图片压缩知识
一、图片压缩算法
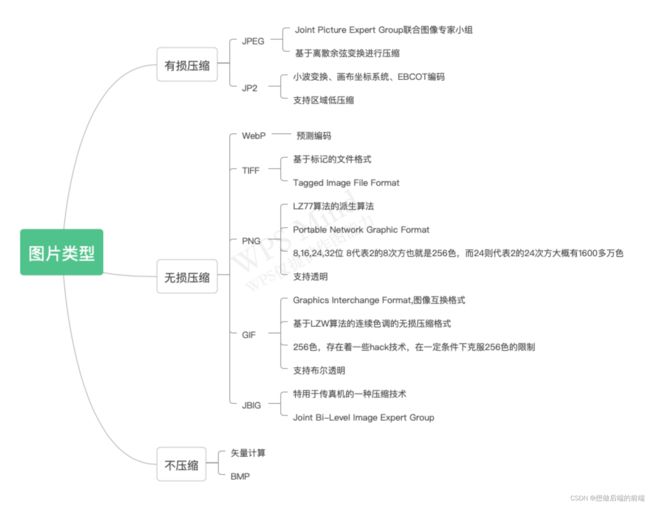
有损算法:
JPEG,我们最为常用的算法。他是通过离散余弦变换,对图片质量尽量小的时候进行有损压缩,该算法对高中波特率下效果很好,但是对低波特率下,就会出现方格之类的,比如100多MB的MPEG电影,会发现稍微一暗就很多格子。为了解决这个问题,提出了JPEG2000标准。
JPEG2000使用了小波变换算法,自称压缩率比JPEG高30%,同时对局部支持不压缩。同时支持先轮廓、模糊逐步清晰的编码(PNG,GIF和JPEG均支持interlace编码),但是目前推广比较差,还没看到支持的浏览器。该算法压缩速度比较慢也是限制其发展的原因。
混合:
Webp,google在推的一种压缩算法,初衷是用于视频压缩。算法原理是预测编码,只有在发生变化(转折)时插入新的数据。同时支持有损和无损压缩。压缩率号称比JPEG高40%但是计算开销也达到8倍。
TIFF,标记型,支持多个图层,每个图层可以是JPEG有损的也可以是PNG等无损的。
无损压缩:
仅仅是对数据进行重复数据的短码方式的压缩。PNG和GIF本质没啥区别,GIF早期本分算法被专利了,所以发展了PNG,但是PNG支持更多的颜色,如果是PNG8基本跟GIF一样了。透明度的支持,PNG8和GIF只支持布尔透明度,PNG16,32支持8位也就是256级的透明程度。理论上PNG24不支持透明,但是目前还是发现有些库支持部分不支持。PNG24,24位色彩,也成为真色彩,相当1600W颜色,已经是人眼能分辨的最高级了。
不压缩:
矢量图,缩放或者放大都不会影响其平滑度,不是所有的字体都是TrueType之类的矢量图的。
BMP,bitmap,每个像素8bit,从下往上扫描。
二、数字图像处理
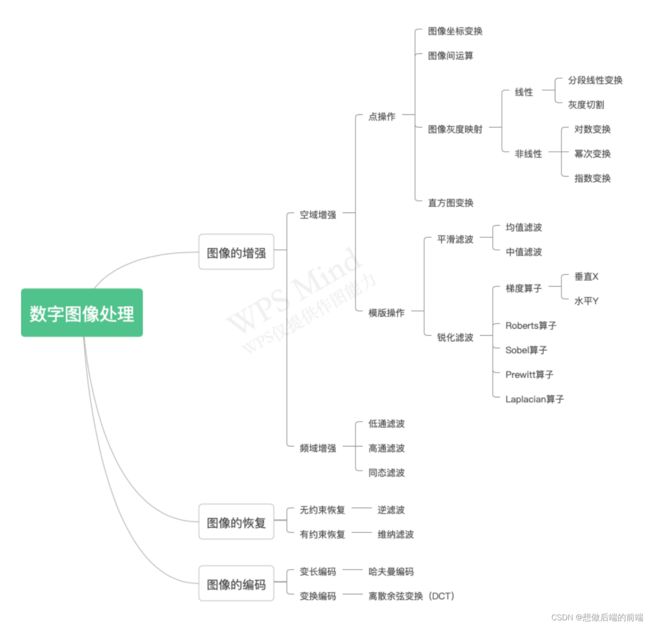
详细信息请看我的资源
三、图像压缩原理
1 图像可压缩的原因
一张原始图像(1920x1080),如果每个像素32bit表示(RGBA),那么,图像需要的内存大小
1920x1080x4 = 8294400 Byte,大约8M。这我们是万万不能接受的。如果这样,1G硬盘才存100多张图片,伤不起啊!视频也一样,如果视频是1920x1080,30fps, 1小时。那不压缩大概需要的内存:
8Mx30x60*60 = 864000M,都800多G了!疯了吧!
