
- 经常发现两样事物是互为因果互相加强的,“事物有普遍联系”和“作用与反作用”的哲学原理。
-
商业:
- 菲利普科特勒《市场营销》
- 斯蒂芬鲁宾斯的《管理学》
-
增值知识:
- 分析师宽广的知识面必不可少,没事看看心理学、历史、地理、人口统计学(demography),浏览一下知乎,FT中文网。
-
数据信息图:
- http://infosthetics.com/
- http://flowingdata.com/
- http://visual.ly/
-
资料:
- http://radar.oreilly.com/
- http://www.businessinsider.com
-
报告:
- http://vdisk.weibo.com/s/2YJeC
商业智能,是利用计算机对数据大量快速处理的特点,对众多商业数据做图与表的展现分析,并通过统计学的方法对数据进行智能学习和挖掘,辅助商业决策。商业智能的优势就在于它对海量数据的处理,以及可规则化逻辑化(这点部分继承了数学的DNA),这些杂乱的数据让人去处理和挖掘有用信息,基本是不可能的。
数据挖掘的系统教程是怎样的,包含哪些教材
- Pang-Ning Tan, Michael Steinbach and Vipin Kumar, Introduction to Data Mining.
- Jiawei Han and Micheline Kamber, Data Mining: Concepts and Techniques.
- Mining of Massive Dataset, by Anand Rajaraman and Jeff Ullman ( Derived from Stanford CS345)
- Programming Collective Intelligence, by Toby Segaran, August 2007.
- Beautiful Data by Toby Segaran, Jeff Hammerbacher
- The Text Mining Handbook by R. Feldman and J. Sanger
- Web Data Mining by Bing Liu
- The Elements of Statistical Learning (统计学习基础) by Trevor Hastie etc
- 有志于专门深入数据挖掘的某个细分领域,最好直接读相关的survey论文,和最新的直接看各大数据挖掘相关会议论文即可 ( KDD/SIGMOD/VLDB/ICDE/WSDM/ICDM etc)
- 《数据挖掘概念与技术》,作者:[加]Jiawei Han/Micheline Kamber 译: 范明/孟小峰 等
- 《数据挖掘导论》,作者: [美]Pang-Ning Tan,Michael Steinbach,Vipin Kumar 著
- 数据挖掘技术——市场营销、销售与客户关系管理领域应用》作者: (美)贝瑞
- 《实用多元统计分析》
国内外与信息可视化相关的专业博客、论坛、社区有哪些?
博客
- http://eagereyes.org
- http://flowingdata.com
- http://www.mcwetboy.net/maproom
- http://www.liesdamnedlies.com/visualization/
- http://www.informationisbeautiful.net/
- http://infosthetics.com/
- http://indiemaps.com/blog/
- http://graphjam.memebase.com/
- http://fivethirtyeight.blogs.nytimes.com/
- http://well-formed-data.net/
- http://www.visualcomplexity.com/vc/
可视化
- http://www.biostat.wisc.edu/%7Ekbroman/topten_worstgraphs/
- http://www.improving-visualisation.org/case-studies
- http://infovis.cs.vt.edu/cs5764/lectures/Lies.ppt
- http://sfew.websitetoolbox.com/
- http://colorusage.arc.nasa.gov/issues.php
- http://www.webdesignerdepot.com/2009/06/50-great-examples-of-data-visualization/
- http://old.siggraph.org/publications/newsletter/v33n3/contributions/davis.html
- http://www.math.yorku.ca/SCS/Gallery/
- http://www.infovis-wiki.net/
实际应用
- http://www.nytimes.com/2010/09/13/technology/13roadkill.html
- http://www.dailymail.co.uk/home/moslive/article-1272921/Ten-greatest-maps-changed-world.html
- http://www.nytimes.com/2009/11/19/opinion/19silver.html
- http://www.nytimes.com/2010/05/28/nyregion/28map.html
- http://www.nzherald.co.nz/building-construction/news/article.cfm?c_id=24&objectid=10671930
- http://wholemeal.co.nz/%7Emalc/darfield-earthquake-timeline/
- http://projects.nytimes.com/census/2010/explorer
- http://www.nytimes.com/2010/05/02/magazine/02self-measurement-t.html
- http://i.imgur.com/hmGgW.gif
- http://www.nytimes.com/2010/04/27/world/27powerpoint.html
- http://jec.senate.gov/republicans/public/index.cfm?p=CommitteeNews&ContentRecord_id=bb302d88-3d0d-4424-8e33-3c5d2578c2b0
- http://faculty.uoit.ca/collins/research/index.html
- http://www.chrisharrison.net/projects/visualization.html
- http://bits.blogs.nytimes.com/2009/12/17/a-day-in-the-life-of-nytimescom/
- http://www.style.org/
- http://www.nytimes.com/2008/08/31/technology/31novel.html
数据集
- http://snap.stanford.edu/data/index.html
- http://ngrams.googlelabs.com/datasets
- http://archive.ics.uci.edu/ml/
- http://kdd.ics.uci.edu/
- http://www.graphics.stanford.edu/courses/cs448b-04-winter/online_databases.html
论坛
- http://processing.org/- processing
- http://processingjs.org/- processing.js
- http://www.vischeck.com/
数据分析师和数据科学家有何区别?
