探索Redis特殊数据结构:HyperLogLog在基数统计中的应用
一、概述

Redis官方提供了多种数据类型,除了常见的String、Hash、List、Set、zSet之外,还包括Stream、Geospatial、Bitmaps、Bitfields、Probabilistic(HyperLogLog、Bloom filter、Cuckoo filter、t-digest、Top-K、Count-min sketch、Configuration)和Time series。这些数据类型在Redis的数据结构中发挥着各自独特的作用。

这些数据类型丰富了Redis的功能,提供了灵活而高效的数据存储和操作方式。在使用时,选择合适的数据类型可以根据实际需求达到更好的性能和效果。
以下主要介绍HyperLogLog的概念及使用:
Redis 的 HyperLogLog(HLL)是一种数据结构,用于估计一个集合中不同元素的数量,而不需要存储每个元素的详细信息。HyperLogLog 提供了一种近似基数估计的方法,具有以下功能和作用:
- 独立元素计数: HyperLogLog 主要用于估计一个集合中的不同元素的数量。这对于大规模数据集的基数估计是非常有用的。
- 固定内存占用: HyperLogLog 使用固定大小的内存来存储估计值,而不受集合中元素数量的影响。这使得它适用于处理大规模数据集,内存占用是固定的。
- 低存储成本: 相对于存储每个元素的详细信息,使用 HyperLogLog 可以在节省存储空间的同时得到基数的估计值。
- 去重和近似集合操作: 可以使用 HyperLogLog 进行多个集合的合并,得到这些集合的基数的估计值。这对于合并多个数据源的基数估计是有用的。
- 适用于大数据集: HyperLogLog 在大规模数据集中的性能非常好,可以处理海量元素而不显著增加内存开销。
- 用于统计分析: 适用于一些需要估计不同元素数量的场景,如网站的独立访问者数、广告点击用户数等。
基本命令
- PFADD key element [element ...]: 将一个或多个元素添加到 HyperLogLog 中。
- PFCOUNT key [key ...]: 返回 HyperLogLog 的基数估计值,即估计的不同元素的数量。
- PFMERGE destkey sourcekey [sourcekey ...]: 将多个 HyperLogLog 合并为一个。
这里是完整的Redis HyperLogLog操作。

二、命令语法
以下是 Redis HyperLogLog 相关命令的详细说明:
1. PFADD 命令:
PFADD 命令用于将一个或多个元素添加到 HyperLogLog 数据结构中。
语法:
PFADD key element [element ...]key: HyperLogLog 的键名。element: 要添加到 HyperLogLog 的元素。
示例:
# 将元素 "user1" 添加到 HyperLogLog 中
127.0.0.1:6379> PFADD myloglog user1
# 将多个元素添加到 HyperLogLog 中
127.0.0.1:6379> PFADD myloglog user2 user3 user42. PFCOUNT 命令:
PFCOUNT 命令用于获取 HyperLogLog 中基数的估计值,即估计的不同元素的数量。
语法:
PFCOUNT key [key ...]key: 一个或多个 HyperLogLog 的键名。
示例:
# 获取 HyperLogLog "myloglog" 的基数估计值
127.0.0.1:6379> PFCOUNT myloglog
(integer) 43. PFMERGE 命令:
PFMERGE 命令用于将多个 HyperLogLog 合并为一个 HyperLogLog。
语法:
PFMERGE destkey sourcekey [sourcekey ...]destkey: 合并后的 HyperLogLog 的键名。sourcekey: 要合并的 HyperLogLog 的键名,可以是一个或多个。
示例:
# 将多个 HyperLogLog 合并为一个
127.0.0.1:6379> PFMERGE mergedloglog myloglog1 myloglog2 myloglog3上述命令将 myloglog1、myloglog2 和 myloglog3 合并为一个新的 HyperLogLog,并存储在 mergedloglog 中。
三、工作原理
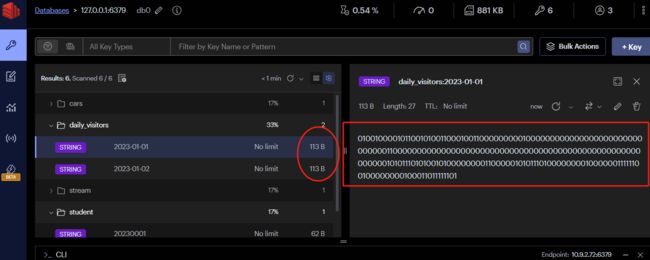
理解 HyperLogLog 使用固定大小的内存来存储估计值的概念需要考虑 HyperLogLog 的工作原理以及它对内存的使用方式。
在 HyperLogLog 中,用于存储基数估计的内存大小是固定的,不受集合中元素数量的直接影响。这是因为 HyperLogLog 不是通过存储每个元素的信息来计算基数估计的,而是通过对位图进行近似计数。
HyperLogLog 使用了哈希函数将元素映射到固定大小的位图上。这个位图的大小是固定的,通常在初始化 HyperLogLog 时指定。由于哈希函数的性质,即使集合中的元素数量增加,位图的大小仍然保持不变。
具体的工作原理如下:
- 哈希函数映射: HyperLogLog 使用哈希函数将每个元素映射到固定大小的位图上。这个位图通常是一个很长的二进制序列,但其长度是固定的。
- 计数估计: 通过哈希函数的映射,HyperLogLog 会在位图上设置一些位的值。估计基数的算法基于这些设置的位的模式。不同的元素映射到相同的位可能导致位被设置为1,但设置的位越多,基数估计越高。
- 固定大小的内存: 无论集合中有多少个元素,HyperLogLog 使用的位图的大小是固定的。这意味着在初始化 HyperLogLog 时,你需要指定要使用的内存大小。更大的内存通常意味着更高的准确性,但同时也意味着更大的存储开销。