pytorch集智-2单车预测器
完整代码在个人主页简介链接pytorch路径下可找到
1 单车预测器1.0
1.1 人工神经元
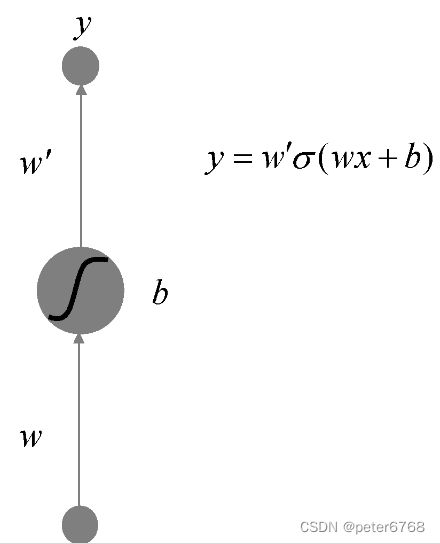
对于sigmoid函数来说,w控制函数曲线的方向,b控制曲线水平方向位移,w'控制曲线在y方向的幅度
1.2 多个人工神经元
模型如下
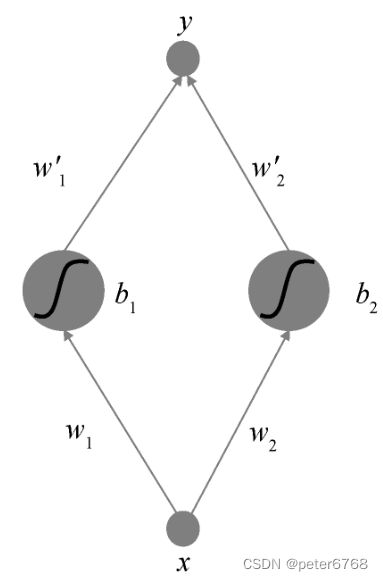
数学上可证,有限神经元绘制的曲线可以逼近任意有限区间内的曲线(闭区间连续函数有界)
1.3 模型与代码
通过训练可得到逼近真实曲线的神经网络参数
通过梯度下降法寻找局部最优(如何寻找全局最优后面考虑)
思考 n个峰需在一个隐层要多少隐单元?材料说3个峰10个单元就够了,理论上算,最少需要5个,可能保险起见,加其他一些不平滑处,就弄了10个
初次代码如下
from os import path
import numpy as np
import pandas as pd
import torch
import torch.optim as optim
import matplotlib.pyplot as plot
DATA_PATH = path.realpath('pytorch/jizhi/bike/data/hour.csv')
class Bike():
def exec(self):
self.prepare_data_and_params()
self.train()
def prepare_data_and_params(self):
self.data = pd.read_csv(DATA_PATH)
counts = self.data['cnt'][:50]
self.x = torch.FloatTensor(np.arange(len(counts)))
self.y = torch.FloatTensor(np.array(counts, dtype=float))
self.size = 10
self.weights = torch.randn((1, self.size), requires_grad=True)
self.biases = torch.randn((self.size), requires_grad=True)
self.weights2 = torch.randn((self.size, 1), requires_grad=True)
def train(self):
rate = 0.001
losses = []
x, y = self.x.view(50, -1), self.y.view(50, -1) # reshape
for num in range(30000):
hidden = x * self.weights + self.biases
hidden = torch.sigmoid(hidden)
predictions = hidden.mm(self.weights2)
loss = torch.mean((predictions - y) ** 2)
losses.append(loss.data.numpy())
if num % 3000 == 0:
print(f'loss: {loss}')
loss.backward()
self.weights.data.add_(- rate * self.weights.grad.data)
self.biases.data.add_(- rate * self.biases.grad.data)
self.weights2.data.add_(- rate * self.weights2.grad.data)
self.weights.grad.data.zero_()
self.biases.grad.data.zero_()
self.weights2.grad.data.zero_()
# plot loss
#plot.plot(losses)
#plot.xlabel('epoch')
#plot.ylabel('loss')
#plot.show()
# plot predict
x_data = x.data.numpy()
plot.figure(figsize=(10, 7))
xplot, = plot.plot(x_data, y.data.numpy(), 'o')
yplot, = plot.plot(x_data, predictions.data.numpy())
plot.xlabel('x')
plot.ylabel('y')
plot.legend([xplot, yplot], ['Data', 'prediction with 30000 epoch'])
plot.show()
def main():
Bike().exec()
if __name__ == '__main__':
main()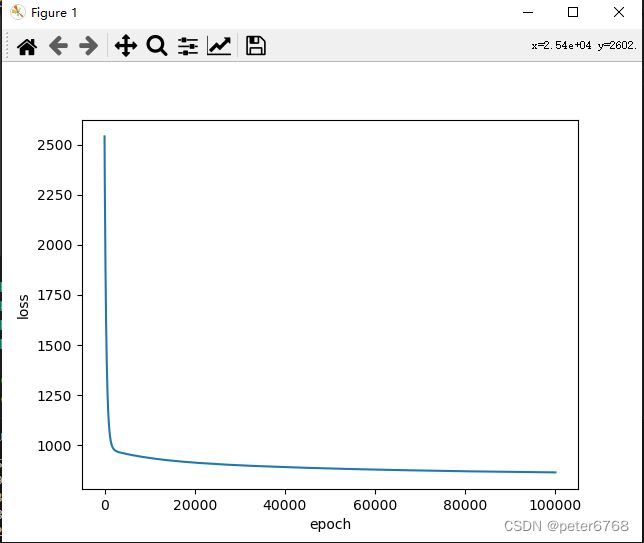

