机器学习学习笔记(吴恩达)(第三课第一周)(无监督算法,K-means、异常检测)
欢迎

聚类算法:
无监督学习:聚类、异常检测
推荐算法:
![]()
![]()
强化学习:



![]()
聚类(Clustering)
聚类算法:查看大量数据点并自动找到彼此相关或相似的数据点。是一种无监督学习算法
![]()
聚类与二院监督学习算法对比:

![]()


无监督:(聚类是无监督学习算法之一)
![]()



聚类算法应用:如相似的新闻文章组合,市场细分,DNA数据分析,天文数据分析(星系、天体结构)


K-means算法
是一种常用的聚类算法
原理概述
【K-means工作原理过程】(会重复执行一个过程)
1.随机猜测集群的中心(即簇质心)的位置,遍历每一个点,并看它是接近两个簇质心中的哪个(如上图中红叉还是蓝叉)将这些点分配给 与它更接近的那个簇质心(如下图中为每个点标明颜色)
2.分别计算当前 蓝色和红色所有点的平均值(即对应位置),将 上一步的两个簇质心分别移动到 计算后的两个平均值处,得到新的簇质心的位置。根据新的簇质心位置 与各个点之间的距离,重新 为每个点分配类别(即标记颜色)
3.重复步骤2
【注】实际可能有k个类别,并不只适用于二分类问题
簇(聚类簇、cluster):由聚类所生成的一组样本的集合。同一簇内样本彼此相似,与其他簇中的样本相异
簇质心:即聚类中心、聚类质心,簇的中心
举例:有30个点

随机

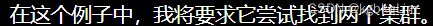
![]()
先初步随机选两个点,分别作为两个集群的可能的中心

![]()
簇(聚类簇、cluster):由聚类所生成的一组样本的集合。同一簇内样本彼此相似,与其他簇中的样本相异
簇质心:簇的中心
【K-means工作原理过程】(会重复执行一个过程)
1.随机猜测集群的中心(即簇质心)的位置,遍历每一个点,并看它是接近两个簇质心中的哪个(如上图中红叉还是蓝叉)将这些点分配给 与它更接近的那个簇质心(如下图中为每个点标明颜色)
2.分别计算当前 蓝色和红色所有点的平均值(即对应位置),将 上一步的两个簇质心分别移动到 计算后的两个平均值处,得到新的簇质心的位置。根据新的簇质心位置 与各个点之间的距离,重新 为每个点分配类别(即标记颜色)
3.重复步骤2
step1:



离红色簇质心近的点标记为红色,同理蓝色

step2:
查看所有红点并取他们的平均值,并将 红叉(即该红色类的簇质心)移动到该平均值处的位置(同理蓝点和蓝叉)
![]()

然后继续这个查看所有点并看其是否更接近 其对应的类别的新的簇质心的位置,此时 原来标记为某类颜色的点可能会变为另一类(因为 簇质心的位置发生了变化)


重复2的过程

直到
![]()


注:下个视频讲解如何计算 某类所有点的平均值位置
K-means算法具体过程
muk:为第k个类别的示例点的 聚类质心
如下例中,mu1和mu2是和 所有训练示例一样维度的向量


![]()
![]()


mu1和mu2是和 所有训练示例一样维度的向量

然后按照上一小节的过程开始执行

当共有m个训练示例、分类的类别为k时,c(i)为第i个训练示例xi对应的类别索引(i=1 to m)。
如举的例子中有30个训练示例,则 m=30, 每个训练示例是 x(1),…,x(30)
计算每个训练示例xi到各个类别(共k类,如此例中k=2)的聚类质心muk的距离,并对于每个训练示例,找到 其 到某个聚类质心距离最短的 对应的那个类别,将该类别设为c(i)
实际计算过程中,用的好像是 距离的平方(因为更好计算,本质是一样的)
n=2的意思是 好像对于每个 x(i)特征向量中,都有两个元素 如x(i)=(a,b) 即下图中坐标轴的横纵轴



计算距离采用L2范数(欧几里得范数)

