使用opencv做双目测距(相机标定+立体匹配+测距)
最近在做双目测距,觉得有必要记录点东西,所以我的第一篇博客就这么诞生啦~
双目测距属于立体视觉这一块,我觉得应该有很多人踩过这个坑了,但网上的资料依旧是云里雾里的,要么是理论讲一大堆,最后发现还不知道怎么做,要么就是直接代码一贴,让你懵逼。 所以今天我想做的,是尽量给大家一个明确的阐述,并且能够上手做出来。
一、 标定
首先我们要对摄像头做标定,具体的公式推导在learning opencv中有详细的解释,这里顺带提一句,这本书虽然确实老,但有些理论、算法类的东西里面还是讲的很不错的,必要的时候可以去看看。
Q1:为什么要做摄像头标定?
A: 标定的目的是为了消除畸变以及得到内外参数矩阵,内参数矩阵可以理解为焦距相关,它是一个从平面到像素的转换,焦距不变它就不变,所以确定以后就可以重复使用,而外参数矩阵反映的是摄像机坐标系与世界坐标系的转换,至于畸变参数,一般也包含在内参数矩阵中。从作用上来看,内参数矩阵是为了得到镜头的信息,并消除畸变,使得到的图像更为准确,外参数矩阵是为了得到相机相对于世界坐标的联系,是为了最终的测距。
ps1:关于畸变,大家可以看到自己摄像头的拍摄的画面,在看矩形物体的时候,边角处会有明显的畸变现象,而矫正的目的就是修复这个。
ps2:我们知道双目测距的时候两个相机需要平行放置,但事实上这个是很难做到的,所以就需要立体校正得到两个相机之间的旋转平移矩阵,也就是外参数矩阵。
Q2:如何做摄像头的标定?
A:这里可以直接用opencv里面的sample,在opencv/sources/sample/cpp里面,有个calibration.cpp的文件,这是单目的标定,是可以直接编译使用的,这里要注意几点:
1.棋盘
棋盘也就是标定板是要预先打印好的,你打印的棋盘的样式决定了后面参数的填写,具体要求也不是很严谨,清晰能用就行。之所用棋盘是因为他检测角点很方便,and…你没得选。。
2. 参数
****一般设置为这个样子:-w 6 -h 8 -s 2 -n 10 -o camera.yml -op -oe [
-w # 图片某一维方向上的交点个数
-h # 图片另一维上的交点个数
[-n ] # 标定用的图片帧数
[-s ] # square size in some user-defined units (1 by default)
[-o ] # the output filename for intrinsic [and extrinsic] parameters
[-op] # write detected feature points
[-oe] # write extrinsic parameters
可以发现 -w -h是棋盘的长和高,也就是有几个黑白交点,-s是每个格子的长度,单位是cm
长和高一定要数对,不然程序在识别角点的时候会识别不出来的。
最终得到的yml文件,就是单目标定的参数矩阵,之后使用它就可以得到校正后的图像啦。
3. 需要对程序做一些修改,这是我遇到的问题,就是他的读取摄像头的代码在我这边没有用,所以我自己重新修改了,不知道大家会 不会碰到这个问题。
然后就是双目标定了,同样的地方,找到stereo_calib.cpp,这个参数比较简单,只要确定长、宽和输入的一个xml文件(在之前 的文件夹里面),这个文件是为了读取图片用的,你需要自己用固定好的双目摄像头拍14对棋盘图片,命名为 left01,right01…这样 一系列的名字,另外,最简单的方法就是把自己拍的照片放到相应的工程下,以及stereo开头的那个xml文件也复制过去这个程序代码 并不复杂,可以稍微研究一下,工程向的代码确实严谨,各种情况都考虑到了,比起自己之前做的那个小项目不知道高到哪里去了
这里也有几个注意点(坑):
1.老生常谈的问题,长宽一定要写对!!! 这个不多说了,都是泪。
2.代码的核心函数 static void StereoCalib(const vector& imagelist, Size boardSize, bool useCalibrated=true, bool showRectified=true),注意搞清楚参数的意义,因为我是用的单目标定好的摄像头拍摄的图片,不需要再校正了,所以第三个参数要用false,这样最后的结果才能看,不说了,都是泪…
3.另外注意到计算rms误差的时候,结束条件的几个参数是可以调整的,
