机器人强化学习——Comparing Task Simplifications to Learn Closed-Loop Object Picking Using DRL(2019 RAL)
1 简介
任务是reach、grasp、lift,比较了reward shaping、curriculum learning、迁移学习,并迁移到了真实机器人场景中。
本文抓取的方法框架是QT-Opt。
2 方法
相机位置:机械臂腕部,眼在手上。
state:深度图像、机械手张开宽度
action:xyz平移、z轴旋转(想对于当前末端位姿)、机械手动作(开/闭)。每步平移最大1cm,
初始state:随机选择n个物体放置在面积为 l × l l\times l l×l的平面上,机械手放置在距离平面中心 h r o b o t h_{robot} hrobot的高度上,手指向下朝向平面。
任务离散化:将任务建模为离散时间任务,最大时间步 T = 150 T=150 T=150。
任务结束:当时间步达到 T T T或到达目标状态时,一个epsilon结束。
原始reward:任务结束时,如果物体高度达到 h l i f t h_{lift} hlift, r = r T r=r_T r=rT,否则 r = 0 r=0 r=0。
2.1 reward shaping
r = ( g r a s p _ d e t e c t e d ) ∗ ( r g + c ∗ Δ h ) − 0.1 − ( r g + c ∗ Δ h m a x ) r=(grasp\_detected)*(r_g+c*\Delta h) - 0.1 - (r_g+c*\Delta h_{max}) r=(grasp_detected)∗(rg+c∗Δh)−0.1−(rg+c∗Δhmax)
其中, g r a s p _ d e t e c t e d grasp\_detected grasp_detected是二值化数,当程序检测到机械手抓住物体(不只是闭合)时,该值为1,否则为0; r g = 1 r_g=1 rg=1, c = 1000 c=1000 c=1000, Δ h \Delta h Δh为最后一步机械手的高度增加值; − 0.1 − ( r g + c ∗ Δ h m a x ) - 0.1 - (r_g+c*\Delta h_{max}) −0.1−(rg+c∗Δhmax)是时间乘法,使agent尽快完成任务, Δ h m a x \Delta h_{max} Δhmax为机械手每一步可能的最大高度增加值(应该是z轴平移的范围值)。
2.2 课程学习
进行逐步在增加的参数包括:工作空间尺寸 l l l、初始机械手高度 h r o b o t h_{robot} hrobot、物体提升高度 h l i s t h_{list} hlist、场景中最大物体数量 n m a x n_{max} nmax。
定义[0,1]之间的小数 λ \lambda λ来线性化获取每次训练的参数,当本次训练后的agent在多次epsilon(1000)的平均成功率达到阈值(0.7)后,再增加参数继续训练。
实验中分了8组参数,即8个难度递增的任务。
2.2 迁移学习
现在复杂度更低的任务上学习一个policy:action设置为xy平移和z轴旋转,z轴平移设置为固定的向下移动,一旦机械手达到预设的高度,闭合机械手并向上提升。reward为二值,成功提升物体5cm时 r = r T r=r_T r=rT,否则 r = 0 r=0 r=0。
训练完该policy后,使用该policy收集数据,然后用行为克隆预训练原始任务的policy,再继续训练原policy。
2.3 网络及优化
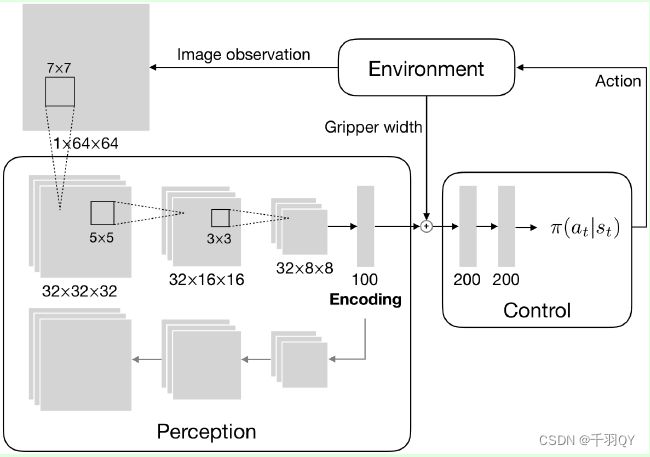
首先使用自编码器训练一个图像编码器,然后与机械手张开宽度合并后进行决策。
自编码器的目的是提取物体的形状、尺寸和距离,因此需要将平面和机械手从图像中去除。下图为RGB原图、去除平面和机械手的深度图标签、自编码器输出的深度图、图形误差:

深度图去掉的地方的值是什么?
