【论文精读WACV_2023】FaceOff: A Video-to-Video Face Swapping System
【论文精读WACV_2023】FaceOff: A Video-to-Video Face Swapping System
- 一、前言
- Abstract
- 1. Introduction
- 2. Related Work
- 3. FaceOff: Face Swapping in videos
-
- 3.1. Merging Videos using Quantized Latents
- 3.2. Self-supervised Training Approach
- 3.3. Reproducing Inference Errors at Training
- 4. Experiments and Results
-
- 4.1. Face-Swapping Results
- 4.2. Target Face Manipulation Results
- 5. Ablation Study
- 6. Conclusion
一、前言
Aditya Agarwal, Bipasha Sen, Rudrabha Mukhopadhyay, Vinay Namboodiri, C.V. Jawahar
【Paper】 > 【Code】 > 【Project】
论文贡献:
(1)引入了V2V面部交换,这是一种新颖的面部交换任务,旨在交换源面部身份和表情,同时保留目标背景和姿势。
(2) 提出 FaceOff:一种以自我监督方式训练的 V2V 换脸系统。 FaceOff 通过合并两个不同的面部视频来生成连贯的视频。
(3) 该方法在推理时直接作用于没见过的身份,无需任何微调。
(4) 该方法不需要任何推理时间优化,推理时间不到一秒。
(5)发布了V2VFaceSwap测试数据集,并为V2V换脸任务建立了基准。
创新点是旧方法新任务
Abstract
背景介绍:双打在电影界扮演着不可或缺的角色。他们在危险的特技场景或同一演员扮演多个角色的场景中代替演员。随后,利用昂贵的 CGI 技术,将替身的脸部和表情手动替换为演员的脸部和表情,耗资数百万美元,耗时数月才能完成。一种自动化、廉价且快速的方法可以是使用面部交换技术,该技术旨在将身份从源面部视频(或图像)交换到目标面部视频。然而,此类方法无法保留对场景上下文很重要的演员的源表情。
工作介绍:为了应对这一挑战,我们引入了视频到视频(V2V)面部交换,这是一种新颖的面部交换任务,可以保留(1)源(演员)面部视频的身份和表情以及(2)背景以及目标(双)视频的姿势。
我们提出了 FaceOff,这是一种 V2V 面部交换系统,它通过学习鲁棒的混合操作来按照上述约束合并两个面部视频。它将视频减少到量化的潜在空间,然后将它们混合在减少的空间中。 FaceOff 以自我监督的方式进行训练,能够稳健地解决 V2V 换脸的重大挑战。
实验:如实验部分所示,FaceOff 在质量和数量上都显着优于其他方法。
1. Introduction
有双打对于电影中的主演来说是电影制作中不可缺少的组成部分。
在涉及困难和危险的危及生命的特技场景中,替身可能会代替演员的位置。他们甚至可以在常规填充场景或多次重拍中代替演员。
例如,《社交网络》广泛使用替身作为演员 Armie Hammer 的替身,后者扮演了双胞胎兄弟的多个角色。
在这样的场景中,替身的脸随后被演员的脸和表情所取代,并使用 CGI 技术,需要在繁重的图形单元上进行数百小时的手动多媒体编辑,耗资数百万美元,并需要数月才能完成。
因此,制作团队通常被迫通过改变场景的机制来避免此类场景,使得仅捕捉替身的身体以提供演员的幻觉。这可能会限制导演的创造力。然而,这种调整并不总是可行的。
另一种情况是后期制作场景修改。如果在后期制作中发现对话比原始场景更适合场景,则整个场景将被重置并重新拍摄。
