高并发方案设计(海量数据,高并发处理方案)
提示:海量数据设计方案、高并发设计方案、宽表是什么、什么是写扩散、微博这种高并发写高并发读怎么设计、什么是对冲请求、什么是重写轻读
文章目录
- 前言
- 一、分类
- 二、高并发读
-
- 1、策略1:加副本
-
- 1.1、加缓存
- 1.2、加节点
- 1.3、CDN/静态文件加速/动静分离
- 2、策略2:并发读
-
- 2.1、异步rpc
- 2.2、冗余请求(对冲请求)
- 3、策略3:重写轻读
-
- 3.1、微博Feeds流的实现
-
- 3.1.1、原始方案实现
- 3.1.2、重写轻读方案实现
- 3.2、宽表
- 4、高并发读总结
- 三、高并发写
-
- 策略1:数据分片
- 策略2:异步化
- 策略3:批量写
- 总结
`
前言
业内常说高并发问题,高并发设计,可能部分小伙伴接触的比较少,不太清晰,今天正好梳理一下,也是为了方便后续自己查阅。本人水平有限,如有误导,欢迎斧正,一起学习,共同进步!
一、分类
不管是什么系统,我们以开发者的角度,都可以概括为读、写。其实再复杂的系统,也都是由这两部分组成的。因此,我们可以针对于不同的操作,去设计不同的数据模型或数据结构来使对应的操作更加的高效。
二、高并发读
1、策略1:加副本
1.1、加缓存
好不夸张的说,但凡做过几年程序员的,几乎都知道:流量快撑不住的时候,可以“加缓存”。这没什么可说的。缓存通常有两种思路:本地缓存,集中式缓存。本地缓存就是在客户端本地加缓存。集中式缓存就比如redis、mongo之类的。对于缓存,我们需要注意以下几点:
- 缓存的高可用问题(缓存雪崩)。如果缓存宕机,是否会导致所有请求瞬间写入并压垮数据库呢
- 缓存穿透。某些key大量查询,并且这些key都不在缓存中,导致短时间内大量请求压垮数据库
- 缓存击穿。指一个热点key,大并发集中对这个点访问。导致缓存过期的瞬间,持续的大并发直接访问库
- 大量热key过期。也是因为某些key失效,大量请求短时间内写入并压垮数据库,也就是缓存雪崩。
如果你不回源。只查缓存,缓存没有直接返回前端,这种方法肯定是主动更新缓存,并且不设置缓存的过期时间,就不会有缓存穿透、缓存雪崩的问题。如果你回源,缓存没有,要先查库,在更新缓存,就需要考虑上面的问题
1.2、加节点
如果是数据结构比较简单的,那直接
1.3、CDN/静态文件加速/动静分离
CDN、静态文件加速、动静分离等这一类,我们称为:边缘计算的方案。比如你有一个网页,大家都需要访问,如果所有人都访问你的服务器,那压力很大,你服务器承受不住,那么你就可以把这个网页主动分发到整个CDN网络中,CDN网络会进行很多的备份,然后根据客户的地址就近的去找一个节点去读这个网页。就不用非得挤着一个节点排着队去访问了,大家各自找离自己最近的节点去拿数据
注意:这三种方案(redis、mysql的master/slave、cdn/静态文件加速)虽然从技术上看完全不一样,但是从策略上看,都是“缓存/加副本”的形式,都是通过对数据进行冗余,达到空间换时间的效果。
2、策略2:并发读
2.1、异步rpc
比如说,一个接口要做3件事。如果是串行的话,总耗时是 T=T1+T2+T3,如果是并行的话,那么总耗时变成了 T = Max(T1,T2,T3)。当然前提是这三个事是没有耦合的关系。如果做完1才能做第二件事的话,就不能异步了。而且异步以后,怎么获取异步的结果也需要考虑。(比较常见的有mq、dubbo之类的。你完成了以后,调个dubbo接口或者发个mq通知一下,把结果传过去之类的回调)
2.2、冗余请求(对冲请求)
冗余请求很好理解。就是多发几个请求,那为啥要多发几个请求呢。比如说你一个请求,可以访问节点a、b、c。其中节点a是0.5秒,节点b是2秒,节点3是1.5秒。现在客户端希望每个请求的相应时间都不超过1秒。那客户端怎么知道那个请求更快呢?那同时给节点a、b、c都发同一个请求,谁先响应,我就先用谁,这就是冗余请求。
2013年谷歌公司eaf Dean在论文《The Tail at Scale》中讲过这样一个案例:假设一个用户的请求需要100台机器同时处理,每台服务器有1%的概率发生延迟调用(假设响应大于1秒为延迟调用)。那么对于c端用户来说,相应时间大于1秒的概率是63%。怎么算出来的呢?反过来算,如果用于的请求要小于1秒,那么就需要这100台服务器的响应同时小于1秒。那么概率是100个99%相乘。99%^100=0.366032… 100-0.366=63.3%。这意味着,虽然每个机器都只有1%的延迟率,c端用户延迟率却有63%,机器数越多,问题越严重。论文中给出了解决方案:同时给多个服务器发请求,哪个快,就用哪个(冗余请求)。但这会让整个系统的调用量翻倍。
