2023(TranSkeleton):TranSkeleton: Hierarchical Spatial-Temporal Transformer for Skeleton-Based Action
TranSkeleton: Hierarchical Spatial-Temporal Transformer for Skeleton-Based Action Recognition
- Abstract
- 1.INTRODUCTION
- 2.METHOD
-
- 2.1 Overview of TranSkeleton
- 2.2 Partition-Aggregation Temporal Transformer
- 2.3 Topology-Aware Spatial Transformer
- 3. EXPERIMENTS
-
- 3.1 Ablation Study
- 3.2 Comparison with the State-of-the-Art
Abstract
存在问题:时间卷积很难有效地捕获远程依赖。同时,常用的多分支图卷积具有较高的复杂度。
本文提出了 TranSkeleton,它统一了骨架序列的空间和时间建模。
对于时间建模,本文提出了一种分区聚合时间 Transformer。它适用于分层时间的分区和聚合,可以有效地捕获远程依赖和微妙的时间结构。设计了一种差分感知聚合方法来减少时间聚合过程中的信息丢失。
对于空间建模,本文提出了一种拓扑感知空间转换器,它利用人体拓扑的先验信息来促进空间相关性建模。
1.INTRODUCTION

图1 不同时间建模方法的比较。
(a):时间卷积网络(TCN)以滑动窗口的方式执行局部建模,感受野受限。
(b):Vanilla Transformer (V-Trans) 在整个模型中执行全局建模,没有时间聚合,缺乏局部建模,计算开销大。
(c):本文提出的分区聚合时间Transformer (PAT-Trans) 分层时间分区和聚合来捕获局部到全局的时间依赖关系,有效地捕获长期依赖关系和微妙的时间结构,降低冗余。
2.METHOD
2.1 Overview of TranSkeleton
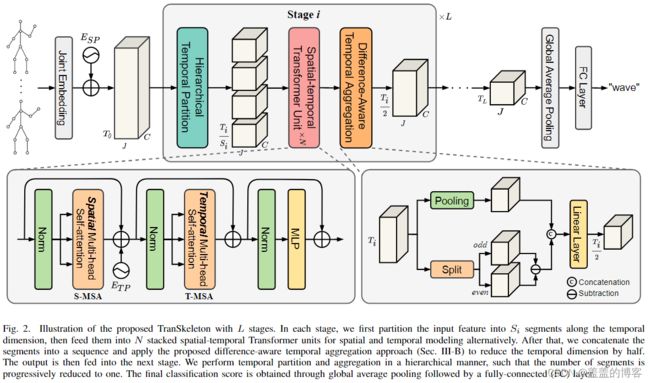
如图 2 所示,具有L 个阶段的 TranSkeleton的框架说明。
在每个阶段,首先将输入特征沿时间维度划分为 Si 段,然后将它们交替输入到 N 个堆叠的时空 Transformer 单元中进行空间和时间建模。之后,将片段连接成一个序列并应用所提出的差异感知时间聚合方法,将时间维度减少一半。然后将输出送到下一阶段。本文以分层方式执行时间分区和聚合,以便段的数量逐步减少到一个。最终的分类分数是通过全局平均池化和全连接 (FC) 层获得的。
与 TCN-GCN 范式不同, TranSkeleton 在纯 Transformer 框架内统一空间和时间建模。实现了关节与沿运动轨迹的深度相关信息流之间的充分交互,从而可以学习输入骨架序列的判别时空表示。
2.2 Partition-Aggregation Temporal Transformer
Partition-Aggregation Temporal Transformer
首先将输入特征Xj统一沿时间维度划分为S段。然后将它们输入一个共享的时间多头自注意力 (T-MSA) 模块。
T-MSA 应用点积注意力以动态方式对输入序列元素之间的相关性进行建模。给定第k段Xk j∈RT/S ×C的特征,T-MSA首先使用线性映射函数WQ、WK、WV∈RC×C生成相应的查询矩阵、关键字矩阵和值矩阵,即Q、K、V∈RT/S ×C。
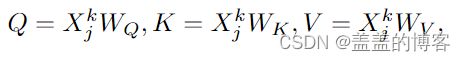
在点积注意力之前,Q、K 和 V 中的每一个都沿通道维度均匀地分成 h 个组(即 h 个头)。每个头对应于原始表示空间的 ^C 维子空间,其中 ^C = C/h。然后在每个子空间中,我们计算相应查询矩阵Qi和关键矩阵Ki的矩阵乘法。归一化后得到一个注意力图,并使用它来指导值矩阵 Vi 的元素的交互。