我们建议演员可以在录音室录音,并将他们的脸叠加在之前的录音上。
事实上,和其他行业一样,电影行业也正朝着演员可以在家工作的方向发展。在当今时代,CGI 技术可以产生令人难以置信的人体结构、场景和逼真的图形。然而,众所周知,他们很难创造出逼真的皮肤。
如图1所示,演员可以在舒适的家中或工作室中展现自己的身份和表情,而将繁重的任务留给图形或替身。
此类任务所需的 CGI 技术需要手动操作、昂贵且耗时。
为了自动化此类任务,基于快速且廉价的计算机视觉的面部交换 \cite{deepfacelabs,motion-coseg,fsgan,faceswapdisney,faceshifter,faceswapphotos}技术,旨在在源(演员)视频和目标(双)视频可以考虑。然而,此类技术不能直接使用。换脸仅交换源身份,同时保留目标视频的其余特征。在这种情况下,演员的表情(源)不会在输出中捕获。
为了解决这个问题,我们引入了“视频到视频(V2V)面部交换”作为面部交换的新颖任务,其目的是 (1) \textbf{(1)} (1) 交换源面部视频的身份和表情和 (2) \textbf{(2)} (2)保留目标人脸视频的姿势和背景。
目标姿势至关重要,因为它取决于场景的上下文。
例如,特技演员在室外表演,与机器打交道或与替身演员交谈;演员在演播室的绿幕前表演。在这里,替身的姿势是情境感知的,而演员只是即兴发挥。
所提出的任务如何是视频到视频换脸任务? \textbf{所提出的任务如何是视频到视频换脸任务? } 所提出的任务如何是视频到视频换脸任务? 与将固定身份组件从一个视频交换到另一个视频的换脸任务不同,V2V 换脸任务将随时间变化的表情(一个视频)与另一个具有变化姿势和背景的视频(另一个视频)交换,从而使我们的任务视频-到视频。
方法: \textbf{方法:} 方法:在视频中交换脸部并非易事,因为它涉及合并两种不同的运动 - 演员的脸部运动(例如眼睛、脸颊或嘴唇运动)和替身的头部运动(例如姿势和下巴运动) 。这需要一个可以将两个不同的运动作为输入并产生第三个相干运动的网络。
我们提出 FaceOff \textbf{FaceOff} FaceOff,一种视频到视频的面部交换系统,它将面部视频减少到量化的潜在空间并将它们混合在减少的空间中。
训练这样一个网络的一个基本挑战是缺乏基本事实。
面部交换方法 \cite{motion-coseg, fsgan, deepfacelabs} 使用鉴别器-生成器设置来训练网络。
鉴别器负责监视交换输出的所需特性。然而,使用鉴别器会导致输出与输入不同的幻觉成分 - 例如,修改的身份或新的表情。
因此,我们设计了一种自我监督的训练策略来训练我们的网络:我们使用单个视频作为源和目标。然后我们在源视频上引入伪运动误差。最后,我们训练一个网络来“修复”这些伪错误以重新生成源视频。
FaceOff 可以在推理时直接对看不见的交叉身份进行换脸,无需任何微调。
此外,与大多数在高端 GPU 上需要优化推理时间从 5 分钟到 24 小时不等的换脸方法不同,FaceOff 只需一次前向传递即可完成换脸视频,耗时不到一秒。 FaceOff 的一个关键特性是它至少保留一个输入表情(在我们的例子中为源),而正如我们稍后展示的,现有方法无法保留任一表情(源表情或目标表情)。
最后,我们对 V2VFaceSwap 进行策划和基准测试,这是一个 V2V 换脸测试数据集,由来自不受约束的 YouTube 视频中未见过的身份、背景和照明条件的实例组成。
我们在这项工作中的贡献 \textbf{我们在这项工作中的贡献} 我们在这项工作中的贡献如下:(1)我们引入了V2V面部交换,这是一种新颖的面部交换任务,旨在交换源面部身份和表情,同时保留目标背景和姿势。 (2) 我们提出 FaceOff:一种以自我监督方式训练的 V2V 换脸系统。 FaceOff 通过合并两个不同的面部视频来生成连贯的视频。 (3) 我们的方法在推理时直接作用于看不见的身份,无需任何微调。 (4) 我们的方法不需要任何推理时间优化,推理时间不到一秒。 (5)我们发布了V2VFaceSwap测试数据集,并为V2V换脸任务建立了基准。