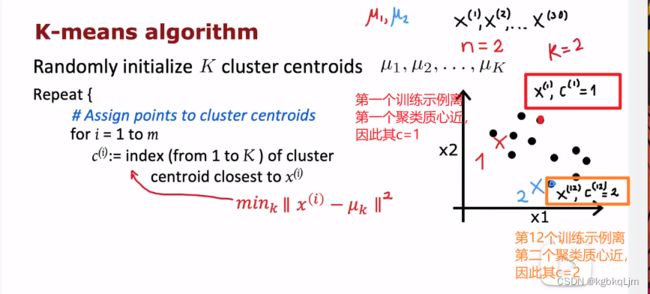
下一步:
计算每个类别示例的 聚类质心(即分别计算 每个训练示例每个维度上元素和的平均值(如下图中每个训练示例是二维的,即(a,b),如下图中就是计算每个属于1类(即红色)的示例的横坐标之和的平均值,同理另一个维度 即纵轴)

![]()

同理计算其他类别,如蓝色的横纵轴
![]()



【极端情况下可能某个类别 一个示例都没有,最后计算出的 聚类质心在原点】则此时:
方式一(更常用):取消该类别,此时是k-1个类别(簇),如下图中右上角的k=k-1
![]()
方式二:如果一定要保持k个类别,则重新随机初始化该集群的质心

对于不那么好分离的簇,K-means也适用
例子:设计师划分短袖的尺码标准SML(如下图中右边图)

![]()




K-means的成本函数(亦称 失真函数distortion function)
【作用】通过成本函数 是不是 减小至保持不变,为我们提供判断 k-means收敛的依据
【背景】
![]()
【k-means的成本函数J】

【变量解释】
c(i)为第i个训练示例xi对应的类别索引
muk是第k个类别的聚类质心
muc^(i)^是第i个训练示例所对应(或者说为其分配的)的类别的聚类质心(的位置)
m:共m个训练示例

下图中的成本函数J(在有些文献中也称为失真函数Distortion function):所有样本点到它所属类的距离的平方 的平均值
算法的执行过程中会 更新c(1) … c(m) 和 mu1…muk 以降低J

【深入理解,及 为什么要最小化上面的成本函数J】
J的参数中的第一部分( c(1)…c(m),即 “k-means中 为示例点分配不同 聚类质心”一步 ),定义不同的c(i) 即为示例取不同的类别,会影响该示例到 类别聚类质心的距离,从而影响成本函数
J的参数中的第二部分( mu1,…,muk, 即 "不断计算同一类别示例的平均值 以调整聚类质心位置"一步)

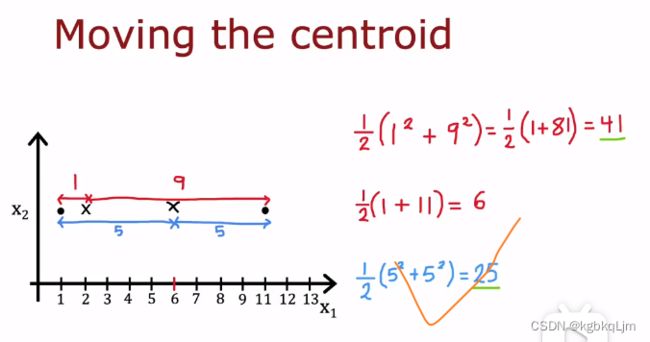
下图为了解释上图中 参数的第二部分,即 选择不同的 聚类质心, 当 取平均值时计算距离最小
(博主)


下节讲述,将 聚类质心随机初始化 可以实现更好的k-means
K-means聚类质心初始化(μ)
【背景及目的】



以找到更好的k-means分类
【正文】
最终聚类的总数k < 训练示例数量m,才有意义。此处举例k=2,m=30
【选择聚类质心的常用方法】随机选择k个训练示例作为 初始的聚类质心(如下图中红叉和蓝叉)(而不是选择某k个特定的训练示例)

当k=3时,举例:当 进行多次随机初始化时,可能得到不同的 聚类质心初始化位置, 一旦质心选不好,可能陷入局部最小值(局部最优)(如下图中的 右下角两个图)。
解决方式: 分别计算出 不同随机初始化聚类质心后 对应的成本函数J,选择其中的min对应的那种

【结论】
经过一定次数的随机初始化后,选择 成本函数最小 对应的那种 聚类质心方式

(博主)