上述点积注意力并行应用于这些头部。将结果连接起来并馈送到线性层 W ∈ RC×C ,以便融合不同头部的特征。
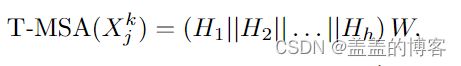
其中||是连接操作。
之后,将 S 段的输出连接成一个整个序列 eXj ∈ RT ×C ,并通过时间聚合将序列长度减少一半。一个阶段的整个时间建模过程可以表述为:

其中TA 表示时间聚合。本文以分层方式执行这种分区建模聚合过程,并逐渐将段的数量减少到一个。在该过程中,时间感受野迅速增加,很快覆盖整个序列。通过这种方式,实现了有效的局部到全局的时间建模。
Difference-Aware Temporal Aggregation
时间聚合在 PAT-Trans 里的作用:1)减少了序列长度,避免了高级特征复杂性的不必要增加。2) 有效地扩大了时间感受野,促进了远距离帧之间的交互。
例如,如果两个连续的阶段具有相同的段长度,则在它们之间的时间聚合后,等效的时间感受野会加倍。通常,平均池化和最大池化是降维的两种常用操作。然而,平均池化会导致高频信息的丢失很多,因为它平滑了运动轨迹。Max pooling 保留了每个通道的最大响应并丢弃了较小的响应,从而导致隐藏信息丢失。
为了减少聚合过程中的信息丢失,本文提出了一种差分感知时间聚合 (DATA) 方法。如图2右下角所示,对于特征向量eX∈RTi×J×C,首先通过最大池化或平均池化将时间维度减少一半,并计算奇数帧Xodd,偶数帧Xeven之间的差异。然后在通道维度上连接这两个结果,并使用线性投影 fW ∈ R2C×C 将通道数减少到 C。整个数据方法可以表述为:

通过融合帧间差异和池化特征,DATA 在时间聚合过程中保留了更多的判别信息,从而极大地增强了模型的时间建模能力。
Comparison with TCN and V-Trans
与TCN相比,PATTrans有两个关键优势:
1)由于本文方法的段长度(如16)远大于TCN的内核大小,其接受域很快就会覆盖几个层次结构中的整个序列。相比之下,TCN 需要大量的层来实现相同的目标,导致模型复杂度和计算成本的不可接受的增加。
2)即使与TCN具有相同的接受域,本文方法也具有更高的信息交互效率。例如,如果将段长度设置为 16,那么对于同一段中的任何一对元素,上述路径长度为 1。这是因为对于 PAT-Trans,段的所有元素都通过点积注意力直接相互作用,而不管它们的距离多少。然而,在TCN中,实现第1个元素和第15个元素之间的交互需要6个堆叠的时间卷积层(核大小=5)。在这种深层已经消失了大量的细微运动信息。
与 V-Trans 相比, PAT-Trans 以局部到全局的方式执行时间建模。将局部建模引入 Transformer 不仅增强了其抓取输入序列细微时间结构的能力,而且有助于在有限规模的数据集上进行训练。同时,分层架构大大减少了 V-Trans 的冗余。
2.3 Topology-Aware Spatial Transformer
本文应用多头自注意力以全局方式捕获关节之间的空间相关性。这是因为与骨架序列不同,骨架内的关节具有明确的顺序,且关节的数量远小于序列长度。
具体来说,给定一个输入骨架序列,在每一帧内单独执行空间建模。本文将第t帧Xt∈RJ×3中关节的3D坐标视为包含J个元素的序列,并通过线性投影We∈R3×C将坐标映射到C维空间得到关节的嵌入向量。然后使用可训练的空间位置嵌入 ESP ∈ RJ×C 对嵌入向量求和,并将结果输入空间多头自注意力 (S-MSA) 模块。S-MSA 在表示子空间中生成 h 个注意力图,并使用注意力图来指导关节之间的信息流。因此避免了多分支GCN集成带来的复杂性增加。上述空间建模过程可以表述为:

Physical Connection Constraint

除了关节坐标外,代表骨骼长度和方向的骨骼向量也是基于骨骼的动作识别中另一种常用的模态。然而在这种骨模态中,绝对位置和人体拓扑信息完全丢失,这阻碍了纯基于注意力的空间建模。
为了解决这个问题,本文设计了一个物理连接约束 (PCC) 来形成拓扑感知空间 Transformer。具体来说,除了动态生成的注意力矩阵外,本文在每个注意力头定义了一个参数化的相邻矩阵,并将所有元素限制为零,除了对应于实际物理连接的那些。如图 3 所示,第 7 个骨骼连接到简化人体骨骼中的第 6 个和第 8 个骨骼。因此,参数化相邻矩阵中的第 7 行/列仅包含三个非零值。将原始的多头自注意与物理连接约束相结合,式子转化为:
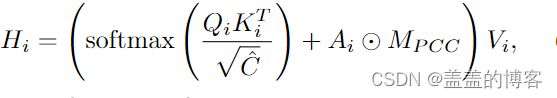
其中 ⊙ 表示逐元素乘法。Ai 是第 i 个注意力头中的参数化相邻矩阵。MPCC 是一个零一矩阵,用作物理连接约束。此外,添加没有任何约束的参数化相邻矩阵也是一个选项。
PCC 与 2s-AGCN有2方面的很大不同:1)不执行手动分区为 2s-AGCN,它将物理连接的邻域分成三个子集。2) 2s-AGCN 需要多个 GCN 分支对不同的子集执行费力的特征转换。相比之下,PCC通过约束关节之间的信息流,将人体拓扑的先验信息嵌入到Transformer中。
3. EXPERIMENTS
3.1 Ablation Study
Temporal modeling method