2. Related Work

表1 提供了现有任务和 FaceOff 之间的比较。 FaceOff 旨在解决 V2V 换脸的独特挑战,这是以前从未解决过的。
面部交换 \textbf{面部交换} 面部交换:多年来,在图像和视频之间交换面部已得到充分研究\cite{deepfacelabs、fsgan、motion-coseg、simswap、fastfaceswap、faceshifter、faceswapdisney、faceswapphotos、3dmodelfaceswapping}。这些工作旨在将从源视频(或图像)获得的身份与不同身份的目标视频交换,以便在交换的输出中保留所有其他目标特征。
DeepFakes,DeepFaceLabs \cite{deepfacelabs },并且 FSGAN \cite{fsgan} 交换源的整个身份;
Motion-coseg \cite{motion-coseg} 专门将给定源图像(头发、嘴唇或鼻子等)的单个/多个片段的身份交换到目标视频。
与这些仅交换图像的身份或特定部分的方法不同,我们交换随时间变化的表情以及源的身份。
此外,FSGAN 需要 5 分钟的推理时间优化,DeepFaceLabs 和 DeepFakes 在高端 GPU 上花费高达 24 小时的推理时间优化。 FaceOff 只需不到一秒即可在野外视频中对未见过的身份进行面部交换。
面部操纵 \textbf{面部操纵} 面部操纵:面部操纵根据给定的先验来对目标图像/视频的姿势和表情进行动画处理 \cite{face-vid2vid、fomm2、fomm、reenactgan、deepfacelabs、flowguided、nvp、makeittalk}。
在音频驱动的说话脸部生成中 \cite{wav2lip, lipgan, wav2lip-emotion,posecont, nvp, pirenderer, vdub},目标视频中的表情、姿势和唇形同步以给定的输入语音音频为条件。与此类作品不同,我们的方法不假设音频先验。
face reenactment \textbf{face reenactment} face reenactment 的不同方向根据驾驶视频 \cite{defererneuralrendering, pirenderer,face2face, deepvideopotraits, fomm, fomm2} 对源面部运动进行动画处理。
在这些作品中,身份并没有被交换。这可以解决我们任务的特殊情况——当目标和源具有相同的身份时。这里,可以根据源视频表情来重新生成目标图像。正如我们在4.2节中所示,与现有方法不同,FaceOff 捕获驾驶视频的微表情。
这是因为我们依赖于混合机制 - 允许驾驶表情的完美转移。
处理这种特殊情况的另一个方向是 人脸编辑 \textbf{人脸编辑} 人脸编辑,它涉及编辑人脸视频的表情。使用这种方法,可以根据源表情直接编辑目标视频。
基于图像的人脸编辑作品例如 \cite{pix2pix,stargan,starganv2,cgan}已经获得了相当多的关注。
然而,在不对时间动态进行建模的情况下对帧序列进行这些编辑通常会导致视频在时间上不连贯。最近,STIT \cite{stit} 被提出,可以通过在视频的潜在空间中进行仔细的编辑,将给定的视频连贯地编辑为不同的表情。
尽管取得了成功,但这些技术对表情类型和变异的控制有限。而且,获得与源表情匹配的正确目标表情是手动点击和尝试。 FaceOff 可以添加标签空间中未定义的微表情,只需将同一身份的不同视频中的情感与所需的表情混合即可。