训练该自编码器的数据集包含50000张图像,120epochs。训练完后,在所有实验中使用该编码器权重。
RL框架:TRPO,使用多元高斯分布对policy进行建模,网络输出高斯分布的均值和log标准差。使用tanh激活函数将action限制在[-1,1]内。
通过torch.distributions.normal.Normal(均值,标准差)建立高斯分布,然后使用类的sample()函数采样action,使用log_prob(a)计算log概率,从而可以优化TRPO。gym环境可以自动将给定的action阈值化到action空间内。
参考:PPO预测连续action——https://blog.csdn.net/qq_45590357/article/details/122759507
2.4 仿真
pybullet gym,只加载一个机械手而不加载机械臂,避免计算逆运动学,使用仿真相机渲染深度图。
2.5 迁移到真实机器人场景
真实深度图像中,图像边缘的噪声更大且有弯曲,机械手旁边的噪声也更大,因此使用椭圆形mask过滤掉图像边缘,使用膨胀mask过滤掉机械手手指,使用RANSAC方法去除掉平面。最终只保留含噪声的物体区域。
3 实验
仿真实验:
进行了五组实验:reward shaping、reward shaping和课程学习组合、原始稀疏reward和课程学习组合、、将简单任务上训练的policy行为克隆到复杂任务后继续训练。下图展示了训练曲线,横轴是与环境交互的step数量,纵轴是成功率:
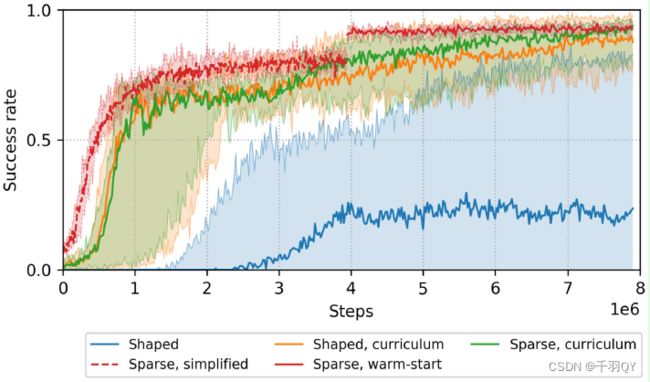
在不同任务下的性能比较如下:

课程学习的成功率是在不同难度的任务上评估的,所以在 1 ∗ 1 e 6 − 3 ∗ 1 e 6 1*1e6-3*1e6 1∗1e6−3∗1e6期间,成功率都在0.7附近, 3 ∗ 1 e 6 3*1e6 3∗1e6之后在最终任务上持续训练,成功率持续上升。
在简单任务上训练的policy也是在简单任务上测试的,成功率比在复杂任务中的更低的原因是,机械手有时在到达预定高度(用来激活抓取动作)前速度过慢,作者设定的碰撞检测程序直接把任务中断了(避免浪费时间)。
结果表明,课程学习比reward shaping效果好太多。
最好的组合是:reward shaping + 课程学习。
与迁移学习的agent相比,从头开始学习的agent学到了一个有趣的行为:当抓取失败时,机械手抬高以避免视野中没有物体,从而提高抓取成功的机会;迁移学习的agent产生了向下移动机械手的严重倾向。
单纯的BC会导致机械手在与物体对齐后不会闭合机械手,因为简单任务中闭合机械手是由启发式程序激活的。
课程学习的消融实验:
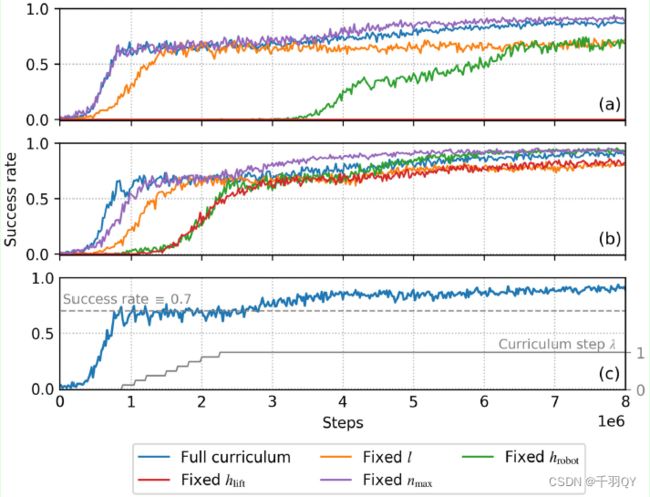
如果在课程学习过程中,始终将提升高度 h l i f t h_{lift} hlift设置为最大值,对结果影响很大;尤其是使用原始reward时,固定 h l i f t h_{lift} hlift导致根本无法收敛,因为直接提升到最终高度的概率非常小。
固定机械手初始高度 h r o b o t h_{robot} hrobot使收敛缓慢,最终成功率也有点下降。
固定物体放置范围 l l l对收敛速度和最终成功率都有影响,但影响不大。
固定物体数量 n m a x n_{max} nmax对结果几乎没影响。
真实场景实验:
对比了在仿真实验中表现好的三个模型:原始reward+课程学习、reward shaping+课程学习、原始reward+预训练(迁移学习)。
当关节角速度过高时,中断任务。
成功率下降较多是因为:(1)仿真中抓物体边缘也可以抓住,但是真实场景会抓取失败;(2)机械手与物体交互时可能触发安全机制。
原始reward+预训练 比 原始reward+课程学习的成功率高, 因为启发式的碰撞检测引导agent向下运动,导致reward=0。(没懂)
由于深度相机噪声,机械手有时在达到可抓取的深度前就闭合了,导致抓取失败。
4 总结
尽管迁移到现实场景中的抓取成功率只有78%,但是通过更好的sim-to-real方式能提高。
平移的action使运动有点不稳,policy预测速度或扭矩会使运动更平滑。
文中的深度图像过滤是建立在物体放置在平面的假设上,导致本文方法在其他场景不一定成功,但眼在手上的相机安装方式使方法的泛化性更好,因为机械手和物体的相对位姿对于选择action是重要的(眼在手外也可以吧)。
不同场景需要不同的相机位置。