SeaTunnel 学习笔记
第1章 Seatunnel概述
官网地址:https://seatunnel.apache.org/
文档地址:https://interestinglab.github.io/seatunnel-docs/#/
1.1 SeaTunnel是什么
SeaTunnel是一个简单易用,高性能,能够应对海量数据的数据处理产品。
SeaTunnel的前身是Waterdrop(中文名:水滴)自2021年10月12日更名为SeaTunnel。2021年12月9日,SeaTunnel正式通过Apache软件基金会的投票决议,以全票通过的优秀表现正式成为Apache孵化器项目。
1.2 SeaTunnel在做什么
本质上,SeaTunnel不是对Saprk和Flink的内部修改,而是在Spark和Flink的基础上做了一层包装。它主要运用了控制反转的设计模式,这也是SeaTunnel实现的基本思想。
SeaTunnel的日常使用,就是编辑配置文件。编辑好的配置文件由SeaTunnel转换为具体的Spark或Flink任务。如图所示。

1.3 SeaTunnel的应用场景
SeaTunnel适用于以下场景:
海量数据的同步
海量数据的集成
海量数据的ETL
海量数据聚合
多源数据处理
SeaTunnel的特点:
基于配置的低代码开发,易用性高,方便维护。
支持实时流式传输
离线多源数据分析
高性能、海量数据处理能力
模块化的插件架构,易于扩展
支持用SQL进行数据操作和数据聚合
支持Spark structured streaming
支持Spark 2.x
目前SeaTunnel的长板是他有丰富的连接器,又因为它以Spark和Flink为引擎。所以可以很好地进行分布式的海量数据同步。通常SeaTunnel会被用来做出仓入仓工具,或者被用来进行数据集成
1.4 SeaTunnel的工作流程
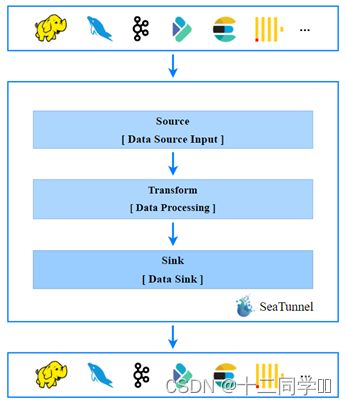
1.5 SeaTunnel目前的插件支持
1.5.1 Spark连接器插件(Source)
| Spark连接器插件 | 数据库类型 | Source | Sink |
|---|---|---|---|
| Batch | Fake | √ | |
| ElasticSearch | √ | √ | |
| File | √ | √ | |
| Hive | √ | √ | |
| Hudi | √ | √ | |
| Jdbc | √ | √ | |
| MongoDB | √ | √ | |
| Neo4j | √ | ||
| Phoenix | √ | √ | |
| Redis | √ | √ | |
| Tidb | √ | √ | |
| Clickhouse | √ | ||
| Doris | √ | ||
| √ | |||
| Hbase | √ | √ | |
| Kafka | √ | ||
| Console | √ | ||
| Kudu | √ | √ | |
| Redis | √ | √ | |
| Stream | FakeStream | √ | |
| KafkaStream | √ | ||
| SocketSTream | √ |
1.5.2 Flink 连接器插件(Source)
| Flink连接器插件 | 数据库类型 | Source | Sink |
|---|---|---|---|
| Druid | √ | √ | |
| Fake | √ | ||
| File | √ | √ | |
| InfluxDb | √ | √ | |
| Jdbc | √ | √ | |
| Kafka | √ | √ | |
| Socket | √ | ||
| Console | √ | ||
| Doris | √ | ||
| ElasticSearch | √ |
1.5.3 Spark & Flink 转换插件
| 转换插件 | Spark | Flink |
|---|---|---|
| Add | ||
| CheckSum | ||
| Convert | ||
| Date | ||
| Drop | ||
| Grok | ||
| Json | √ | |
| Kv | ||
| Lowercase | ||
| Remove | ||
| Rename | ||
| Repartition | ||
| Replace | ||
| Sample | ||
| Split | √ | √ |
| Sql | √ | √ |
| Table | ||
| Truncate | ||
| Uppercase | ||
| Uuid |
第2章 Seatunnel安装和使用
2.1 SeaTunnel的环境依赖
Java版本需要>=1.8
SeaTunnel支持Spark 2.x(尚不支持Spark 3.x)。支持Flink 1.9.0及其以上的版本。
2.2 SeaTunnel的下载和安装
去官网下载解压即可
2.3 SeaTunnel的依赖环境配置
在config/目录中有一个seatunnel-env.sh脚本