3. FaceOff: Face Swapping in videos
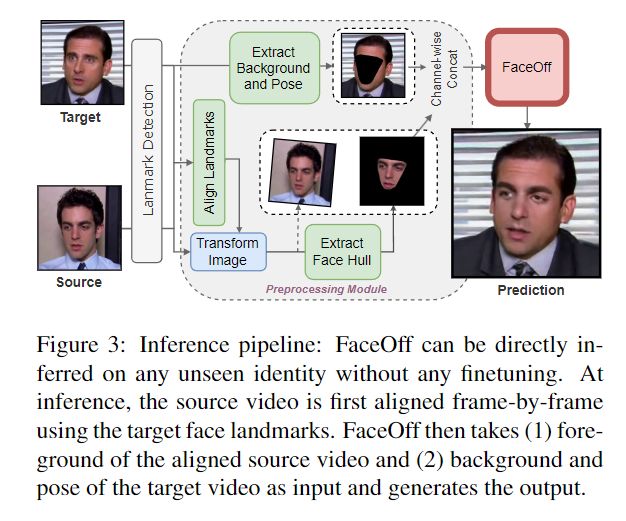
我们的目标是将源面部视频与目标面部视频交换,以便(1)保留源视频的身份和表情,(2)保留目标视频的姿势和背景。为此,我们学习将源人脸视频的前景与目标人脸视频的背景和姿势混合(如图3所示),以使混合输出连贯且有意义。这并非易事,因为它涉及合并两个单独的动议。
请注意,我们的目标只是融合这两种运动;因此,所需的输入特征——身份、表情、姿势和背景——自然地从输入中保留下来,无需额外的监督。主要挑战是对齐前景和背景视频,以便输出形成连贯的身份并具有单一连贯的姿势。所有其他特征都是根据输入重建的。
我们的核心思想是使用时间自动编码模型,使用量化的潜在空间合并这些运动。
总的来说,我们的方法依赖于(1)将两个输入运动编码到量化的潜在空间并在缩减的空间中学习鲁棒的混合操作。
(2)时间和空间相干解码。
(3)在缺乏基本事实的情况下,自我监督的训练方案。
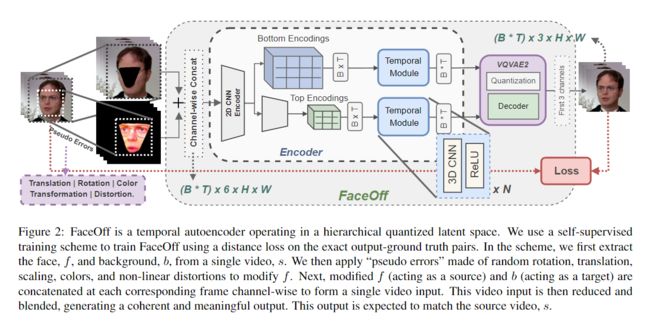
3.1. Merging Videos using Quantized Latents
我们将视频中的换脸作为一个混合问题:给定两个视频作为输入,将视频混合成连贯且有意义的输出。我们依靠编码器将输入视频编码到有意义的潜在空间。我们的整个网络是一个特殊的自动编码器,然后可以学习稳健地混合潜在空间中的缩减视频并生成混合输出。我们仔细选择我们的编码器模型,专注于“混合”而不是学习整体数据分布。具有连续潜在空间的编码器网络减少了给定输入的维度,通常减少到可以被认为是数据的一部分的单个向量。底层分布。这个潜在向量是高度随机的;每个新输入都会生成一个非常不同的潜在向量,引入解码器需要处理的高度变化。最近,\cite{vqvae, vqgan, vqvae2} 中提出了“向量量化” 。量化通过固定可能的潜在代码的数量来减少潜在的变化。然而,使用单个量化潜在向量保留输入属性是不可能的。因此,输入被减少到更高维度的量化空间(例如 64 × 64 64 \times 64 64×64),以便保留完整重建所需的输入属性。我们在我们提出的自动编码器中采用这样的编码器来编码我们的视频。如图2所示,我们的编码器是一个改进的VQVAE2 \cite{vqvae2}编码器,它编码视频而不是图像。为此,我们引入了由非线性 3D 卷积运算组成的时间模块。
我们编码器的输入是通过按通道连接源前景帧和目标背景帧而制成的单个视频,如图3所示。与 VQVAE2 一样,我们的编码器首先将级联视频输入逐帧编码为 32 × 32 32 \times 32 32×32 和 64 × 64 64 \times 64 64×64 维顶部和底部层次结构。在每个层次结构的量化步骤之前,添加我们的时间模块来处理减少的视频帧。此步骤允许网络通过帧之间的时间连接进行反向传播。然后使用标准 VQVAE2 解码器再次按帧进行进一步处理。在实践中,我们观察到这个时间模块在生成时间相干输出方面发挥着重要作用,正如我们通过 Sec.5 中的消融所示。我们的特殊自动编码器在损失计算步骤中与标准自动编码器不同。 FaceOff 不是重建输入,而是使用六通道视频输入(前三个通道属于源前景,后三个通道属于目标姿势和背景),旨在生成三通道混合视频输出。因此,损失计算是在真实三通道视频和三通道视频输出之间进行的。
3.2. Self-supervised Training Approach

现有的换脸方法使用生成器和鉴别器来训练其网络。这些鉴别器是分类器,指示生成器的输出和基础数据分布(例如身份或表情分布)之间的关系。在这样的设置中,鼓励生成器产生输出的某些方面的幻觉,以匹配鉴别器的数据分布,从而使其输出新的身份或表情。我们在Fig.4中展示了这种现象。可以使用指示精确的输出与地面实况关系的硬距离损失(例如,欧几里德距离)而不是随机鉴别器损失来克服这个问题。在V2V换脸中,保留准确的源表情至关重要。因此,我们通过设计一种自监督训练方案来使用距离损失来训练我们的网络,该方案迫使网络重建给定输入视频的去噪版本。