选择聚类数量(k)
聚类数量:即最后要将数据分成多少类
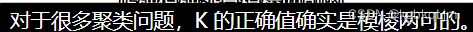
![]()
如下图中,分成两类或四类都有道理
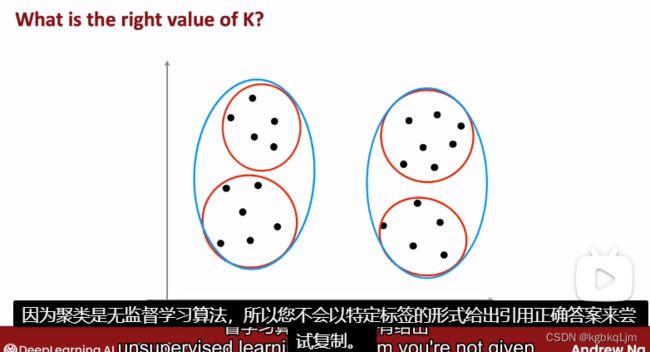

(博主) 老师通常不用肘部法确定聚类数量k
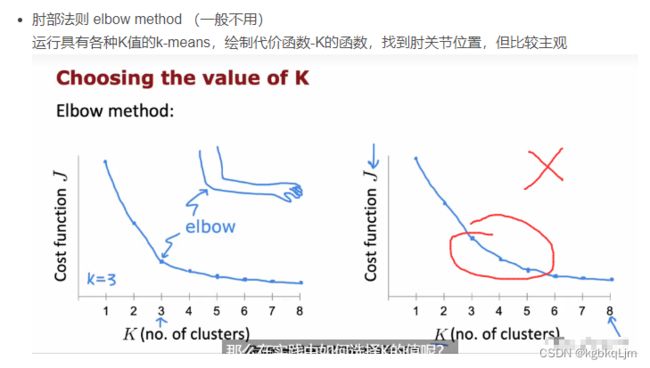
确定聚类数量的常用方法:看 你后续的任务或目的,结合实际需求和成本
例如基于k-means压缩图像时(有作业), 综合考虑图像所占空间和图像质量 以确定图像压缩的程度

作业链接:https://blog.csdn.net/m0_56607174/article/details/126512061
异常检测(Anomaly detection)
是一种无监督学习算法
【个人概述】就是通过概率密度估计方法(如高斯分布)计算一种情况(即一个特征,特征中可能含有n种具体特征)出现的概率,如果该概率
发现异常事件
density estimation:密度估计
【密度估计】异常检测中的密度估计是指根据已知数据集的分布情况,推测新的样本数据在该数据集中的概率分布,并利用这种概率分布来判断样本是否异常。
举例:
检测正在制造的飞机发动机存在的问题(此处为了方便仅以这两个特征为例)
计算发动机的不同特征
x1:发动机产生的热量
x2:震动强度
数据集共m台
roll off the assembly line:从流水线滚落(应该是装配完成)


数据集中每个元素都是一个 二维向量(横坐标是产生的热量,纵坐标是振动强度)
anomaly:异常[əˈnɑːməli]
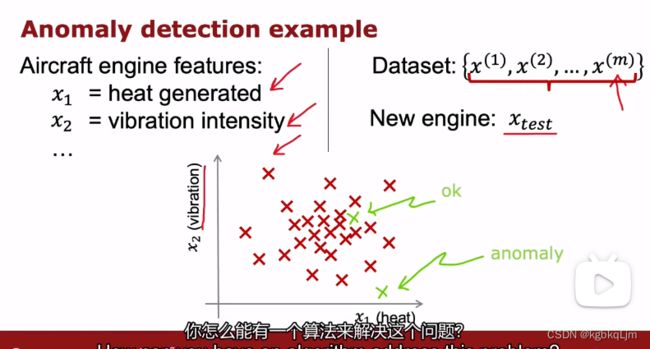
【实现异常检测的常用方法】密度估计
首先为 特征x的概率建立一个算法模型(具体建立方法建后面几节的内容,暂时感觉就是概率论中学的概率密度函数)。 该算法模型能划分出 某个特征出现概率的高低,如 画下图所示的椭圆,能 最终判断或估计出 某种特征出现的概率高低
不同椭圆圈中的概率不同。(某特征(此处 就例如某种发动机对应的二维特征)出现的概率,具体解释可以看下节的p(x)解释)





密度估计模型:相当于 设定了个很小的数或阈值epsilon,当 新的特征向量(待检测的特征)xtest的概率p大于该阈值时,认为不会出现异常(为ok)

【异常检测的应用场景】
欺诈检测
互联网用户行为检测:如下图中 x(i)是用户i一些活动、行为的特征。根据这些可以对 用户的典型行为进行建模
制造业:同理也可以应用于制造业(如判断 某些制造的设备产品是否存在异常)
监视集群和数据中心的计算机:CPU运行情况、负载情况、流量等,被黑客入侵等
欺诈性金融交易
![]()