修改为自己的spark或者flink路径即可
2.4 示例1: SeaTunnel 快速开始
官方的flink案例
1.选择任意路径,创建一个文件。这里我们选择在SeaTunnel的config路径下创建一个example01.conf
vim example01.conf
2.在文件中编辑如下内容
# 配置Spark或Flink的参数
env {
# You can set flink configuration here
execution.parallelism = 1
#execution.checkpoint.interval = 10000
#execution.checkpoint.data-uri = "hdfs://node1:9092/checkpoint"
}
# 在source所属的块中配置数据源
source {
SocketStream{
host = node1
result_table_name = "fake"
field_name = "info"
}
}
# 在transform的块中声明转换插件
transform {
Split{
separator = "#"
fields = ["name","age"]
}
sql {
sql = "select info, split(info) as info_row from fake"
}
}
# 在sink块中声明要输出到哪
sink {
ConsoleSink {}
}
3.开启flink集群
bin/start-cluster.sh
4.开启一个netcat服务来发送数据
nc -lk 9999
5.使用SeaTunnel来提交任务
bin/start-seatunnel-flink.sh --config config/example01.conf
6.在netcat上发送数据

7.在Flink webUI上查看输出结果

第3章 SeaTunnel基本原理
3.1 SeaTunnel的启动脚本
截至目前,SeaTunnel有两个启动脚本。
提交spark任务用start-seatunnel-spark.sh。
提交flink任务则用start-seatunnel-flink.sh。
start-seatunnle-flink.sh可以指定3个参数
分别是:
–config参数用来指定应用配置文件的路径
–variable参数可以向配置文件传值。配置文件内是支持声明变量的。然后我们可以通过命令行给配置中的变量赋值。
变量声明语法如下
sql {
sql = "select * from (select info,split(info) from fake) where age > '"${age}"'"
}
在配置文件的任何位置都可以声明变量。并用命令行参数–variable key=value的方式将变量值传进去,你也可以用它的短命令形式 -i key=value。传递参数时,key需要和配置文件中声明的变量名保持一致。
如果需要传递多个参数,那就在命令行里面传递多个-i或–variable key=value。
bin/start-seatunnel-flink.sh --config/xxx.sh -i age=18 -i sex=man
–check参数用来检查config语法是否合法(check功能还尚在开发中,因此–check参数是一个虚设)
3.2 SeaTunnel的配置文件
3.2.1 应用配置的4个基本组件
一个完整的SeaTunnel配置文件应包含四个配置组件。分别是:
env{} source{} --> transform{} --> sink{}

在Source和Sink数据同构时,如果业务上也不需要对数据进行转换,那么transform中的内容可以为空。具体需根据业务情况来定。
3.2.2 SeaTunnel中的核心数据结构Row
Row是SeaTunnel中数据传递的核心数据结构。对flink来说,source插件需要给下游的转换插件返回一个DataStream,转换插件接到上游的DataStream进行处理后需要再给下游返回一个DataStream。最后Sink插件将转换插件处理好的DataStream输出到外部的数据系统。

因为DataStream可以很方便地和Table进行互转,所以将Row当作核心数据结构可以让转换插件同时具有使用代码(命令式)和sql(声明式)处理数据的能力。
3.2.3 env块
env块中可以直接写spark或flink支持的配置项。比如并行度,检查点间隔时间。检查点hdfs路径等。在SeaTunnel源码的ConfigKeyName类中,声明了env块中所有可用的key。如图所示:

3.2.4 source块
source块是用来声明数据源的。source块中可以声明多个连接器。比如:
# 伪代码
env {
...
}
source {
hdfs { ... }
elasticsearch { ... }
jdbc {...}
}
transform {
sql {
sql = """
select .... from hdfs_table
join es_table
on hdfs_table.uid = es_table.uid where ..."""
}
}
sink {
elasticsearch { ... }
}
需要注意的是,所有的source插件中都可以声明result_table_name。如果你声明了result_table_name。SeaTunnel会将source插件输出的DataStream转换为Table并注册在Table环境中。当你指定了result_table_name,那么你还可以指定field_name,在注册时,给Table重设字段名。
3.2.5 transform块
transform{}块中可以声明多个转换插件。所有的转换插件都可以使用source_table_name,和result_table_name。同样,如果我们声明了result_table_name,那么我们就能声明field_name。
目前可用的插件总共有两个,一个是Split,另一个是sql。
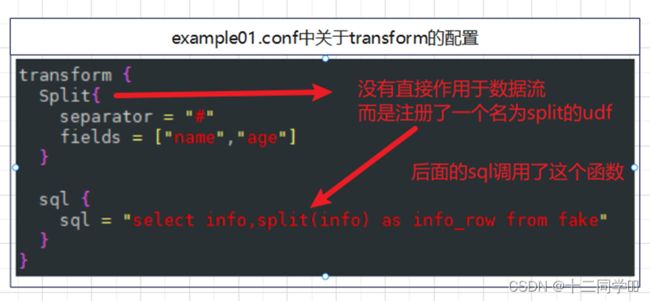
Split插件并没有对数据流进行任何的处理,而是将它直接return了。反之,它向表环境中注册了一个名为split的UDF(用户自定义函数)。而且,函数名是写死的。
指定soure_table_name对于sql插件的意义不大。因为sql插件可以通过from子句来决定从哪个表里抽取数据。
3.2.6 sink块
Sink块里可以声明多个sink插件,每个sink插件都可以指定source_table_name。不过因为不同Sink插件的配置差异较大,所以在实现时建议参考官方文档。
3.3 SeaTunnel的基本原理

