2023.12.24周报
目录
摘要
ABSTRACT
一、论文阅读
1、题目
2、摘要
3、创新点
4、模型整体架构
5、文章解读
1、Introduction
2、相关工作
3、实验
4、结论
二、深度学习
一、GRU前向传播
二、GRU反向传播
三、GRU代码实现
总结
摘要
本周,我阅读了一篇题目为Self-Attention ConvLSTM for Spatiotemporal Prediction的论文,为了提取同时具有全局和局部依赖性的空间特征,文章引入了自注意机制,即一种新型的自我关注记忆(SAM)方法,用于捕获具有长期空间和时间依赖性的特征。其次,对GRU的前向反向传播进行了推导,并用代码对其进行了实现,加深了自己的理解。
ABSTRACT
This week, I read a paper titled "Self-Attention ConvLSTM for Spatiotemporal Prediction." In order to extract spatial features with both global and local dependencies simultaneously, the paper introduces a self-attention mechanism, specifically a novel Self-Attention Memory (SAM) approach, to capture features with long-term spatial and temporal dependencies. Additionally, the paper derives the forward and backward propagation of GRU and implements it in code, enhancing my understanding of the subject.
一、论文阅读
1、题目
题目:Self-Attention ConvLSTM for Spatiotemporal Prediction
链接:Self-Attention ConvLSTM for Spatiotemporal Prediction| Proceedings of the AAAI Conference on Artificial Intelligence
2、摘要
现有方法中,通过卷积方式仅能局限地捕获空间上的局部依赖关系,效率较低。为了提取同时具有全局和局部依赖性的空间特征,本文引入了自注意机制,即一种新型的自我关注记忆(SAM)方法,用于捕获具有长期空间和时间依赖性的特征。基于自注意,SAM通过综合输入自身和记忆特征的各个位置的特征来生成特征,从而提取长时间时空相关性的特征。然后,利用这些特征构建了用于时空预测的自注意ConvLSTM(SA-ConvLSTM)。相对于先进方法,SA-ConvLSTM在两个数据集上表现出更高的时间效率,同时使用更少的参数取得了最先进的结果。
In existing methods, the use of convolutional approaches is limited in capturing local spatial dependencies, resulting in lower efficiency. In order to extract spatial features with both global and local dependencies simultaneously, this paper introduces a self-attention mechanism, namely a novel Self-Attention Memory (SAM) method, to capture features with long-term spatial and temporal dependencies. Based on self-attention, SAM generates features by synthesizing the characteristics of each position from both the input itself and memory features, thereby extracting