![]()

![]()

(博主)

下面将如何建立概率估计模型(暂时感觉就是概率论中学的概率密度函数)
(单个数字、特征)高斯分布(正态分布)(Gaussian (Normal) Distribution)
x是一个数字,如果x(为某值?)的概率可以由 均值为mu、方差为sigma的平方 的高斯分布给出(sigma为标准差,sigma的平方为方差),则其曲线如下


【p(x)的含义】
当你有少部分的示例时,获取得不到下图的曲线;当你有 接近无限量的样本时,可以得到下图所示的曲线规律
看着像钟形,因此 左边曲线也被称为钟形曲线



【下面看一下 均值mu和标准差sigma是如何影响高斯分布的】


【高斯分布应用到异常检测】
此处只是举例 数据集(共m个示例)中的每个示例x(i)是单个数字(即 只对某一种特征进行异常检测),实际上可能有很多种特征,即x(i)是多维特征向量(具体见下节)
使用1/m或1/m-1作为系数没有本质区别

(补充)
高斯分布:

概率密度函数:

(博主)

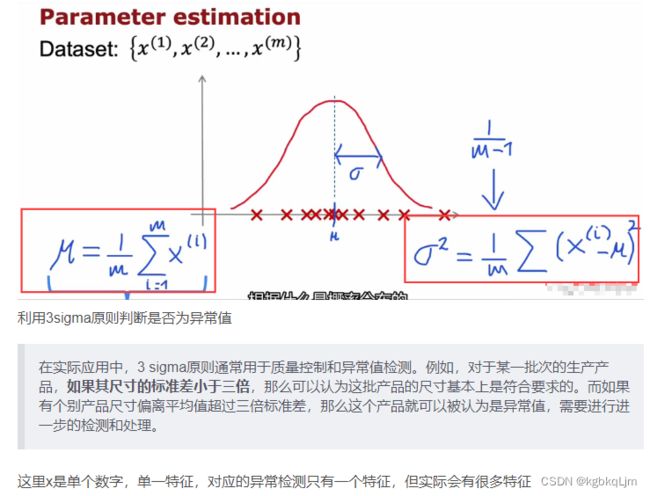
异常检测算法公式及细节
![]()
上节讲的是 训练集中的元素是 单个数字(即 只考虑 单个特征),本节 考虑多个特征(以 飞机发动机为例,考虑 两种特征,n=2)


尝试建立一个密度估计模型,判断 任意一个给定的特征向量的概率

在统计学中,当给定的一个特征向量中的n种特征之间是相互独立时,可以 写成下面
(但老师说,事实证明 这些特征即便不是独立的,算法也能正常工作,即也可以写成 概率乘积的形式)



对特征向量x的不同特征建模时的 mu和sigma不同
当对x1(例如是飞机发动机例子中的热量特征)进行概率建模时,mu1和sigma1对应于 热量特征的均值和方差


对x2(例如是飞机发动机例子中的振动特征)建模时,mu和sigma对应于震动特征的 均值和方差
![]()
![]()
如果特征向量有n维特征,对于x3,…,xn的概率 p(x3 ; mu3, sigma3^ 2),…, p(xn ; mun, sigma n^ 2)也是同理

