Autoregressive Visual Tracking(ARTrack)CVPR2023学习笔记
Autoregressive Visual Tracking
论文地址:http://openaccess.thecvf.com//content/CVPR2023/papers/Wei_Autoregressive_Visual_Tracking_CVPR_2023_paper.pdf
动机:
这篇论文的研究动机是传统的视觉目标跟踪方法通常将跟踪视为每帧模板匹配问题,忽略了视频帧之间的时序依赖性。本文的作者提出了一种新的框架,将跟踪视为坐标序列解释任务,通过学习一个简单的端到端模型来进行直接轨迹估计。该方法可以建模轨迹的时序演变,以保持跟踪结果的连贯性。相比现有的基于模板匹配的跟踪器,该方法可以更好地处理目标变形、尺度变化、遮挡和干扰等问题,并且不需要定制的定位头和后处理步骤。
贡献:
这篇论文提出了一个基于自回归模型的视觉目标跟踪框架ARTrack,将跟踪视为坐标序列解释任务,并通过前面的状态影响当前的跟踪结果,从而提高了跟踪的精度。ARTrack相对于现有的基于模板匹配的跟踪器更加简单和直接,避免了定制化的本地化头和后处理。
1、Tracking as Sequence Interpretation
我们把视觉跟踪作为一个连续的坐标解释任务,以条件概率的形式表述:
P ( Y t ∣ Y t − N : t − 1 , ( C , Z , X t ) ) , P\left(Y^t|Y^{t-N:t-1},(C,Z,X^t)\right), P(Yt∣Yt−N:t−1,(C,Z,Xt)),
其中 Z Z Z 和 X t X_t Xt 是时间步 t t t 的给定模板和搜索图像, C C C 是命令标记, Y Y Y 表示与 X X X 关联的目标序列。模板 Z Z Z 也可以通过更新机制在每个时间步长进行更新,或者干脆作为初始模板。
可以看出,我们将跟踪制定为一个时间自回归过程,其中当前的结果是最近 N N N 的过去的函数,以模板和搜索图像为条件。这是一个阶数为 N N N 的自回归模型,简称为 A R ( N ) AR(N) AR(N)模型。具体来说,当 N = 0 N = 0 N=0时,式(1)退化为不以先前状态为条件的逐帧模型 P ( Y t ∣ C , Z , X t ) P(Y t |C, Z, X^t) P(Yt∣C,Z,Xt)。引入的自回归模型与视觉跟踪是兼容的,因为它本身就是一个序列预测的任务。当前帧中的估计目标状态受到相邻的先前目标状态的影响,并且还影响后续帧。我们将此跟踪框架称为 ARTrack,它由以下主要组件组成。
- 序列构建: 给定一个视频序列和一个初始物体框,视觉跟踪器预测一个边界框的序列。它们被映射到一个统一的坐标系中,并被转换成具有共享词汇的离散标记序列。
- 网络架构:我们使用编解码器架构,编码器嵌入视觉特征,解码器解释目标序列。
- 目标函数: 该模型在视频帧上进行训练,用一个结构化的损失函数来最大化目标序列的对数可能性。我们还探索了一个特定任务的目标来提高性能。
1.1、Sequence Construction from Object Trajectory
我们将物体的轨迹描述为具有共享词汇的离散标记序列。
Tokenization
受Pix2Seq框架的启发,我们对连续坐标进行离散化,以避免描述连续坐标所需的大量参数,这称为标记化。具体来说,时间步骤 t t t 的对象框由四个标记组成,即 [ x m i n t , y m i n t , x m a x t , y m a x t ] [x^t_{min} , y^t_{min} , x^t_{max} , y^t_{max}] [xmint,ymint,xmaxt,ymaxt],每个标记是 [ 1 , n b i n s ] [1, n_{bins}] [1,nbins]之间的整数。当 b i n bin bin 的数量大于或等于图像解析时,可以实现零量化误差。然后我们使用量化项来索引可学习的词汇表以获得与坐标相对应的标记。这允许模型根据离散标记来描述对象的位置,并允许语言模型中现成的解码器用于坐标回归。这种新的回归避免了从图像特征到坐标的直接非线性映射,这通常是困难的。在去标记化中,我们将输出的标记特征与共享词汇相匹配,以找到最可能的位置。
Trajectory coordinate mapping
大多数跟踪器裁剪搜索区域以减少计算成本,而不是在全分辨率帧上进行跟踪。这意味着该网络输出当前帧中物体的坐标,相对于搜索区域而言。为了获得统一的表示,需要将不同帧的框映射到同一个坐标系中。在我们的方法中,我们将前面 N N N帧的盒子坐标缓存在全局坐标系中,并在搜索区域被裁剪后将其映射到当前坐标系中。但是,如果我们使用整帧进行搜索,则不再需要这个坐标映射步骤。