拟合有问题,原因是拟合次数不够,为啥不够?从sklearn学习了解到,神经网络对输入参数敏感,一般来说需要对数据做标准化处理。具体来说,第一个隐层输出范围变成-50-50,0.0001学习率情况下100000次也不够,可以对数据做预处理,减小x跨度,变为0-1,可加快训练速度,进行如下改动再次训练
self.x = torch.FloatTensor(np.arange(len(counts))) / len(counts)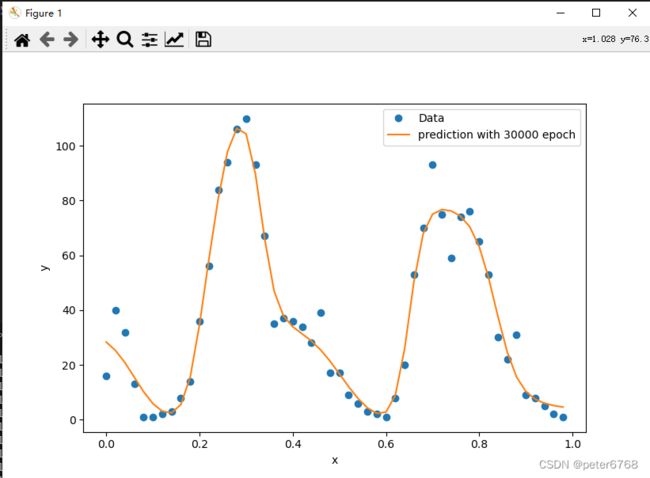
正确了,再取50个点预测一下
def predict_and_plot(self):
counts_predict = self.data['cnt'][50:100]
x = torch.FloatTensor((np.arange(len(counts_predict), dtype=float) + 50) / 100)
y = torch.FloatTensor(np.array(counts_predict, dtype=float))
# num multiply replace matrix multiply
hidden = x.expand(self.size, len(x)).t() * self.weights.expand(len(x), self.size)
hidden = torch.sigmoid(hidden)
predictions = hidden.mm(self.weights2)
loss = torch.mean((predictions - y) ** 2)
print(f'loss: {loss}')
x_data = x.data.numpy()
plot.figure(figsize=(10, 7))
xplot, = plot.plot(x_data, y.data.numpy(), 'o')
yplot, = plot.plot(x_data, predictions.data.numpy())
plot.xlabel('x')
plot.ylabel('y')
plot.legend([xplot, yplot], ['data', 'prediction'])
plot.show()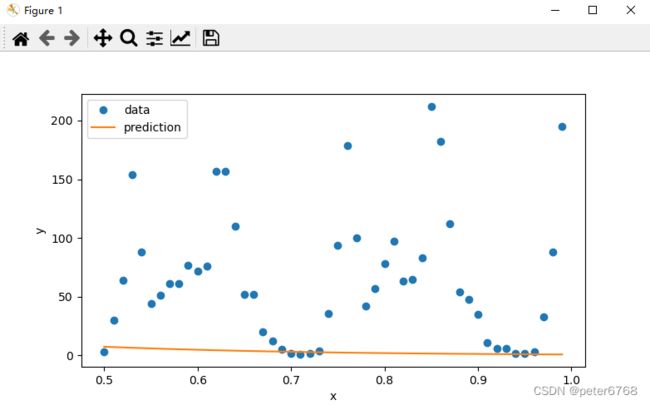
预测失败,可能是过拟合
2 单车预测器2.0
2.1 数据预处理
通过上节学习和之前写的sklearn博客发现,神经网络训练前需要预处理数据,主要有1数值型变量需要范围标准化2数值型类型变量需处理为onehot。标准化可用sklearn的scaler,也可手动标准化,类型变量可用pd.get_dummies操作。直接开始操作
def prepare_data_and_params_2(self):
# type columns to dummy
self.data = pd.read_csv(DATA_PATH)
dummy_fields = ['season', 'weathersit', 'mnth', 'hr', 'weekday']
for each in dummy_fields:
dummies = pd.get_dummies(self.data[each], prefix=each, drop_first=False)
self.data = pd.concat([self.data], dummies)
drop_fields = ['season', 'weathersit', 'mnth', 'hr', 'weekday', 'instant', 'dteday', 'workingday', 'atemp']
self.data = self.data.drop(drop_fields, axis=1)
# decimal columns to scaler
quant_features = ['cnt', 'temp', 'hum', 'windspeed']
scaled_features = {}
for each in quant_features:
mean, std = self.data[each].mean(), self.data[each].std()
scaled_features[each] = [mean, std]
self.data.loc[:, each] = (self.data[each] - mean) / std
self.tr, self.te = self.data[:-21 * 24], self.data[-21 * 24:]
target_fields = ['cnt', 'casual', 'registered']
self.xtr, self.ytr = self.tr.drop(self.tr.drop[target_fields], axis=1), self.tr[target_fields]