【结论】如何构建异常检测系统 x1特征比x2特征取值范围大得多 左下角图片中 任一点的高度=p(x1)*p(x2) 即取到该点特征(x1, x2)的概率 (博客) 实数评估:如果有一套评估系统通过返回一个实数来评估你的算法,一个系统即使在开发过程中,也可以做出决定和改进。 举例:飞机发动机 假如10000个正常的发动机样本(表示为y=0),20个异常的发动机样本(表示为y=1)(通常异常样本很少) 另一种异常检测算法(如下图中):在已知的异常样本更少时,尤其是像如下图中的20变成2个,没有能力创建测试集,所以只有训练集和交叉验证集(优化参数),缺点是使用交叉验证集的结果作为评估结果是不客观的(因为你没有测试集)。(但这是 当你仅有很少量的样本 尤其是很少量的异常样本时 的最佳方式) 【具体评估】 【当数据具有倾斜数据集的特点时】 方式二:也可以通过查看算法在 交叉验证集上的效果来 调整参数epsilon 【个人总结】 假如我们有带标签的数据,如果我们有已知的是异常的例子,还有一些已知正常的例子,如何选择使用异常检测方法还是监督学习的方法? 【正例样本数量少、负例样本很多时,用异常检测(此时正例就是 异常,正例是 你的目标,例如异常检测的正向目标就是检测异常)】正常例子数量很少(记住y=1时这些例子为异常样例),那么你可以考虑使用一个异常检测算法。典型情况下,我们有 0 到 20 个,可能最多到50 个正样本,通常情况下,我们只有非常少量的正样本,因此正样本仅用于 cv集和测试集中的参数调整了 【没有足够正样本时】未来可能出现的异常看起来可能会与已有的截然不同(没有足够的正样本用来学习),所以可能在正样本中,你可能已经了解 5 个或 10 个或 20个航空发动机发生故障的情况,但是可能到了明天,你需要检测一个全新的集合、一种新类型异常、一种全新的飞机发动机出现故障的情况,而且之前从来就没有见过。如果是这样的情况,那么我们就更应该对负样本用高斯分布模型 【足够多的正样本和负样本时(或即便只有20个正样本时),使用监督学习】有足够数量的正样本或是一个已经能识别正样本的算法,尤其是,假如你认为未来可能出现的正样本与你当前训练集中的正样本类似,那么这种情况下使用一个监督学习算法会更合理,它能够查看大量正样本和大量负样本来学到相应特征,并且能够尝试区分正样本和负样本(从正样本y=1中学习)。 总结: 当遇到一个特定问题时,我们应该能够判断出是用异常检测算法还是监督学习算法。二者的关键不同在于,在异常检测中,我们通常只有很少量的正样本(异常检测中的正样本即 出现异常的样本,y=1),因此对于一个学习算法而言,它是不可能从这些正样本这学习到足够的知识的,所以我们要做的是使用大量负样本,试图学出未出现过的全新正样本,从那些负样本中学习 p(x) 的值,比如说是飞机发动机故障的情况,我们保留小数量的正样本,用来评估我们的算法,这个算法用于交叉验证集或测试集。 应用异常检测时,其中有一个因素对运行有很大影响,那就是使用什么特征,或者说选择什么特征来实现异常检测算法。 特征选择很重要,特征选择对于异常检测来说 甚至比 其对于监督学习方法更重要 通常来说,我们选择特征的方法是选择那些特别大或者特别小的特征(那些很可能异常的样本中) 【选择的特征是呈高斯分布的 可有效帮助异常检测算法(如果不是,则将其通过各种转换变换的方式向高斯分布进行靠拢和转化)】确保选择的特征是或近似于高斯分布,或者转换数据使其近似于高斯分布。 代码举例:(多尝试几种方式以找到最接近高斯分布的变换方式) 还存在一些自动检测原始分布与高斯分布相似程度的算法,但是实践表明,上述方式已经足够了。 【概述】感觉和之前监督学习部分学的误差分析类似,重点关注算法做的不好的地方,即那些 预测出错的样本(特征) 可能存在这种情况:某示例确实是异常情况,但是 其和示例集中的其他示例相差不大,即 该异常示例出现的概率也不是特别低(如下图 虚线的点) 【个人概述】直接看某些 基本的特征 并没觉得有异常,但是可以将这些特征组合起来得到新的特征, 基于这些特征进行 异常检测建模(如下图中x5= x3/x4) 举例:数据中心计算机的异常检测 数据中心的监控计算机的特征,包括占用内存x1,磁盘每秒访问次数x2,CPU 负载x3,网络流量x4。假如猜测正常计算机CPU 负载和网络流量应该互为线性关系,如我们运行了一组网络服务器,如果其中一个服务器正在服务很多个用户,那么CPU负载和网络流量都很大。但有一台计算机CPU负载升高,但网络流量没有升高,可能的出错情形是我们的计算机在执行一个任务或一段代码时,进入了一个死循环卡住了,因此CPU负载升高,但网络流量没有升高,因为只是CPU执行了较多的工作,所以负载较大,卡在了死循环里。 所以创造两个特征的比值作为用于监测的新特征:
1.确定出可以用于异常检测的有指导意义的特征xi
2.确定用于估计第j个特征的 均值muj和方差sigmaj2 (其中1<=j<=n)
注:如果是向量化实现的特征,也可以用下图中右下角红框公式计算mu(其中x和mu都是向量)
此时通过在未标记的训练集上估计这些mu和sigma,已经的得到了模型的所有参数
3.此时如果有一个新的示例x,计算x的概率p(x) 注:代入高斯分布公式
4.判断是否p(x)

【看一下在示例中的实际含义】
(方差数值越大,说明这组数据的分散程度越大)