为了理解训练方案,我们首先看看在尝试简单地混合两个动作时遇到的挑战。
首先,源视频和目标视频中的面部之间存在全局和局部姿势差异。我们通过使用人脸地标根据目标姿势对齐(旋转、平移和缩放)源姿势来修复全局姿势差异,如图3所示。然而,局部姿势差异并不能通过这种方式克服,并且我们观察到帧之间的时间不连贯性。接下来,我们观察前景和背景颜色(光照、色调、饱和度和对比度)的差异。因此,我们通过在训练期间重现这些错误来训练我们的网络来解决这些已知问题。如图2所示,
我们通过以下方式训练我们的模型:
(1) 拍摄一段视频,比如 s s s。
(2) 从 s s s中提取人脸区域,比如 f f f;和背景区域,比如 b b b。
(3) 在 f f f上引入伪错误(旋转、颜色、比例等)。
(4) 通过在每个相应帧按通道连接 f f f 和 b b b 来构造输入 v v v。
(5) 训练网络从 v v v构造 s s s。尽管我们在自监督方案中使用相同的身份来训练网络,但它可以在推理时直接交换看不见的身份,而无需任何微调。
3.3. Reproducing Inference Errors at Training
给定两个头部说话视频,源视频和目标视频,分别用 S S S 和 T T T 表示,我们的目标是生成一个输出,保留 (1) S S S 的身份和情感以及 (2) 姿势和背景来自 T T T。我们假设 S S S 和 T T T 中的帧数(用 N N N 表示)相等。给定两个帧, s i ∈ S s_i \in S si∈S 和 t i ∈ T t_i \in T ti∈T,使得 i = 1... N i = 1 ... N i=1...N,我们表示 f s i ∈ F s f_{s_i} \in F_s fsi∈Fs 和 b t i ∈ B t b_{t_i} \in B_t bti∈Bt分别作为 s i s_i si和 t i t_i ti的前景和背景。给定 F s F_s Fs 和 B t B_t Bt 作为输入,网络修复了以下问题:
首先,网络遇到 f s i f_{s_i} fsi 和 b t i b_{t_i} bti 之间的局部姿态差异。这种姿势差异可以使用仿射变换函数来修复: δ ( f s i , b t i ) = m ( r f s i + d ) + m ( r b t i + d ) \delta(f_{s_i}, b_{t_i}) = m(rf_{s_i} + d) + m(rb_{t_i} + d) δ(fsi,bti)=m(rfsi+d)+m(rbti+d) 其中 m m m、 r r r 和 d d d 表示缩放、旋转和平移。面是一个非刚体;仿射变换只会导致两张脸的姿势完美匹配,但形状不匹配。人们可以想象尝试将一个正方形放入一个圆中。首先需要一个非线性函数将正方形转换为类似于圆形的形状,以便它们适合。我们将这种非线性变换表示为可学习函数 ω ( f s i , b t i ) \omega(f_{s_i}, b_{t_i}) ω(fsi,bti)。由于是非线性的,只要两个人脸都适合,网络就可以对输入帧执行此类变换。可以使用距离损失来约束这些变换,以鼓励生成有意义的帧的空间一致的变换。然而,这些空间一致的变换在整个视频中可能是时间不相干的。这将导致视频中的脸部摇晃,如 Sec.5 所示。因此,我们将变换约束为 ω ( f s i , b t i , f s k , b t k ) \omega(f_{s_i}, b_{t_i}, f_{s_k}, b_{t_k}) ω(fsi,bti,fsk,btk),其中 k = 1.. N k = 1..N k=1..N 使得 k ≠ i k \ne i k=i。这里,当前帧的变换受到视频中所有其他帧的变换的约束。这是由时间模块启用的,如 Sec.3.1中所述。
