了解Ceph 分布式存储
内容概括
1、存储发展史
随着Open Stack的快速发展,给Caph的发展注入了强心剂,越来越多的人使用Ceph作为Open Stack的底层共享存储,Ceph在中国的社区也蓬勃发展起来。近两年Open Stack火爆度不及当年,借助于云原生尤其是Kubernetes技术的发展,作为底层存储的基石,Ceph再次发力,为Kubernets有状态化业务提供了存储机制的实现。
企业中使用存储按照其功能,使用场景,一直在持续发展和迭代,大体上可以分为四个阶段:
- DAS: Direct Attached Storage,即
直连存储,第一代存储系统,通过SCSI总线扩展至一个外部的存储,计算机将其识别为一个块设备,例如常见的硬盘等; - NAS:Network Attached Storage, 即
网络附加存储,通过网络协议如NFS远程获取后端文件服务器共享的存储空间,将文件存储单独分离出来; - SAN:Storage Area Network,即
存储区域网络,分为IP-SAN和FC-SAN,即通过TCP/IP协议和FC(Fiber Channel)光纤协议连接到存储服务器; - *Object Storage:即
对象存储,随着大数据的发展,越来越多的图片,视频,音频静态文件存储需求,动则PB以上的存储空间,需无限扩展。
存储的发展,根据不同的阶段诞生了不同的存储解决方案,每一种存储都有它当时的历史诞生的环境以及应用场景,解决的问题和优缺点。
1.1、区别如下
- DAS 购置成本低,配置简单,使用过程和使用本机硬盘并无太大差别,对于服务器的要求仅仅是一个外接的SCSI口。
DAS 成本低廉但是可扩展性有限、无法多主机实现共享、目前已经很少使用了。 - NAS:网络存储服务器使用TCP网络协议连接至文件共享存储、常见的有NFS、CIFS协议等;通过网络的方式映射存储中的一个目录到目标主机,如/data 。NAS网络存储使用简单,通过IP协议实现互相访问,多台主机可以同时共享同一个存储。
但是NAS网络存储的性能有限,可靠性不是很高。 - SAN:实际是一种专门为存储建立的独立于TCP/IP网络之外的专用网络。目前一般的SAN提供2Gb/S到4Gb/S的传输速率,同时SAN网络独立于数据网络存在,因此存取速度很快,另外SAN一般采用高端的RAID阵列,使SAN的性能在几种专业网络存储技术中傲视群雄。SAN由于其基础是一个专用网络,因此扩展性很强,不管是在一个SAN系统中增加一定的存储空间还是增加几台使用存储空间的服务器都非常方便。
但需要单独建立光纤网络,价格昂贵,异地扩展比较困难。 - Object Storage:对象存储通过网络使用API访问一个无限扩展的分布式存储系统、兼容于S3风格、原生PUT/GET等协议类型。表现形式就是可以无限使用存储空间,通过PUT/GET无限上传和下载。可扩展性极强、使用简单。
但是只使用于静态不可编辑文件,无法为服务器提供块级别存储。
2、什么是Ceph?
Ceph在一个统一的存储系统中同时提供了对象存储、块存储和文件存储,即Ceph是一个统一存储,能够将企业中的三种存储需求统一汇总到一个存储系统中,并提供分布式、横向扩展,高度可靠性的存储系统,Ceph存储提供的三大存储接口。
2.1、Ceph架构原理

(1)基础存储系统(RADOS)
RADOS 是理解Ceph 的基础核心。
物理上,RADOS 由大量的存储设备节点组成,每个节点拥有自己的硬件资源(CPU、内存、硬盘、网络),并运行着操作系统和文件系统。逻辑上,RADOS是一个完整的分布式对象存储系统,Ceph本身的高可靠、高扩展、高性能等都是依托于这个对象。
(2)基础库(LIBRADOS)
LIBRADOS 是基于RADOS 对象在功能层和开发层进行的抽象和封装。
可以向上提供使用接口API,主要包括C、C++、Java、Python 等。这样应用上的特殊需求变更就不会涉及到Ceph存储本身,保障其安全性并且解除了存储系统和上层应用的耦合性。
(3) 存储应用接口(RADOS GW、RBD、Ceph FS)
存储应用接口层 包括了三个部分:RADOS Gateway、 Reliable Block Device 、 Ceph FS,其作用是在librados库的基础上提供抽象层次更高、更便于应用或客户端 直接 使用的上层接口。其中,RADOS GW是一个提供S3 RESTful API的 网关 ,以供相应的对象存储应用 使用;RBD则提供了一个标准的块设备接口 ;Ceph FS是一个POSIX兼容的分布式文件系统。
既然Librados API能提供对象存储应用可以使用的接口,为什么还要搞一个RadosGW API?