features with long-term spatiotemporal correlations. Subsequently, these features are utilized to construct a self-attention Convolutional Long Short-Term Memory (SA-ConvLSTM) for spatiotemporal prediction. In comparison to advanced methods, SA-ConvLSTM demonstrates higher temporal efficiency on two datasets while achieving state-of-the-art results with fewer parameters.
3、创新点
1、提出一个新的基于ConvLSTM的变体模型用于时空预测,命名为SA-ConvLSTM,特点是能很好捕获长程空间依赖性。
2、设计了一个基于记忆的自我注意模块(SAM)来记忆预测过程中的全局时空依赖性;
3、评估了SA-ConvLSTM的表现:与目前最先进的模型MIM相比(在MovingMNIST和KTH上的多帧预测和TexiBJ对交通流的预测),它以更少的参数和更高的效率在所有数据集上取得了最好的结果;它们很容易遭受梯度消失的问题。
4、模型整体架构
这篇文章创新点就是加了一个基于记忆的自相关模块(memory-based self-attention module, SAM),这个模块是接在ConvLSTM模型的最后的,如图浅绿色部分(如果没有它及其输出,这个图就是ConvLSTM模型图,或者说是LSTM模型图):
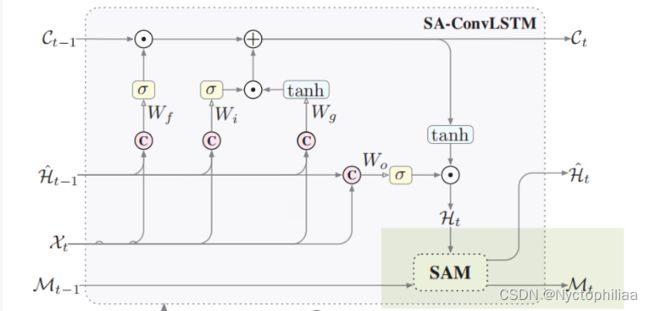
SAM模块

黄色区域:特征聚合,文章中的Feature Aggregation 部分
蓝色区域:记忆更新,文章中的Memory Updating 部分
绿色区域:输出,文章中的Output 部分
Feature Aggregation 特征聚合

整个黄色区域可分为两部分:
上半部分(黄色):输入是当前时刻特征
,经历一个普通的self-attention 模块,得到
下半部分(灰色):输入是上一时刻记忆,也是经历一个self-attention 模块。不同的是,此处用的query Q是当前时刻计算得到的,key K是上一时刻
计算相似性得分,然后再经过 softmax 将得分映射至 (0,1) 区间。最后再将得分与上一时刻记忆
。
通过通道相连将这两个输出拼一起,再乘权重,得到Z。
Z 再与当前时刻特征
Memory Updating 记忆更新
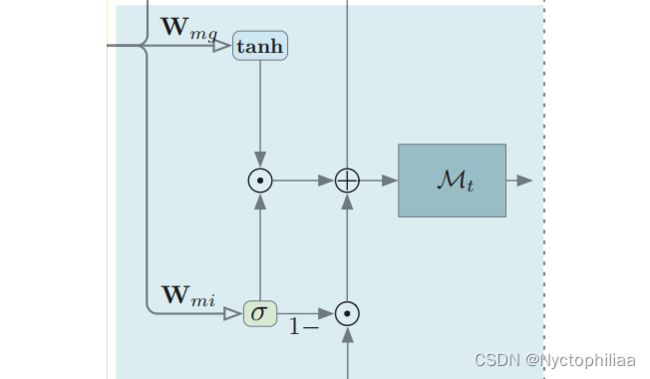
具体操作如下,分两步走:
通过tanh 对输入数据处理,将其映射到[-1,1]。![]() =
= ![]()
通过sigmoid 处理数据,将其映射到[0,1]上,形成gate。
![]() =
=![]()
最后更新记忆信息,![]()
Output 输出
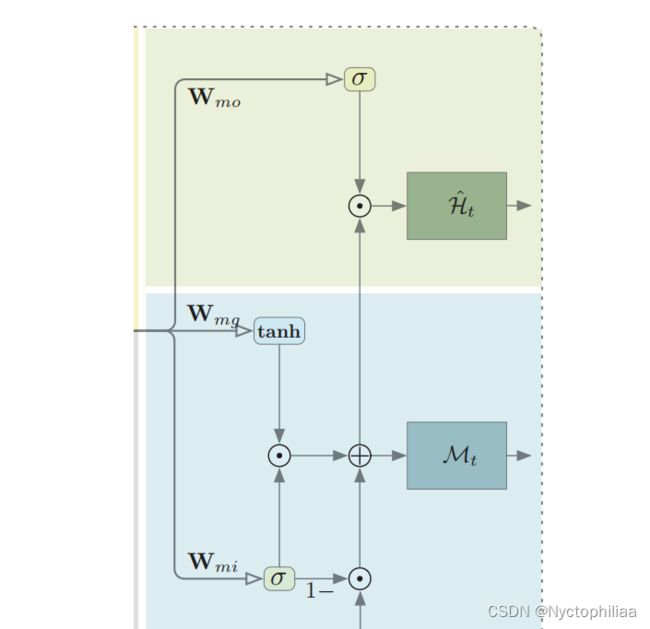
最后就是输出:
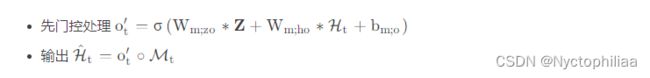
5、文章解读
1、Introduction
时空预测学习已经成为计算机视觉和人工智能广泛领域的一个重要的基础研究问题,并有越来越多地研究团体中开始关注它。尽管ConvLSTM可以捕获长短期建模之外的空间依赖性,但是效果并不好。而Self-attention模块就可以获得单层的全局空间上下文,并且效率更高。此外,研究人员认为当前时间步的特征可以从聚合过去的相关特征中获益——>SAM:用于ConvLSTM的自我注意记忆模块,它利用自我注意的特征聚合机制,通过计算成对的相似度得分,将当前和记忆的特征融合在一起。
将SAM嵌入到ConvLSTM中,构建自我注意ConvLSTM,简称SA-ConvLSTM。消融实验证明了自我注意和附加记忆对不同类型数据的有效性,而且它在所有数据集上以更少的参数和更高的效率获得了最好的结果;
2、相关工作