最后,网络遇到 f s i f_{s_i} fsi 和 b t i b_{t_i} bti 之间的颜色差异,该差异被固定为 c ( f s i , b t i ) c(f_{s_i}, b_{t_i}) c(fsi,bti)。
如图2所示,训练时 S = T S=T S=T。对于每个帧 s i ∈ S s_i \in S si∈S,我们首先提取前景 f s i ∈ F s f_{s_i} \in F_s fsi∈Fs (充当源)和背景 b t i ∈ B t b_{t_i} \in B_t bti∈Bt (充当目标) ) 来自 s i s_i si。接下来,我们在 f s i f_{s_i} fsi 上应用随机旋转、平移、缩放、颜色和扭曲(桶状、胡须)错误。然后将训练设置表述为:
Φ : Ω ( δ , ω , c ) J = 1 N ∑ i = 1 N [ s i − Φ ( f s i , b t i , f s k , b t k ) ] + P ( F s , B t ) \begin{gather} \Phi: \Omega(\delta, \omega, c)\\ J = \frac{1}{N}\sum_{i = 1}^{N} [ s_i - \Phi(f_{s_i}, b_{t_i}, f_{s_k}, b_{t_k})] + P(F_s, B_t) \end{gather} Φ:Ω(δ,ω,c)J=N1i=1∑N[si−Φ(fsi,bti,fsk,btk)]+P(Fs,Bt)其中 Ω \Omega Ω 是可学习函数, J J J 是要最小化的网络总体成本, P P P 是感知度量(在我们的例子中为 LPIPS~\cite{lpips}), k = 1 … N k = 1 \dots N k=1…N 使得 k ≠ i k \neq i k=i。
4. Experiments and Results
在本节中,我们尝试回答以下问题:(1)与替代方法相比,我们如何更好地保留源身份? (2)我们如何很好地保留输入视频的表情? (3) 与其他技术相比,FaceOff 的效率如何?
我们将 FaceOff 与不同的任务进行比较:“换脸”、“脸部重演”和“脸部编辑”。请注意,这些方法都不能完全解决我们想要解决的 V2V 换脸任务。具体来说,V2V 换脸的目的是(1)交换源身份和表情,(2)保留目标姿势和背景。
定量指标: \textbf{定量指标:} 定量指标:
(1)S o u r c e − P r e d i c t i o n I d e n t i t y Dis t a n c e (SPIDis) \textbf{(1)} \textbf{S}ource-\textbf{P}rediction \ \textbf{I}dentity \ \textbf{Dis}tance \textbf{(SPIDis)} (1)Source−Prediction Identity Distance(SPIDis):计算人脸图像之间的身份差异。它被计算为使用 dlib 的人脸检测模块生成的人脸嵌入之间的欧几里德距离。
(2)F r e ˊ c h e t V i d e o D i s t a n c e (FVD) \textbf{(2)} \textbf{F}réchet \ \textbf{V}ideo \ \textbf{D}istance \textbf{(FVD)} (2)Freˊchet Video Distance(FVD),如 \cite{fvd} 中提出的,计算生成视频中的时间相干性输出。