对冲请求:把这个方法调整一下就变成了:客户端首先给服务器端发送一个请求,并等待服务器端给的响应,如果客户端在一定时间内没收到服务器端给的相应,则马上给另一台(或多台)服务器发同样的请求,客户端等待第一个响应到达后,终止其他请求的处理。上面的“一定时间”定义为:内部服务95%请求的响应时间。这种方法在论文中称为“对冲请求”。论文中提到了在谷歌公司的一个测试数据:采用这种方法可以仅用2%的额外请求将系统99%的请求响应从1800ms降低到74ms。
3、策略3:重写轻读
3.1、微博Feeds流的实现
这个的原理其实就是,将比较耗时的操作前移。(比如说查库比较耗时,用户登录的时候要用这个接口的数据,那么你可以在启动项目时先查出来,用户登录时直接看)。 将比较耗时的操作,从查询的时候往前移。我们有很多类似的原理:缓存预热(查库比较耗时,查缓存快,项目启动时直接查好,省的用户请求的时候再去查。
比如说微博或者微信。场景:用户关注了n个人(或者有n个好友),每个人都在不断的发微博,然后系统需要把这n个人的微博按时间排序成一个列表,也就是Feeds流展示给用户。同时,用户也需要查看自己发布的微博列表。
3.1.1、原始方案实现
关注的人表:
![]()
发布的微博(文章)表:
![]()
要想实现场景中的效果(查看这个人关注的人的发布的微博,时间排序),可以:
select followings from Following where user_id = 1 //查询user_id = 1的用户的关注的用户列表
select msg_id from msg where user_id in (followings) limit offset,count //查询关注的所有用户的微博列表
很显然,这种模型无法满足高并发的查询请求,那么怎么处理呢?
改成重写轻读:不是查询的时候再去聚合,而提前为每一个user,准备一个feeds流,或者叫收件箱
3.1.2、重写轻读方案实现
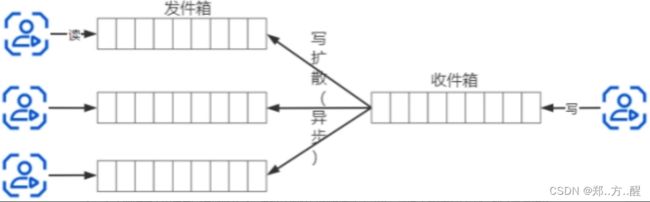
原理很简单:假设一个人拥有100个粉丝,那么这个人发布1条微博后,只写入自己的收件箱,就返回成功。然后程序异步的把这条微博去推送给他的这1000个粉丝,也就是“写”扩散。这样,用户读取feeds流的时候就不需要实时的聚合了,直接读取各自的收件箱即可。这就是“重写轻读”,把计算逻辑从“读”的一端移动到了“写”的一端。(当然,这个的前提是微博或者朋友圈这种对写的实时性没那么高的场景下,想微信、qq这种实时聊天平台就不太适合了)。
原理知道了以后,还是会有写其他问题的。
- 收件箱如何实现?因为从理论上讲,这个收件箱是一个无限长的列表。假设用redis的
- 数据怎么持久化?因为用户发布的微博,你肯定要存起来的。不能说我发了个微博,一段时间后没了,找不到了,这肯定不行。但是redis只保存了最近的2000条,2000个以前的数据势必要持久化到数据库的。因为这个数据量很显然会不断的增长,一个库肯定不行。那就涉及到用什么维度来分片了。一个是用userId来分片。一个是用时间范围来分片(比如说一个月存储一个表)。按userid肯定不行,因为随着时间的推移,微博越来越多,单表数据量还是很大。若只用时间范围来分片的话,会冷热不均。假设每月存储一张表。则绝大多数的读、写都在当月;历史月份的读很少,写则没有。所以需要同时用userid、时间范围来分片。但分完以后,如果快速的查看某个userId从offset开始的微博呢。比如一页100个,现在需要50也,怎么查到5000的位置之后的微博呢。这就需要一个二级索引,另外一张表,记录
。也就是userid在每个月发表的微博总数,基于这个索引表快速定位到5000的数据在哪个月份,也就是哪个数据的分片。 - 假设一个用户有很多粉丝呢?比如一个百万大V的博主。他的粉丝是800w,那么他发一个微博,要同时写扩散到800w个收件箱吗,这肯定是不合理的。针对这种情况,我们就不挨着发了(推),让关注这个大v的用户自己读(拉)。这种推,拉结合的方式来实现。对于读的一端,一个用户的关注的人当中,有的人是推给他的(粉丝数小于5000),有的人是需要他去拉的(粉丝数大于5000),需要把两者聚合起来,再按时间排序,然后分页显示,这就是“推拉结合”。
3.2、宽表
多表的关联查询:宽表与搜索引擎。后端经常需要对业务数据进行多表关联查询,可以通过增加slave来解决。但是这种方法只适用于没有salve的场景。如果数据分库了,那么需要从多个库去查询然后聚合,无法使用原生的join功能。就会存在这么一个问题:如果需要把聚合出来的数据按某个维度排序并分页展示,并且这个维度并不在数据库的字段中,那怎么实现呢?无法使用数据库的排序和分页功能,也无法在内存中通过实时计算来排序、分页(数据量太大了)。
