[2014]Intriguing properties of neural networks
仅用作笔记学习使用,侵权联系立删!
两种特性:
1、 个别高层次单元 和 高层次单元的随机线性组合 没有太大的差异【这表明,在神经网络的高层中包含语义信息的是空间,而不是个体单元。】
2、深度神经网络学习的输入-输出映射在很大程度上不连续的【稍微添加一点扰动,模型就会得到图像的错误分类,特别注意的是,这种扰动跟数据集无关,对不同是数据集添加同样的扰动,不同的模型都会得到错误的分类,也就是说这种扰动是针对神经网络模型而言的】
个体单元的语义含义(the semantic meaning of individual units)
展示了φ(x)的随机投影与φ(x)的坐标在语义上无法区分。一般情况下,似乎是整个激活空间而非单个单元包含了大部分语义信息。
Efficient estimation of word representations in vector space也指出,在向量空间中,单词的各个方向都得到了表示,从而产生了强烈的语义编码关系和类比。同时,向量表示在空间的旋转下是稳定的,因此向量表示的各个单元不太可能包含语义信息。
神经网络对其输入的微小扰动的稳定性
希望神经网络在小的扰动下会有稳定的表现,即有较强的鲁棒性。但是,实验表明对测试图像施加一个肉眼难以观察的非随机扰动,可以任意改变网络的预测。
这些扰动可以通过优化输入 实现最大化预测误差来找到的。
将这些受到干扰的样本称为“对抗样本”
抗性样本相对稳健,并且在具有不同层数、激活函数或在训练数据的不同子集上训练的神经网络之间共享。
字母含义介绍
![]() 表示输入图像;
表示输入图像; ![]() 表示某一层的激活值;
表示某一层的激活值;  表示正则化中的权重衰减因子
表示正则化中的权重衰减因子
![]() 表示数据中未训练网络的保留图像集
表示数据中未训练网络的保留图像集  表示第
表示第  个隐藏单元相关的自然基向量
个隐藏单元相关的自然基向量
 表示随机向量
表示随机向量
之前的工作隐藏单元的激活 解释为有意义的特征。他们寻找能最大化这个单一特征的激活值的输入图像,该图像满足(或接近最大可达到的值):

实验发现,随机向量![]() 产生同样的可接解释的语义特性,更正式地说,图片之间存在语义关联。
产生同样的可接解释的语义特性,更正式地说,图片之间存在语义关联。

这表明随机基底比自然基底更适合于检查 ![]() 的性质。这对于神经网络能否在坐标系中解开变动因素的概念提出了质疑。
的性质。这对于神经网络能否在坐标系中解开变动因素的概念提出了质疑。
首先在MNIST数据集上做实验。
将测试集用作![]()
![[2014]Intriguing properties of neural networks_第1张图片](http://img.e-com-net.com/image/info8/f0e74198582a47dbb54b75dff510def2.jpg)
图中显示的图像最大程度地激活了各种单元(自然基底方向上的最大刺激)。每一行中的图像都具有共同的语义属性。
![[2014]Intriguing properties of neural networks_第2张图片](http://img.e-com-net.com/image/info8/7b6fbd06ab5e46c1befbf03d1f3c6ed1.jpg)
图中显示了在随机方向上激活最大化的图像(随机基底方向上的最大刺激)。每一行中的图像都具有共同的语义属性。
接着在AlexNet上重复实验
将验证集作为![]()
![[2014]Intriguing properties of neural networks_第3张图片](http://img.e-com-net.com/image/info8/cba2e198116149f6bb54965a835ad3b7.jpg)
对单个单元刺激最大的图像(在自然基底方向上刺激最大)。每一行中的图像都有许多共同的语义特征。
![[2014]Intriguing properties of neural networks_第4张图片](http://img.e-com-net.com/image/info8/163b043f1fa648a5973597bcbf9dd712.jpg)