(3)L a n d m a r k D i s t a n c e (LMD) \textbf{(3)} \textbf{L}and\textbf{m}ark \ \textbf{D}istance \textbf{(LMD)} (3)Landmark Distance(LMD):评估源和交换输出的整体面部结构和表情。为了计算 LMD,源和交换的面部标志被归一化:面部首先居中,然后绕 x 轴旋转,以便质心和眼睛坐标之间的角度对齐平均图像。接下来,将面部缩放至平均图像。标准化交换和源视频地标之间的欧几里德距离给出了 LMD。我们计算源面部表情和输出面部表情之间的 LMD(不包括面部许可者的地标)。
(4)T e m p o r a l l y L o c a l l y (TL-ID) 和 T e m p o r a l l y G l o b a l l y (TG-ID) Id e n t i t y P r e s e r v a t i o n \textbf{(4)} \textbf{T}emporally \ \textbf{L}ocally \textbf{(TL-ID)} 和 \textbf{T}emporally \ \textbf{G}lobally \textbf{(TG-ID)} \ \textbf{Id}entity \ Preservation (4)Temporally Locally(TL-ID)和Temporally Globally(TG-ID) Identity Preservation:在 \cite{stit} 中提出。他们评估视频在本地和全球层面的身份一致性。对于这两个指标,得分为 1 表示该方法成功地保持了原始视频的身份一致性。
定性指标: \textbf{定性指标:} 定性指标: (1)Identity \textbf{(1)} \textbf{Identity} (1)Identity 的平均绝对意见得分,范围为 1 − 10 1-10 1−10报告:交换输出身份与源身份的相似程度如何? (2) 表情 (Exps.) \textbf{(2)} 表情 \textbf{(Exps.)} (2)表情(Exps.):交换输出表情与源表情有多相似?和 (3) 自然度 (Ntrl.) \textbf{(3)} 自然度 \textbf{(Ntrl.)} (3)自然度(Ntrl.):是生成的输出自然吗?
实验数据集 \textbf{实验数据集} 实验数据集:我们对由不受约束的 YouTube 视频组成的 V2VFaceSwap 数据集进行基准测试,这些视频具有许多看不见的身份、背景和照明条件。补充论文报告了有关数据集和评估设置的更多详细信息。
4.1. Face-Swapping Results
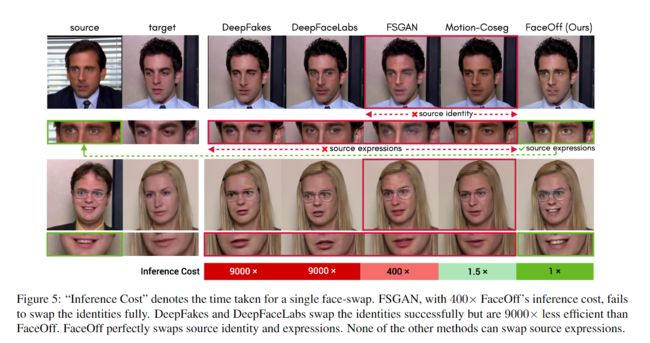

Fig.5和 Table2分别展示了现有方法和 FaceOff 之间的定性和定量比较。 Fig.6演示了 FaceOff 在视频上的换脸结果。
如图5所示,FaceOff成功交换了源人脸视频的身份和表情。现有方法无法交换源表情,这表明 FaceOff 解决了 V2V 换脸的独特挑战。我们实验的一个有趣发现是,现有方法不会在输出中保留任何输入表情(源或目标)并生成新颖的表情,例如新颖的注视方向或嘴巴运动。这种现象也在Fig.4中得到了证明。 FSGAN 和 Motion-Coseg 无法完全交换身份。这通过 Table2中的定量指标得到进一步证实。 FaceOff 在 SPIDis 和 LMD 上比 FSGAN 有 ∼ 22 % \sim 22\% ∼22% 和 ∼ 28 % \sim 28\% ∼28% 的改进,表明 FaceOff 的优越性。