基于ConvRNN的时空预测:自从ConvLSTM提出以后产生了许多变种,例如PredRNN,PredRNN++和MIM。但是它们很容易遭受梯度消失的问题,而且其记忆单元往往集中在局部空间依赖性上。本文提出了一种自注意记忆单元,既能通过高速公路中的自适应更新获得长期的时间依赖性,又能通过自注意有效提取全局的空间依赖性;
Self-Attention模块:近些年自注意力机制因其良好的效果也被广泛应用。而本文就是在自注意力机制的基础上提出了SAM用于解决上面提出的长期空间依赖问题;
3、实验
1、数据集
MovingMNIST:是一个常用的数据集,描述了两个可能重叠的数字以恒定的速度移动,并在图像边缘反弹。图像大小为64×64×1,每个序列包含20帧,10个输入,10个预测;
TaxiBJ:从混乱的现实环境中采集,包含连续从北京出租车GPS监视器上采集的交通流图像。其中的每一帧都是一个32 × 32 × 2的图像网格。两个通道表示此时进出同一区域的交通流量(我们使用4个已知帧来预测接下来的4帧(未来两个小时的交通状况));
KTH:包含6类人类行为由25人在4种不同的场景中完成。文章遵循了之前作品中的设置来构建训练和测试集。图像大小从320 × 240调整为128 × 128。训练时使用10帧来预测接下来的10帧,推理时使用20帧;
2、消融实验
本文对MovingMNIST和TexiBJ进行了消融研究,以评估不同类型数据的模型:
MovingMNIST中的运动变化是平稳的,需要对局部动态进行精确建模。而TexiBJ则采用像素值的演化来表示交通流的变化;
因此,TexiBJ比MovingMNIST具有更多的远程空间依赖性;
实验结果如下表所示:
本文用SSIM、MSE、MAE等方法来衡量预测质量。ConvLSTM是基线模型,评估了四个变量,包括第3节中的基础模型。带额外内存的ConvLSTM和SA-ConvLSTM(图1中带或不带Zm);
SSIM:结构相似性,值越大,表示图像失真越小;MSE:均方根误差;MAE:平均绝对误差,MAE越小表示模型越好
3、实验结果
在MovingMNIST上,不同模型之间的定量比较详见下表,其中报告了平均结果:

采用PredRNN、PredRNN++ 、MIM 等模型进行比较,其中MIM实现了近年来最先进的方法。所有模型都是基于之前的10帧来预测接下来的10帧。并且遵循PredRNN、PredRNN++和MIM的实验设置和超参数进行比较。与各种传统的模型相比,SA-ConvLSTM模型在参数更少,结构更加简洁的同时还有着相似甚至更优的得分。模型规模较小的原因是在提出的自我注意记忆中采用了深度可分离卷积,减少了可训练参数;
TaxiBJ:每个模型通过4个已知帧来预测接下来的4帧(未来2小时的交通状况)。我们采用框架的MSE作为度量。定量比较和可视化对比如下表/图所示:
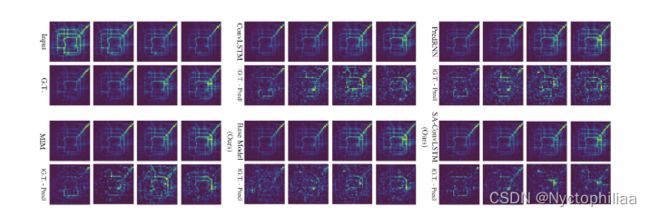
预测和事实之间的绝对差异被展示出来。颜色越亮,绝对误差越高。提出的SA-ConvLSTM比MIM降低了平均MSE误差约9.3%。
KTH:本文用最后10帧来预测接下来的20帧。SA-ConvLSTM在KTH数据集上表现出了它的高效率和灵活性。比较结果如下所示:
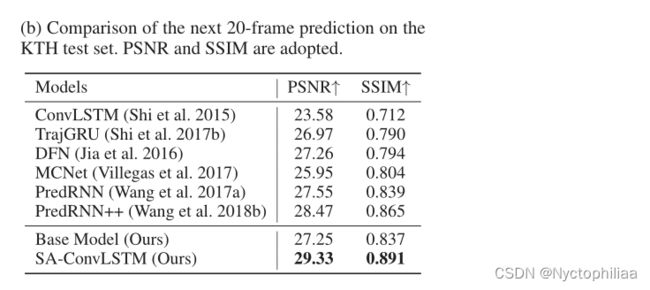
PSNR是峰值信噪比,是一种评价图像的客观标准,它具有局限性,一般是用于最大值信号和背景噪音之间的一个工程项目,越大越好。
4、结论
本文提出了SA-ConvLSTM用于时空预测,由于对当前时间步长的预测可以从过去的相关特征中获益,文章构建了一个自注意记忆模块,以捕获空间和时间维度上的长期依赖性。在三种不同的数据集上进行的消融实验证明了自注意和附加记忆M对不同类型数据的有效性;
二、深度学习
一、GRU前向传播
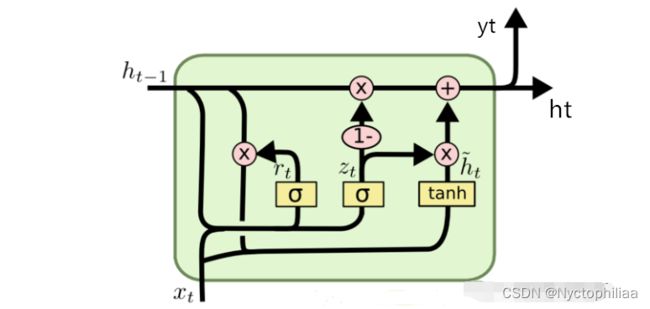

二、GRU反向传播
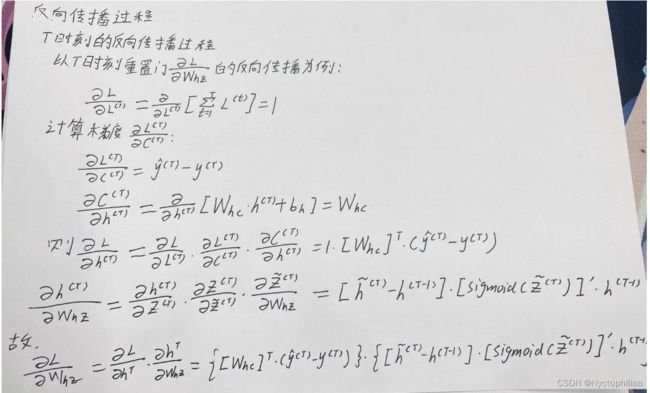

三、GRU代码实现
一、导入数据库以及数据加载与预处理
导入必要的库:NumPy,Pandas,PyTorch,PyTorch中的DataLoader,Matplotlib以及tqdm。
- 检查GPU是否可用,并相应地设置设备(cuda或cpu)。
- 从CSV文件读取数据到Pandas DataFrame,将其转换为时间序列 (
ts)。 - 对时间序列进行小时级别的重采样 (
ts_sample_h)。