解决方案:类似于微博重写轻读的思路,提前把关联的数据计算好,存在一个地方,读的时候直接去读聚合好的数据,而不是读取的时候再去做join。(比如说,你2个分片,要通过一个数据库不存在的字段去分组,那么你可以写一个定时,每天执行一次,去查数据、聚合,然后存到一个新的表中,这个表就是宽表。宽表意思是:包含了你业务查询所需要的所有的结果,而不是一条条的记录,就是宽表)。也可以用ES类的搜索引擎来实现:把多张表的Join结果做成一个个的文档,放在搜索引擎里面,也可以灵活地实现排序和分页查询功能。
4、高并发读总结
其实这些方案的核心思想都是,让读写分离(CQRS架构。Command Query Responsibility Separation)。让读的处理、写的处理分到不同的两个地方。比如说写,我直接写到库了。读的话,我加缓存啊,加宽表啊之类的.读写分离架构有几个典型特征:
- 分别为读和写设计不同的数据结构。在c端,当同事面临读和写的并发压力时,把系统分成读和写俩个视角来设计,各自设计符合高并发读、写的数据模型或数据结构。
- 写的这一端,通常是在线的业务db,通过分库分表抵抗写的压力。读的这一端为了抵抗高并发压力,针对业务场景,可能是
- 读和写的串联。就是你写的数据改了,怎么通知到读的那边。比如说发mq,写的一边变了以后,直接给读的那边发mq;或者监听数据库的binlog,监听数据库的变化去更改读库。
- 读比写有延迟。因为写数据,写完就好了。但是读数据,肯定有延迟。比如你写的数据还没通知到读的那边,就直接读,那肯定不是一致的。读和写是最终一致性,并不是强一致性。但这并不影响业务。
拿库存系统举例:假设用户读到的某个商品的库存是9件,实际上可能是8件(某个用户刚买了一件),也可能是10件(某个用户取消了订单),但等到用户真正下单的那一刻,会实时的扣减数据库里面的库存,也就是左边的写是“实时、完全准确的”,即使右边的读有一定的延迟也没关系。
同样的,拿微博系统举例:博主发了一个博客,他并没有要求粉丝立马,实时的能看到他的文章,延迟几秒钟看到这个文章也没关系。当然了,粉丝也不会感知到自己看到的博客是几秒钟前的。这并不用影响业务。
当然,有些业务,比如说涉及到钱的,或者用户自己的数据(账户里的钱,用户下的订单),在用户体验上肯定要保证,自己修改的数据要马上看到。这种在实现上,读和写可能是完全同步的,也可能是异步的,但是要控制读写比的延迟非常小,用户感知不到。
三、高并发写
策略1:数据分片
数据分片其实就是对要处理的数据或请求分成多份并行处理。数据库为了分摊读的压力,可以加缓存、加salve。为了应对高并发写的压力,就需要分库分表了。分表后,还在同一个数据库,一个机器上。但是可以更加充分的利用cpu、内存。分库后,可以利用多台机器的资源。redis cluster也是一样。es的分布式索引,在搜索引擎中有一个基本策略是分布式索引,比如10亿的商品,如果在一个倒序索引中,则索引很大,也不能并发的查询。如果是把这10亿个商品分成n份。建成n个小的索引,一个请求来了以后,并行的在n个索引上查询,再把结果聚合。
策略2:异步化
异步就太常见了。短信注册啊,订单系统下单啊等等。对于客户端来讲:异步就是请求服务器做一个事,客户端不等结果,直接干别的事。回头再去轮询或者让服务器回调通知。对于服务器来说,是接受到客户端的一个请求后,不立马返回结果,而是“后台慢慢的处理”,稍后返回结果。
策略3:批量写
这个也挺好理解的。就是将小的消息,合并为一个大的消息,然后去处理这个大的消息。举个例子就是:假设有10个用户,对同一个广告都点击了一次。也就是意味着,对同一个广告主,要扣10次钱。假设一次扣费1块,扣10次,改成批量写,就变成了,一次扣10块,扣一次。如果要模拟一下的话:从持久化的消息队列中取多条消息,对多条消息按广告主的账号id进行分组,同一个组内的消息的扣费金额累加合并,然后从数据库里扣除。
mysql的事务实现上,存在着小事务合并机制。比如扣库存,对同一个SKU,本来是扣10次、每次扣1个,也就是10个事务;在MySQL内核里面合并成1次扣10个,也就是10个事务变成了1个事务。同样,在多机房的数据库多活(跨数据中心的数据库复制)场景中,事务合并也是加速数据库复制的一个重要策略。
总结
今天主要是分享了下,从大的方向上有哪些可以优化的方案方法。很多时候如果我们从最开始的设计合理的话,后续的工作量就会少很多。避免了一些无谓的优化、重构、修复工作。后续有时间的话,会从具体实现的角度来继续分享。