double rms = stereoCalibrate(objectPoints, imagePoints[0], imagePoints[1],
cameraMatrix[0], distCoeffs[0],
cameraMatrix[1], distCoeffs[1],
imageSize, R, T, E, F,
TermCriteria(CV_TERMCRIT_ITER+CV_TERMCRIT_EPS, 100, 1e-5),
CV_CALIB_FIX_ASPECT_RATIO +CV_CALIB_ZERO_TANGENT_DIST +CV_CALIB_SAME_FOCAL_LENGTH +CV_CALIB_RATIONAL_MODEL +CV_CALIB_FIX_K3 + CV_CALIB_FIX_K4 + CV_CALIB_FIX_K5)
下面这段话是某度百科上的:
这个函数计算了两个摄像头进行立体像对之间的转换关系。如果你有一个立体相机的相对位置,并且两个摄像头的方向是固定的,以及你计算了物体相对于第一照相机和第二照相机的姿态,(R1,T1)和(R2,T2),各自(这个可以通过solvepnp()做到)通过这些姿态确定。你只需要知道第二相机相对于第一相机的位置和方向。
除了立体的相关信息,该函数也可以两个相机的每一个做一个完整的校准。然而,由于在输入数据中的高维的参数空间和噪声的,可能偏离正确值。如果每个单独的相机内参数可以被精确估计(例如,使用calibratecamera()),建议这样做,然后在本征参数计算之中使CV_CALIB_FIX_INTRINSIC的功能。否则,如果一旦计算出所有的参数,它将会合理的限制某些参数,例如,传CV_CALIB_SAME_FOCAL_LENGTH and CV_CALIB_ZERO_TANGENT_DIST,这通常是一个合理的假设。
Q3:标定之后做什么呢?
A: 写到这我发现把单目和双目的一起写确实有点乱…不过,开弓没有回头箭!(不是因为懒!!)
首先还是单目,单目的使用很简单,使用标定得到的参数进行校正就行了,代码如下:
void loadCameraParams(Mat &cameraMatrix, Mat &distCoeffs)
{
FileStorage fs(“camera.yml”, FileStorage::READ);//这个名字就是你之前校正得到的yml文件
fs[“camera_matrix”] >> cameraMatrix;
fs[“distortion_coefficients”] >> distCoeffs;
}
Mat calibrator(Mat &view)//需要校正处理的图片
{
vector imageList;
static bool bLoadCameraParams = false;
static Mat cameraMatrix, distCoeffs, map1, map2;
Mat rview;
Size imageSize, newImageSize;
if (!view.data)
return Mat();
imageSize.width = view.cols;
imageSize.height = view.rows;
newImageSize.width = imageSize.width;
newImageSize.height = imageSize.height;
if (bLoadCameraParams == false)
{
loadCameraParams(cameraMatrix, distCoeffs);
bLoadCameraParams = true;
initUndistortRectifyMap(cameraMatrix, distCoeffs, Mat(),
getOptimalNewCameraMatrix(cameraMatrix, distCoeffs, imageSize, 1, newImageSize, 0), newImageSize, CV_16SC2, map1, map2);
}
//undistort( view, rview, cameraMatrix, distCoeffs, cameraMatrix );
remap(view, rview, map1, map2, INTER_LINEAR);
imshow(“左图”, rview);
//int c = 0xff & waitKey();