import numpy as np
import pandas as pd
import torch
from torch.utils.data import Dataset, DataLoader
import matplotlib.pyplot as plt
from tqdm import tqdm
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
value = pd.read_csv(r'dataset/A5M.txt', header=None)#(14772, 1)
time = pd.date_range(start='200411190930', periods=len(value), freq='5min')
ts = pd.Series(value.iloc[:, 0].values, index=time)
ts_sample_h = ts.resample('H').sum()
二、定义数据集以及数据处理函数
定义用于处理数据的自定义PyTorch数据集类 (MyDataset)。
- 定义一个处理时间序列数据用于训练和测试的函数。
- 将数据分为训练集和测试集。
- 对数据进行归一化,并创建带有相应标签的序列。
class MyDataset(Dataset):
def __init__(self, data):
self.data = data
def __getitem__(self, item):
return self.data[item]
def __len__(self):
return len(self.data)
def nn_seq_us(B):
dataset = ts_sample_h
# split
train = dataset[:int(len(dataset) * 0.7)]
test = dataset[int(len(dataset) * 0.7):]
m, n = np.max(train.values), np.min(train.values)
# print(m,n)
def process(data, batch_size, shuffle):
load = data
load = (load - n) / (m - n)
seq = []
for i in range(len(data) - 6):
train_seq = []
train_label = []
for j in range(i, i + 6):
x = [load[j]]
train_seq.append(x)
train_label.append(load[i + 6])
train_seq = torch.FloatTensor(train_seq)
train_label = torch.FloatTensor(train_label).view(-1)
seq.append((train_seq, train_label))
seq = MyDataset(seq)
seq = DataLoader(dataset=seq, batch_size=batch_size, shuffle=shuffle, num_workers=0, drop_last=False)
return seq
Dtr = process(train, B, False)
Dte = process(test, B, False)
return Dtr, Dte, m, n
三、GRU模型定义
class GRU(torch.nn.Module):
def __init__(self, hidden_size, num_layers):
super().__init__()
self.input_size = 1
self.hidden_size = hidden_size
self.num_layers = num_layers
self.output_size = 1
self.num_directions = 1
self.gru = torch.nn.GRU(self.input_size, self.hidden_size, self.num_layers, batch_first=True)
self.linear = torch.nn.Linear(self.hidden_size, self.output_size)