对于两个样本x(1) test和x(2) test





开发与评估异常检测系统(如何选择ε)
(感觉就是通过量化指标的方式 来反映当前算法的效果)


下面拆分集合:
将6000个作为训练集,并假设全部为正常样本(因为极少数异常样本不会影响结果)。
2000个作为交叉验证集,其中要包含10个已知的异常样本(y=1)。
2000个作为测试集,其中要包含10个已知的异常样本(y=1)。
当准备好训练集、验证集和测试集后:
1.在训练集上训练模型。
2.在交叉验证集上优化参数 ε ,让算法更可靠;测试保留或去掉某个特征xj时算法的效果。
3.将测试集的结果当做最终评估指标。
这仍然是无监督学习算法,因为训练集是无标签的(或者 即便认为它是有标签的,标签也均为y=0,即尽管我们假设其都是正常的)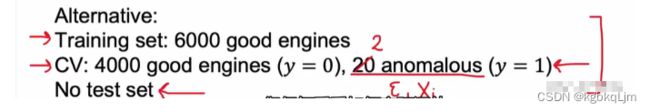
下面详细看一下 如何实际评估一下 在交叉验证集或测试集上的算法:
首先在训练集上拟合 模型p(x) (如上面的例子 训练集有6000个样本),
然后在任意的交叉验证集示例或测试集示例上计算p(x), 并根据下图的计算结果与 该示例的实际类别进行比较,以查看算法的效果。
方式一:类比之前的第二课第三周选修部分的 衡量指标(Recall、Precision)、倾斜数据集部分,当 此处的数据也是倾斜数据集时(即 负例数远小于正例数 ,如下图的10<<2000),可以考虑用 TP、FP、FN、TN、Precision、Recall、F1-Score等指标来衡量算法的效果
metric:度量指标

![]()


![]()





![]()



异常检测与监督学习对比(没太看懂)
当 目标是检测出某些问题时,如果 该问题的样本数量很少 且可能很快就有新的类型出现、比较不固定、以一种全新的方式出现(如黑客攻击、飞机引擎的新类型缺陷),那么用异常检测;
如果有足够的正样本且类型相对固定,比如 制造手机可能出现很多问题且异常类型相对固定(如天气预报,无非就那几种天气类型;或 基于症状判断患者是否某种疾病)。
异常检测试图找到全新的正样本,这些正样本可能是之前没出现过的类型;监督学习会查看已有的正样本并尝试确定 待测示例是否和之前的正样本相似
p(x) 来建模,而不是费尽心思对正样本建模,因为明天的异常可能与迄今为止见过的情况完全不同。
【二者的应用】

选择使用什么特征



![]()
![]()
选择呈高斯分布的特征(或能通过变换 转变为高斯分布的特征)
【注意】如果要进行转换变换,对交叉验证集和测试集的数据要采用相同的变换方式
(用呈高斯分布的特征的异常检测模型时,有更大的概率去很好的拟合数据)
【举例】原特征非高斯分布 但可以通过变换向高斯特征进行转化:
如 对原特征取log(如下图x1 -> logx1)
或 用新的特征替换它(如下图给定x2,则取 log(x2+C))
或 取几次方根(如下图x3 1/2、x41/3)
![]()
![]()

原输入特征:

尝试平方根:

尝试0.4次方,此时更接近高斯:

尝试用log:

通过误差分析步骤来得到异常检测算法的特征
通过一个误差分析步骤,这跟之前讨论监督学习算法时误差分析步骤是类似的,先完整地训练出一个算法,然后在一组交叉验证集上运行算法,然后找出那些预测出错的样本,并看看我们能否找到一些不寻常的可能使预测出错的新特征来帮助学习算法,然后添加此特征,使该样本与其他样本区分开,提高算法的性能。
此时老师会详细查看一下该异常实例,并 尝试分析并识别出一些有助于 区分异常示例和正常示例 的新特征,然后 在算法模型中添加该新特征,以便提高性能



举例:进行欺诈行为检测,x1特征是交易数量,但是发现某个用户的交易数量没什么异常(仅凭x1特征很难区分出异常和正常),但其打字速度却快的离谱,此时就可以将 打字速度作为一个新的特征x2用于区分异常和正常,此时 基于x1和x2特征绘制模型曲线 就可以很明显的区分出异常和正常示例
还可以在原有特征的基础上将相关特征进行组合
选择 发生异常时具有特别大的值或特别小的值对应的特征