PAT-Trans 具有最少的参数和 FLOP。

PAT-Trans 可以更好地同时捕获输入序列的长程时间依赖性和微妙的时间结构。
The number of segments
S段的数量在分层时间分区过程中起着重要作用。在每个层次结构中,大 S 导致短段内的局部建模,从而增强捕获输入序列细微时间结构的能力。相比之下,一个小S使模型执行更长的时间建模和可以更好地捕获长期依赖关系。因此,S 是平衡局部和全局时间建模的关键因素。

Si 表示第 i 个层次结构中的片段数,S3 设置为 1,用于最后一个层次结构中的全局建模。
如上表所示,设置 S1 = S2 = S3 = 1(即执行全局时间建模)会产生最差的性能。增加 S1 和 S2 将局部建模引入 Transformer 中,并显着提高了模型的性能。然而,当 S1 和 S2 变得太大时,该模型将专注于短段内的局部建模,从而损害其捕获远程依赖的能力。
The number of input frames

通过插值将每个输入序列调整为一定数量的帧。表 III 显示了不同输入长度的性能比较。模型的性能最初随着输入长度的增加而增加。当输入长度大于 64 帧时,性能变得饱和。因此,本文将 TranSkeleton 模型的输入长度设置为 64 帧。
Positional embedding
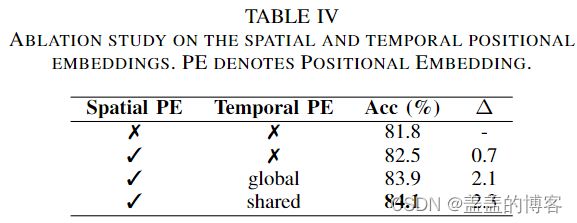
为了评估空间和时间位置嵌入的影响:添加空间位置嵌入有助于关节之间的相关性建模,时间位置嵌入对性能的影响更大。与全局位置嵌入相比,添加共享时间位置嵌入实现了稍好的性能。这是因为所有段共享的位置嵌入可能会获得足够的训练,因为本文在第 1 阶段和第 2 阶段执行段时间建模。
Temporal aggregation
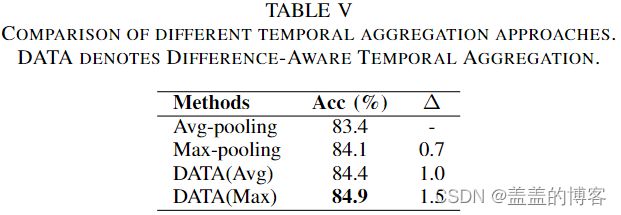
不同时间聚合方式的性能:平均池化产生最差的性能,因为它会导致高频时间信息的显着损失。最大池化保留了每个通道的最大响应,并取得了更好的性能。但是,它也会下降较小的值并导致很多信息丢失。
结果表明,所提出的 DATA 方法有效地减少了时间聚合过程中的信息丢失,增强了模型的时间建模能力。
Physical connection constraint

PCC明确地将人体拓扑的先验信息嵌入到模型中,从而有效地促进了空间建模。
Model complexity

验证了所提出的 TranSkeleton 模型的高效率。
3.2 Comparison with the State-of-the-Art
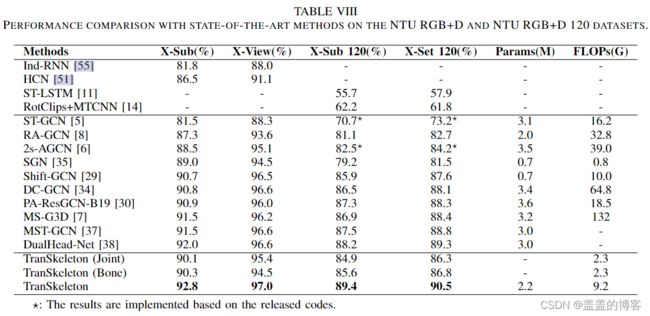
验证本文方法的有效性。