def forward(self, input_seq):
batch_size, seq_len = input_seq.shape[0], input_seq.shape[1]
h_0 = torch.randn(self.num_directions * self.num_layers, batch_size, self.hidden_size).to(device)
# output(batch_size, seq_len, num_directions * hidden_size)
output, _ = self.gru(input_seq, (h_0))
pred = self.linear(output)
pred = pred[:, -1, :]
return pred
四、训练与可视化
- 初始化模型、损失函数和优化器。
- 使用均方误差损失进行50个周期的训练。
- 绘制训练损失随着周期的变化图表。
Dtr, Dte, m, n= nn_seq_us(64)
hidden_size, num_layers = 10, 2
model = GRU(hidden_size, num_layers).to(device)
loss_function = torch.nn.MSELoss().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=1.5e-3)
# training
trainloss_list = []
model.train()
for epoch in tqdm(range(50)):
train_loss = []
for (seq, label) in Dtr:
seq = seq.to(device)#torch.Size([64, 80, 1])
label = label.to(device)#torch.Size([64, 1])
y_pred = model(seq)
loss = loss_function(y_pred, label)
train_loss.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
trainloss_list.append(np.mean(train_loss))
# training_loss的图
plt.plot(trainloss_list)
plt.xlabel("Epoch")
plt.ylabel("MSE")
plt.title("average of Training loss")
plt.show()
五、测试
pred = []
y = []
model.eval()
for (seq, target) in Dte:
seq = seq.to(device)
target = target.to(device)
y_pred = model(seq)
pred.append(y_pred)
y.append(target)
y=torch.cat(y, dim=0)
pred=torch.cat(pred, dim=0)
y = (m - n) * y + n
pred = (m - n) * pred + n#torch.Size([179, 1])
print('MSE:', loss_function(y, pred))
# plot
plt.plot(y.cpu().detach().numpy(), label='ground-truth')
plt.plot(pred.cpu().detach().numpy(), label='prediction')
plt.xlabel("Time")
plt.ylabel("traffic demand")
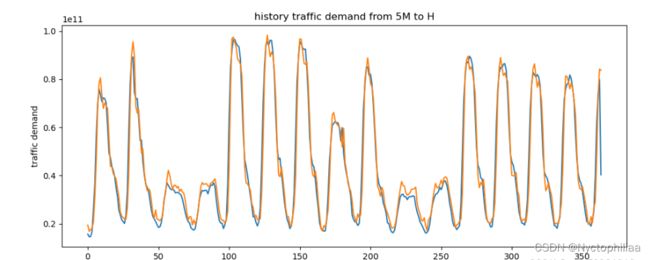
plt.title("history traffic demand from 5M to H")
plt.show()

总结
GRU和LSTM都是为了解决长期依赖问题而设计的,但GRU通过减少参数数量和简化结构,提供了一种更为轻量级的选择。在实际应用中,选择使用哪个取决于任务的性质和数据的特点。LSTM包含三个门控单元,分别是输入门、遗忘门和输出门。GRU只包含两个门控单元,即更新门和重置门。