在随机方向上产生最大激活的图像(随机基底方向上的最大刺激)。每一行中的图像都有许多共同的语义特征。
尽管这些分析可以揭露 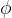 对于输入特定分布的子集产生不变性的能力,但是并没有解释在定义域内其他部分的行为。
对于输入特定分布的子集产生不变性的能力,但是并没有解释在定义域内其他部分的行为。
研究表明,单元级别的验证方法在解释深度神经学习网络所学习到的表示复杂性除了是一种直觉外,实用性相对较小。全局神经网络检测可以解释模型做出正确分类决策时发挥的作用,并且可以用于识别 给定输入实例能够正确被分类的输入部分。换句话说就是,可以使用训练好的模型进行弱监督定位。
神经网络的盲点
一般而言,神经网络的输出层单元是其输入的高度非线性函数。当使用交叉熵损失函数(使用 Softmax 激活函数)进行训练时,输出层表示给定输入(以及到目前为止呈现的训练集)的标签的条件分布。
有些研究认为输入和输出之间非线性层的堆叠是模型对输入空间的非局部广义先验的编码方式,也就是说输出单元可以为输入空间中不包含训练实例的区域分配非显著概率【让原理训练实例的样本点减少对分类训练的影响我也不知道这样理解对不对】(大概也是非epsilon 概率)。例如,这些区域可以代表来自不同视角的相同物体,虽然距离相对较远(在像素空间中),但它们共享原始输入的标签和统计结构。这些论点的前提是在接近训练实例的地方进行局部泛化的工作是有效的。特别是对于给定的训练输入,在半径足够小的邻域内,模型会赋予满足条件![]() 的
的![]() 被正确分类的高概率。【这种平滑先验通常适用于计算机视觉问题。一般来说,对于给定图像的几乎不可察觉的微小扰动通常不会改变底层类别。】
被正确分类的高概率。【这种平滑先验通常适用于计算机视觉问题。一般来说,对于给定图像的几乎不可察觉的微小扰动通常不会改变底层类别。】
本文提出的一个主要结论是,在深度神经网络中,许多卷积核方法所基于的平滑性假设不成立。
实验验证:通过使用简单的优化过程,我们能够找到对抗性示例。在某种意义上,我们描述的是一种以有效的方式(通过优化)遍历网络所表示的流形,并在输入空间中找到adversarial examples的方法。
说明
![]() 表示给定的图像
表示给定的图像
![]() 表示目标标签
表示目标标签
![]() 表示 将图像像素值向量映射到离散标签集的分类器。
表示 将图像像素值向量映射到离散标签集的分类器。
![]() 表示
表示  关联的连续损失函数。
关联的连续损失函数。
实验的目的是解决下列优化问题:
最小化![]() 满足以下条件:
满足以下条件:
![]()
![]()
 不是唯一的,但是本文为任意选择的最小值
不是唯一的,但是本文为任意选择的最小值![]() 给定一个
给定一个![]() 来表示,通俗的讲,
来表示,通俗的讲,![]() 是被分类器分类为标签为
是被分类器分类为标签为 的最接近
的最接近 的图像。
的图像。
很显然,![]() ,所以只有
,所以只有![]() 时,任务比较繁琐。为了计算
时,任务比较繁琐。为了计算![]() 的近似值使用的是盒式约束 L-BFGS 。具体来说,我们可以通过线性搜索找到
的近似值使用的是盒式约束 L-BFGS 。具体来说,我们可以通过线性搜索找到![]() 的最小近似值
的最小近似值 ,此时下面问题的最小值满足
,此时下面问题的最小值满足 ![]() 。
。
在![]() 的条件下,使得
的条件下,使得![]() 最小
最小
实验结果
对于每一个样本生成非常相似、在视觉上难以进行区分的对抗样本,这些样本被原始网络错误分类。获取示例http://goo.gl/huaGPb
![[2014]Intriguing properties of neural networks_第5张图片](http://img.e-com-net.com/image/info8/22df94a13d964fe79a9fd0211bb2eb47.jpg)
模型泛化:用不同的超参数(层数、正则化或初始权重)从头开始训练的网络,会有相对较多的例子被错误分类。
交叉训练集泛化:在不相连的训练集上从头开始训练的网络,会有相对较多的例子被错误分类。
以上结果表明,对抗样本在某种程度上是普遍存在的,并不仅仅是对特定模型的过拟合或对训练集的具体选择所导致的结果。 初步验证将对抗性样本反馈到训练中,可能提高生成模型的泛化能力。