其实这个是基于不同使用者维度来考虑的,就像应用系统的使用者和开发者两个不同维度。使用者仅仅需要知道这个应用系统提供了什么功能,到什么界面去完成使用就可以了。但是开发者可能需要从后台代码当中去解决一系列基于性能、并发量、易用易维护性等维度出现的问题。同样,对于RadosGW API来讲,它仅仅提供了一些通用、固定、易用的少数使用维度的接口,而Librados API则是一个丰富的具备各种使用、开发等维度的接口库。
2.2、Ceph物理组件架构
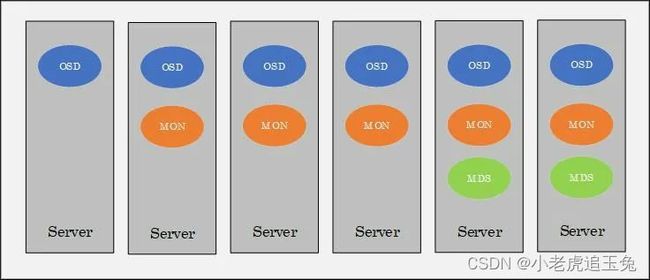
RADOS 是Ceph的核心,我们谈及的物理组件架构也只是RADOS 的物理架构。
RADOS 集群是由若干服务器组成,每一个服务器上都会运行RADOS 的核心守护进程(OSD、MON、MDS)。具体守护进程的数量需要根据集群的规模和既定的规则来配置。
Ceph有两个重要的组件组成:Ceph Monitors(Ceph监视器)和Ceph OSDs(Ceph OSD 守护进程)。
其中Ceph Monitor作为集群中的控制中心,拥有整个集群的状态信息,各个组件如OSDs将自己的状态信息报告给Ceph Monitor;为了保障集群的可用性,
集群中通常有多个OSD组成,OSD即Object Storage Daemon,负责Ceph集群中真正数据存储的功能,也就是我们的数据最终都会写入到OSD中。除了Monitor之外,根据Ceph提供的不同功能,还有其他组件,包括:
- Ceph Monitors(ceph-mon),为了保障集群的可用性,高可用,安装节点数目为2n+1,至少三个来保障集群算法的正常运行;
- Ceph OSDs (ceph-osd) ,所有提供磁盘的节点上都要安装OSD 守护进程;
- Ceph MDS (ceph-mds),用于提供CephFS文件存储,提供文件存储所需元数据管理,它不需要运行在太多的服务器节点上。安装节点模式保持主备保护即可;
- Ceph RGW (ceph-rgw),用于提供Ceph对象存储网关,提供存储网关接入;
- Ceph Manager (ceph-mgr) ,提供集群状态监控和性能监控。
什么是集群的状态?Ceph Monitor中保存的集群状态根据其功能角色的不同,分为以下几个map状态表:
- Monitor Maps,集群Ceph Monitor集群的节点状态,通过ceph mon dump可以获取;
- OSD Maps,集群数据存储节点的状态表,记录集群中OSD状态变化,通过ceph osd dump可以获取;
- PGs Maps,PGs即placement group,表示在OSD中的分布式方式,通过ceph pg dump可以获取;
- Crush Maps,Crush包含资源池pool在存储中的映射路径方式,即数据是如何分布的;
- MDS Maps,CephFS依赖的MDS管理组件,可通过ceph mds dump获取,用于追踪MDS状态。
2.3、Ceph数据对象组成
Ceph的数据对象组成这部分主要是想阐述从客户端发出的一个文件请求,到Rados存储系统写入的过程当中会涉及到哪些逻辑对象,他们的关系又是如何的?首先,我们先来列出这些对象:
(1)文件(FILE):用户需要存储或者访问的文件。对于一个基于Ceph开发的对象存储应用而言,这个文件也就对应于应用中的“对象”,也就是用户直接操作的“对象”。
(2)对象(Object):RADOS所看到的“对象”。Object指的是最大size由RADOS限定(通常为2/4MB)之后RADOS直接进行管理的对象。因此,当上层应用向RADOS存入很大的file时,需要将file切分进行存储。