- Data Scientists往往可以独立完成一条龙的完整分析过程:从数据提取,整合、并进行分层,进行统计或其他复杂的分析,创造引人注目的可视化诠释和效果,开发具有更宽广应用前景的数据工具
- 偏向于data reseacher的有,多见于大型IT企业,百度大脑的data scientist们多属于这一类型,他们搞的是比较前沿的深度学习,平常会读大量paper可能自己也会发
- 偏向于data creative的有,各种企业都会储备,会ETL,懂模型、懂行业,会展示沟通,比较能够创造直接的价值
- 偏向于data developer的也有但是很少,他们不懂模型,只要给他们算法公式,他们就能用编程语言帮你实现,实现算法是重要的技能,但是这种不懂模型不懂行业的,现在大多企业都不太会给这样的人data scientist的title
- data reseacher:发明/改进模型算法然后给R写package的
- data creative:用R作分析的
- data developer:觉得R太简单不屑于用的+偶尔帮data reseacher给R写package的
- 一个理想的data scientist应该是data developer、data creative、data researcher、data businessperson的结合,Ta往往能够领导一个没有被清晰定义的问题的回答过程,在这期间,data scientist对于完整分析过程的把控能力能够帮助Ta主导项目的方向,整合各方资源,data scientist并不一定需要亲身参与到技术开发过程中,但是Ta知道什么样背景的人能够胜任这些工作,知道怎样组建适当的团队,也知道什么样的模型或分析方法能够适用,它们的优缺点都是什么,怎样改进,必要时懂得去查找学术界最新的研究成果并转化;以及知道老板想要什么,始终牢牢把握问题的核心,及时纠偏。最后,把这一套回答此类问题的方法流程化,以应付以后出现类似问题。
综上所述,data scientist应该是data developer, data creative, data researcher、data businessperson的结合,但又高于这四者,关键就在于Ta对于整个数据分析闭环的把控能力。有清晰定义的、循规蹈矩的Routine work不是data scientist的专长,data scientist的专长在于formulate、quantify未清晰定义的问题,data science这个领域本来就有协作性,靠一个人单打独斗肯定不行,但只有data scientist这样的“通才”才有能力领导那四种“专才”去解决棘手的问题。
R中重要的一些命令或包
- CRAN - Package xkcd把你的图绘制成xkcd http://xkcd.com
- CRAN - Package magrittr向前管道操作符以及其他一些操作符的别名
- CRAN - Package knitr自动化报告生成
- CRAN - Package functional函数编程的时候会用到
- CRAN - Package Rcpp R和cpp能这么方便地结合
- Slidify 用markdown做出漂亮的slides
大数据计算框架除了MapReduce还有哪些?
- 面向内存迭代运算的spark,专门针对流式计算的storm等
- 更高级的Hive和PIG
相关课程
- CS236_DGM
- CS228_PGM
- CS221_AI
- CS229_ML
- CS230_DL
- CS224n_NLP
- CS231n_CNN
- CS234_RL