FSGAN 实现了稍微更好的 FVD,并且在人类评估中被认为更自然。这是预期的,因为 FSGAN 不会对目标身份进行太大改变,并保留原始目标视频,使其观察起来更加自然。 FaceOff 几乎完美地交换了身份。此外,现有方法仅需要遵循单个目标运动。 FaceOff 解决了运动到运动交换的另一个挑战,即需要在每一帧上进行源-目标姿势对齐。这需要 FaceOff 生成新颖的动作,使动作中的身份、表情和姿势看起来自然并与输入相匹配。尽管存在这一挑战,FSGAN 和 FaceOff 的 FVD 之间的差异在感知上并不显着 \cite{fvd}。
DeepFaceLabs 和 DeepFakes 可以很好地交换身份,但计算成本比 FaceOff 贵 9000 倍,这使得 FaceOff 在现实世界中更具可扩展性和适用性。
4.2. Target Face Manipulation Results

假设源和目标具有相同的身份,问题就简化为以下内容:将表情从源视频传输到目标视频。这从根本上是“面部重演”的设置。人们还可以通过识别和量化源表情并使用“面部编辑”网络来编辑目标表情来修改目标的表情。图7展示了 FaceOff、“面部重演”(Face-Vid2Vid)和“面部编辑”(STIT)之间的定性比较。
面部重演 : \textbf{面部重演}: 面部重演:
我们与 Face-Vid2Vid \cite{face-vid2vid} 进行比较,这是一种 SOTA 人脸重演网络,它使用源(驾驶)视频重演目标图像的姿势和表情。如图7所示,FaceOff 保留了来源的微表情,例如准确的张嘴和皱眉。 FaceOff 依赖于确定性距离损失,因此它可以在输出中保留精确的输入表情。此外,FaceOff 保留时间目标姿势和背景,而 Face-Vid2Vid 修改静态帧。
脸部编辑: \textbf{脸部编辑:} 脸部编辑:
使用强大的神经网络,人们可以通过执行编辑在视频中引入所需的表情。
我们将我们的方法与 STIT \cite{stit} 进行比较。 STIT 根据输入标签修改面部视频的表情。我们观察源表情并手动尝试“微笑”情绪的各种强度,从消极到积极。
如图7所示,虽然STIT可以改变整体表情,但它需要手动尝试来确定准确的表情。它还缺乏个性化的表情(张嘴的次数、微妙的眉毛变化)。此外,每个表情都不能使用单一标签来定义,并且沿着时间维度引入情感变化也很困难。通过我们提出的方法,人们可以在视频中融入任何情感(只要我们能够访问源视频)。
5. Ablation Study


我们研究了不同模块和错误在实现 FaceOff 过程中的贡献。
Fig.8 演示了在没有所提出的时间模块的情况下 FaceOff 的性能。如图所示,虽然在帧级别,输出是空间相干的,但当我们查看帧时,我们可以注意到时间不相干。这张脸似乎在画面上“摇晃”——上下挤压。事实上,如果没有时间模块,网络就无法理解整体面部结构并生成不自然的帧(以红色标记)。从一个红色方框跳到另一个红色方框,我们可以看到脸部结构完全改变了。这表明使用时间模块通过相邻帧约束网络使网络能够学习全局形状拟合问题,从而生成时间相干的输出。
表3展示了时间模块的定量贡献以及用于自监督训练的每个错误。这些指标表明,它们中的每一个都对实现 FaceOff 做出了重大贡献。
6. Conclusion
我们引入了“视频到视频(V2V)面部交换”,这是一种新颖的面部交换任务。与面部交换不同的是,面部交换旨在将源面部视频(或图像)中的身份交换到目标面部视频中,V2V换脸的目的是在交换源表情的同时交换身份。
为了解决这个问题,我们提出了 FaceOff,这是一种自我监督的时间自动编码网络,它以两个面部视频作为输入并产生单个连贯的混合输出。如实验部分所示,FaceOff 比现有方法更好地交换源身份,同时计算效率也达到 400 倍。它还交换了任何方法都无法做到的确切源身份。 V2V换脸有很多应用;一个重要的应用是自动执行用电影中演员的身份和表情替换替身面孔的任务。我们相信我们的工作为电影剪辑增添了一个全新的维度,有可能节省数月繁琐的手动工作和数百万美元。