rview.copyTo(view);
return view;
}
** 这样最后就可以得到校正后消除畸变的图片。
** OK,接下来显然就是双目啦,双目校正之后的工作就比较多了,我准备另开一节来说…**
二、立体匹配
这是一个很大的题目,网上的资料也很多,所以我想说的是我的一些理解。
这里最好的方法是从后往前说,我们首先需要理解测距的原理。这个很多人看了一大堆还不明白(其实只有我自己吧…),相似三角形测距,这种东西小学生都能搞清楚,但两摄像头到底怎么做到的,就是我们需要搞清楚的。
首先需要搞清楚一个非常重要的概念,视差,搞清楚视差,后面的就简单了 ,老生常谈的问题我不想多说,网上那些一大堆,我希望给大家的是一些明了的东西



这三幅图看明白了就行,其实视差确实很简单,但很多人都没去理清楚,第一幅图是三维世界的一个点在两个相机的成像,我们可以相信的是,这两个在各自相机的相对位置基本不可能是一样的,而这种位置的差别,也正是我们眼睛区别3D和2D的关键,将右边的摄像机投影到左边,怎么做呢?因为他的坐标和左边相机的左边相距Tx(标定测出来的外参数),所以它相当于在左边的相机对三维世界内的(x-tx,y,z)进行投影,所以这时候,一个完美的形似三角形就出来,这里视差就是d=x-x‘,
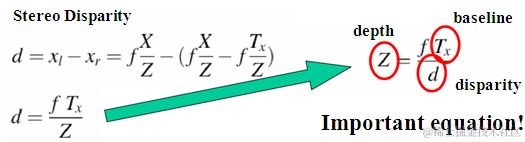
得到视差以后,再用相似三角形…也就得到了深度也就是距离啦。
结束了么??并没有…这样做确实很完美,但是问题来了:1.当我在左边相机确定一个点的时候,我怎么在右边找到这个点? 2.我左边点所在的行一点跟右边点所在的行上的像素一定完全一样么?
解决第一个问题的方法就是立体匹配了。
Q1:立体匹配是什么,怎么进行立体匹配?
A:简单的回答就是:立体匹配就是解决上面问题的东西啦…其实我觉得这样就是也够了,有些成熟的算法,未必需要钻研太深,毕竟我这种实在的菜鸡,还是工程导向的…学术的事,日后再说!
opencv中提供了很多的立体匹配算法,类似于局部的BM,全局的SGBM等等,这些算法的比较大概是,速度越快的效果越差,如果不是很追究时效性,并且你的校正做的不是很好的话…推荐使用SGBM,算法的具体原理大家可以去百度,不难。这里我想提一下的是为什么做立体匹配有用,原因就是极线约束,这也是个很重要的概念,理解起来并不难,左摄像机上的一个点,对应三维空间上的一个点,当我们要找这个点在右边的投影点时,有必要把这个图像都遍历一边么,当然不用…

如上图,显然,PL对应的P这个点一定在一条极线上,只要在这条线上找就行了,更明显的是下面这个图:

最后,怎么在opencv里面实现呢…机智的我又找到了sample…找到stereo_match.cpp这个文件,命令行设置为:left01.jpg right02.jpg --algorithm=hh --blocksize=5 --max-disparity=256 --scale=1.0 --no-display -i intrinsics.yml -e extrinsics.yml -o disparity.jpg同意给几个建议:
1.参数的意义:
-max-disparity 是最大视差,可以理解为对比度,越大整个视差的range也就越大,这个要求是16的倍数
–blocksize 一般设置为5-29之间的奇数,应该是局部算法的窗口大小。
另,注意带上参数-i intrinsics.yml -e extrinsics.yml,毕竟咱有校正参数…
2.后面有两行代码:
reprojectImageTo3D(disp, xyz, Q, true);
saveXYZ(point_cloud_filename, xyz);
**这个就是得到图片的三维坐标,Z也就是我们最终要求的深度啦。
第二个问题,行和行是对应的么? 之前我们说过,双目校正的目的就是为了得到两个平行的摄像头,所以当程序运行完毕以后,它会把两幅图像显示出来,并作出一系列的平行线,这样你会看到线上的点大致是呈对应关系,左边的角点对应右边的交点,所以,经过匹配和校正后,是对应的。
三、总结
双目拖了很久,一直没做,最重要的原因就是…我没有两个一样的摄像头,所以最后也没有贴出效果图,因为两个不一样的摄像头,做出来的东西画面太美我不敢看,不过最终搞清楚了整个流程和原理,还是比较开心的。这里面像校正和匹配的算法,我只是有所理解,因为以后不一定走3D这一块,所以也没有过去深入,如果用到在去研究,其实也不晚