(3)PG(Placement Group):即放置组,逻辑概念,阐述的是Object和OSD之间的地址映射关系,该集合里的所有对象都具有相同的映射策略;object将映射到PG中,PG最终会调度到某个具体的OSD上,一个Object只能映射到一个PG上,一个PG会被映射到多个OSD上。
(4)OSD(Object Storage Device):存储对象的逻辑分区,它规定了数据冗余的类型和对应的副本分布策略;支持两种类型:副本和纠删码。
Ceph的整个数据调度写入流程如下图:
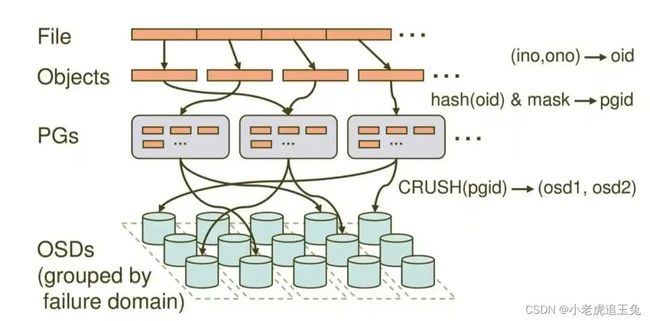
数据的详细映射过程:
(1) File > Object
本次映射为首次映射,即将用户要操作的File,映射为RADOS能够处理的Object。
具体映射操作本质上就是按照Object的最大Size对File进行切分,每一个切分后产生的Object将获得唯一的对象标识Oid。Oid的唯一性必须得到保证,否则后续映射就会出现问题。
(2) Object > PG
完成从File到Object的映射之后, 就需要将每个 Object 独立地映射到 唯一的 PG 当中 去。
Hash(Oid)& Mask > PGid
根据以上算法, 首先是使用Ceph系统指定的一个静态哈希函数计算 Oid 的哈希值,将 Oid 映射成为一个近似均匀分布的伪随机值。然后,将这个伪随机值和 Mask 按位相与,得到最终的PG序号( PG id)。根据RADOS的设计,给定PG的总数为 X(X= 2的整数幂), Mask=X-1 。因此,哈希值计算和按位与操作的整体结果事实上是从所有 X 个PG中近似均匀地随机选择一个。基于这一机制,当有大量object和大量PG时,RADOS能够保证object和PG之间的近似均匀映射。
(3) PG > OSD
最后的 映射就是将PG映射到数据存储单元OSD。RADOS采用一个名为CRUSH的算法,将 PGid 代入其中,然后得到一组共 N 个OSD。这 N 个OSD即共同负责存储和维护一个PG中的所有 Object 。和“object -> PG”映射中采用的哈希算法不同,这个CRUSH算法的结果不是绝对不变的,而是受到其他因素的影响。
① 集群状态(Cluster Map):系统中的OSD状态 。数量发生变化时, CLuster Map 可能发生变化,而这种变化将会影响到PG与OSD之间的映射。
② 存储策略配置。系统管理员可以指定承载同一个PG的3个OSD分别位于数据中心的不同服务器乃至机架上,从而进一步改善存储的可靠性。
2.4、CRUSH 算法
到这里,可能大家又会有一个问题“为什么这里要用CRUSH算法,而不是HASH算法?”
CRUSH 是一种分布式算法,类似于一致性 hash 算法,用于为 RADOS 存储集群控制数据的 分配。
1、如果是把对象直接映射到OSD之上会导致对象与OSD的对应关系过于紧密和耦合,当OSD由于故障发生变更时将会对整个Ceph集群产生影响。
2、于是Ceph 将一个对象映射到RADOS 集群的时候分为两步走:
-
首先使用一致性 hash 算法将对象名称映射到PG
-
然后将PG ID 基于 CRUSH 算法映射到 OSD 即可查到对象
3、这个实时计算操作使用的就是CRUSH 算法
Controllers replication under scalable hashing #可控的、可复制的、可伸缩的一致性 hash 算法。