1.程序会解析你的应用配置,并创建环境
2.配置里source{},transform{},sink{}三个块中的插件最终在程序中以List集合的方式存在。
3.由Excution对象来拼接各个插件,这涉及到选择source_table,注册result_table等流程,注册udf等流程。并最终触发执行
3.4 小结
用一张图将SeaTunnel中的重要概念串起来

如果你不指定source_table_name,插件会使用它在配置文件上最近的上一个插件的输出作为输入。
第4章 应用案例
4.1 flink通过JDBC方式读取hive数据
这个已经在2.12版本里面启用,将hive-jdbc-3.1.2-standalone.jar放入flink的lib中
env {
# You can set flink configuration here
execution.parallelism = 1
#execution.checkpoint.interval = 10000
#execution.checkpoint.data-uri = "hdfs://node1:9092/checkpoint"
}
# 在source所属的块中配置数据源
source {
JdbcSource {
driver = org.apache.hive.jdbc.HiveDriver
url = "jdbc:hive2://node1:10000"
username = hive
query = "select * from yes.student"
}
}
# 在transform的块中声明转换插件
transform {
}
# 在sink块中声明要输出到哪
sink {
ConsoleSink {}
}
4.2 Kafka进Kafka出的简单ETL
对test_csv主题中的数据进行过滤,仅保留年龄在18岁以上的记录
env {
# You can set flink configuration here
execution.parallelism = 1
#execution.checkpoint.interval = 10000
#execution.checkpoint.data-uri = "hdfs://hadoop102:9092/checkpoint"
}
# 在source所属的块中配置数据源
source {
KafkaTableStream {
consumer.bootstrap.servers = "node1:9092"
consumer.group.id = "seatunnel-learn"
topics = test_csv
result_table_name = test
format.type = csv
schema = "[{\"field\":\"name\",\"type\":\"string\"},{\"field\":\"age\", \"type\": \"int\"}]"
format.field-delimiter = ";"
format.allow-comments = "true"
format.ignore-parse-errors = "true"
}
}
# 在transform的块中声明转换插件
transform {
sql {
sql = "select name,age from test where age > '"${age}"'"
}
}
# 在sink块中声明要输出到哪
sink {
kafkaTable {
topics = "test_sink"
producer.bootstrap.servers = "node1:9092"
}
}
启动任务
bin/start-seatunnel-flink.sh --config config/example03.conf -i age=18
4.3 Kafka 输出到Doris进行指标统计
使用回话日志统计用户的总观看视频数,用户最常会话市场,用户最小会话时长,用户最后一次会话时间。
create database test_db;
CREATE TABLE `example_user_video` (
`user_id` largeint(40) NOT NULL COMMENT "用户id",
`city` varchar(20) NOT NULL COMMENT "用户所在城市",
`age` smallint(6) NULL COMMENT "用户年龄",
`video_sum` bigint(20) SUM NULL DEFAULT "0" COMMENT "总观看视频数",
`max_duration_time` int(11) MAX NULL DEFAULT "0" COMMENT "用户最长会话时长",
`min_duration_time` int(11) MIN NULL DEFAULT "999999999" COMMENT "用户最小会话时长",
`last_session_date` datetime REPLACE NULL DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次会话时间"
) ENGINE=OLAP
AGGREGATE KEY(`user_id`, `city`, `age`)
COMMENT "OLAP"
DISTRIBUTED BY HASH(`user_id`) BUCKETS 16
;
env {
execution.parallelism = 1
}
source {
KafkaTableStream {
consumer.bootstrap.servers = "node1:9092"
consumer.group.id = "seatunnel5"
topics = test
result_table_name = test
format.type = json
schema = "{\"session_id\":\"string\",\"video_count\":\"int\",\"duration_time\":\"long\",\"user_id\":\"string\",\"user_age\":\"int\",\"city\":\"string\",\"session_start_time\":\"datetime\",\"session_end_time\":\"datetime\"}"
format.ignore-parse-errors = "true"
}
}
transform{
sql {
sql = "select user_id,city,user_age as age,video_count as video_sum,duration_time as max_duration_time,duration_time as min_duration_time,session_end_time as last_session_date from test"
result_table_name = test2
}
}
sink{
DorisSink {
source_table_name = test2
fenodes = "node1:8030"
database = test_db
table = example_user_video
user = atguigu
password = 123321
batch_size = 50
doris.column_separator="\t"
doris.columns="user_id,city,age,video_sum,max_duration_time,min_duration_time,last_session_date"
}
}