self.xte, self.yte = self.te.drop(self.te.drop[target_fields], axis=1), self.te[target_fields]
self.x = self.xtr.values
y = self.ytr.values.astype(float)
self.y = np.reshape(y, [len(y), 1])
self.loss = []2.2 构造神经网络
def train_and_plot2(self):
input_size = self.xtr.shape[1]
hidden_size=10
output_size=1
batch_size=128
neu = torch.nn.Sequential(
torch.nn.Linear(input_size, hidden_size),
torch.nn.Sigmoid(),
torch.nn.Linear(hidden_size, output_size)
)
cost = torch.nn.MSELoss()
optimizer = torch.optim.SGD(neu.parameters(), lr=0.01)2.3 数据批处理
为啥要批处理?如果数据太多,每个iter直接处理所有数据会比较慢
for i in range(1000):
batch_loss = []
for start in range(0, len(self.x), batch_size):
end = start + batch_size if start + batch_size < len(self.x) else len(self.x)
xx = torch.FloatTensor(self.x[start:end])
yy = torch.FloatTensor(self.y[start:end])
predictions = neu(xx)
loss = cost(predictions, yy)
optimizer.zero_grad()
loss.backward()
optimizer.step()
batch_loss.append(loss.data.numpy())
if i % 100 == 0:
self.loss.append(np.mean(batch_loss))
print(i, np.mean(batch_loss))
plot.plot(np.arange(len(self.loss)) * 100, self.loss)
plot.xlabel('epoch')
plot.ylabel('MSE')
plot.show()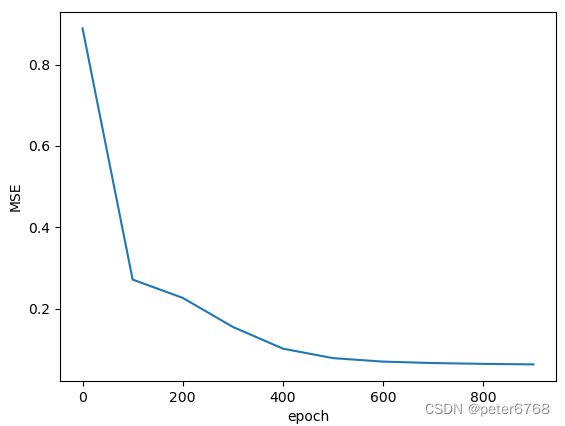
2.4 测试神经网络
原始数据是从2011-2012两个完整年,按教材,取2012最后21天作测试集预测
def predict_and_plot2(self):
targets = self.yte['cnt']
targets = targets.values.reshape([len(targets), 1]).astype(float)
x = torch.FloatTensor(self.xte.values.astype(float))
y = torch.FloatTensor(targets)
predict = self.neu(x)
predict = predict.data.numpy()
fig, ax = plot.subplots(figsize=(10, 7))
mean, std = self.scaled_features['cnt']
ax.plot(predict * std + mean, label='prediction')
ax.plot(targets * std + mean, label='data')
ax.legend()
ax.set_xlabel('date-time')
ax.set_ylabel('counts')
dates = pd.to_datetime(self.rides.loc[self.te.index]['dteday'])
dates = dates.apply(lambda d: d.strftime('%b %d'))
ax.set_xticks(np.arange(len(dates))[12::24])
ax.set_xticklabels(dates[12::24], rotation=45)
plot.show()
发现2012最后21天前半段还行,后半段有差异,看日历发现临近圣诞节,可能不能用正常日程预测
2.5 改进与分析(重要)
这节有啥用?上节圣诞节预测不准,为啥?这节可以通过分析神经网络回答这个问题
怎么分析?本节主要通过分析神经网络参数来在底层寻找原因,帮助分析问题
在异常处将多个神经源绘制独自的曲线,绘制其图像,分析找原因,比如趋势相同,趋势相反这种曲线,重点分析对象。适用于神经元较少,可以一个一个神经元看,多了就不行了