所以说,我们需要图像压缩。
常见图像、视频、音频数据中存在的冗余类型如下:
1.1 空间冗余
一幅图像表面上各采样点的颜色之间往往存在着空间连贯性,比如下图,两只老鼠的颜色,背后的墙,灰色的地板,颜色都一样。这些颜色相同的块就可以压缩。
比如说,第一行像素基本都一样,假设亮度值Y是这么存的
[105 105 105…….105],如果共100个像素,那需要1Byte*100。
最简单的压缩:[105, 100],表示接下来100个像素的亮度都是105,那么只要2个字节,就能表示整行数据了!岂不是压缩了!
1.2 时间冗余
这种冗余主要针对视频。
运动图像(视频)一般为位于一时间轴区间的一组连续画面,其中的相邻帧往往包含相同的背景和移动物体,只不过移动物体所在的空间位置略有不同,所以后一帧的数据与前一帧的数据有许多共同的地方,这种共同性是由于相邻帧记录了相邻时刻的同一场景画面,所以称为时间冗余。
1.3 视觉冗余
人类的视觉系统由于受生理特性的限制,对于图像场的注意是非均匀的,人对细微的颜色差异感觉不明显。
例如,人类视觉的一般分辨能力为26灰度等级,而一般的图像的量化采用的是28灰度等级,即存在视觉冗余。
人类的视觉觉对某些信号反映不太敏感,使得压缩后再还原有允许范围的变化,人也感觉不出来。
2 图像压缩编码举例
2.1 行程编码(RLE)
这是最好理解的一种编码了。
现实中有许多这样的图像,在一幅图像中具有许多颜色相同的图块。在这些图块中,许多行上都具有相同的颜色,或者在一行上有许多连续的像素都具有相同的颜色值。在这种情况下就不需要存储每一个像素的颜色值,而仅仅存储一个像素的颜色值,以及具有相同颜色的像素数目就可以,或者存储像素的颜色值,以及具有相同颜色值的行数。
这种压缩编码称为行程编码(run length encoding,RLE),具有相同颜色并且是连续的像素数目称为行程长度。
例如,字符串AAABCDDDDDDDDBBBBB
利用RLE原理可以压缩为3ABC8D5B
RLE编码简单直观,编码/解码速度快,
因此许多图形和视频文件,如.BMP .TIFF及AVI等格式文件的压缩均采用此方法.
由于一幅图像中有许多颜色相同的图块,用一整数对存储一个像素的颜色值及相同颜色像素的数目(长度)。例如:
(G ,L)//G为颜色值,L为长度值
编码时采用从左到右,从上到下的排列,每当遇到一串相同数据时就用该数据及重复次数代替原来的数据串。
举例,如下的18*7的像素(假设只有灰度值,1字节)
000000003333333333
222222222226666666
111111111111111111
111111555555555555
888888888888888888
555555555555553333
222222222222222222
仅仅需要11对数据表示。
(0,8) (3,10) (2,11) (6,7)
(1,18) (1,6) (5,12) (8,18)
(5,14) (3,4) (2,18)
2.2 哈夫曼编码(Huffman)
由于图像中表示颜色的数据出现的概率不同,对于出现频率高的赋(编)予较短字长的码,对出现频率小的编于较长字长的码,从而减少总的代码量,但不减少总的信息量。
编码步骤:
(1)初始化,根据符号概率的大小按由大到小顺序对符号进行排序
(2)把概率最小的两个符号组成一个节点,如图4-02中的D和E组成节点P1。
(3)重复步骤2,得到节点P2、P3和P4,形成一棵“树”,其中的P4称为根节点。
(4)从根节点P4开始到相应于每个符号的“树叶”,从上到下标上“0”(上枝)或者“1”(下枝),至于哪个为“1”哪个为“0”则无关紧要,最后的结果仅仅是分配的代码不同,而代码的平均长度是相同的。
(5)从根节点P4开始顺着树枝到每个叶子分别写出每个符号的代码。
2.3 DCT编码
2.3.1 基本概念
将在空域上描述的图象,经过某种变换(通常采用,余弦变换、傅立叶变换、沃尔什变换等),在某种变换域里进行描述。
在变换域里,首先降低了图象的相关性;其次通过某种图象处理(如频域的二维滤波)以及熵编码,则可进一步压缩图象的编码比特率。
这种变换常用于JPEG图像压缩。
2.3.2 变换压缩原理框图
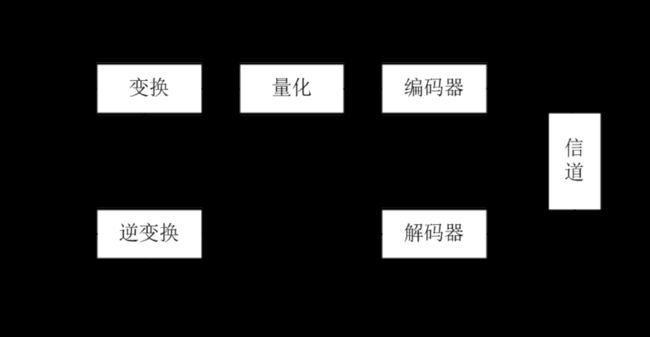
G : 输入源图像
G’ :解码后的图像
U: 二维正交变换
U’ : 二维正交逆变换