Representation range of vocabulary
词汇表的表示范围可以根据搜索区域的大小设置,但由于对象移动快速,前面的轨迹序列有时可能超出搜索区域的边界。为了解决这个问题,我们将表示范围扩展为搜索区域范围的倍数(例如,如果搜索区域范围是 [ 0.0 , 1.0 ] [0.0, 1.0] [0.0,1.0],我们将其扩展为 [ − 0.5 , 1.5 ] [-0.5, 1.5] [−0.5,1.5])。这使得词汇表能够包含位于搜索区域之外的坐标,这反过来又允许模型捕获更多前面的运动线索来跟踪和预测超出搜索区域的边界框。

1.2、Network Architecture
考虑到目标序列是由目标轨迹构建的,我们使用编码器-解码器结构进行学习和推理。
Encoder
编码器可以是一个通用的图像编码器,它将像素编码为隐藏特征表示,例如ConvNet, vision Transformer (ViT),或者混合架构。在这项工作中,我们使用与OSTrack相同的ViT编码器进行视觉特征编码。模板和搜索图像首先被分割成小块,被平面化和投影以生成一系列的标记嵌入。然后我们将模板和搜索标记加上位置和身份嵌入,串联起来,并将它们送入一个普通的ViT骨干网,以编码视觉特征。
Decoder
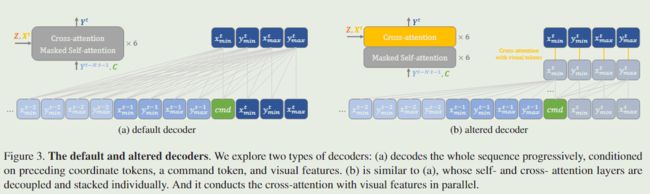
我们使用Transformer解码器生成目标序列。它以前面的坐标标记、命令标记和视觉特征为条件,逐步解码整个序列。命令标记 ( C ) (C) (C)提供了一个轨迹建议,然后将模板 ( Z ) (Z) (Z)与搜索 ( X t ) (X_t) (Xt)相匹配,以获得更准确的坐标预测 ( Y t ) (Y_t) (Yt)。这种简单的解码方法消除了现代视觉跟踪器架构的复杂性和自定义性,例如,定位头和后处理,因为坐标可以立即从共享词汇表中去标记化。解码器需要两种注意力。自注意力(带有因果掩码)在坐标标记之间执行以传达时空信息。交叉注意将运动线索与视觉线索相结合以进行最终预测。两个操作在每个解码器层交替执行,以混合两种嵌入。我们在图 3a 中说明了解码器的结构。为了提高跟踪效率,我们通过修改解码器层来研究修改后的解码器。具体来说,self-和cross-attention层分别解耦和堆叠。这样,我们可以并行对视觉特征进行交叉注意,这是解码器中最耗时的计算。修改后的解码器如图 3b 所示。
1.3、Training and Inference
ARTrack 是一个简单的框架,可以实现端到端的训练和推理。
Training
除了每一帧的训练和优化,ARTrack还通过视频序列进行学习。它采用了一个结构化的目标,即用一个softmax交叉熵损失函数使标记序列的对数可能性最大化:
maximize ∑ t = 1 T log P ( Y t ∣ Y t − N ; t − 1 , ( C , Z , X t ) ) , \text{maximize}\sum\limits_{t=1}^T\log P\left(Y^t|Y^{t-N;t-1},(C,Z,X^t)\right), maximizet=1∑TlogP(Yt∣Yt−N;t−1,(C,Z,Xt)),
其中, T T T 是目标序列的长度。这种学习方法统一了训练和推理之间的任务目标,即保持跨视频帧的定位精度。在启动时 ( t ≤ N ) (t≤N) (t≤N),缓存的时空提示 ( Y t − N : t − 1 ) (Y^{t-N:t-1}) (Yt−N:t−1),并逐由初始的 ( Y 1 ) (Y_1) (Y1)填充,并逐渐用新的预测进行更新。
这是一个通用的目标函数,忽略了令牌的物理属性,例如坐标的空间关系。尽管我们发现这样的与任务无关的目标对于训练模型是有效的,但我们研究了如何结合任务知识来提高性能。具体来说,我们引入了 SIoU 损失来更好地测量预测边界框和地面实况边界框之间的空间相关性。我们首先从估计的概率分布中获取坐标标记。由于采样是不可微的,我们应用分布的期望来表示坐标。然后我们得到预测的边界框,并用ground truth计算它的SIoU。整个损失函数可以写成:
L = L c e + λ L S I o U , \mathcal{L}=\mathcal{L}_{\mathrm{ce}}+\lambda\mathcal{L}_{\mathrm{SIoU}}, L=Lce+λLSIoU,
其中 L c e \mathcal{L}_{\mathrm{ce}} Lce和 L S I o U \mathcal{L}_{\mathrm{SIoU}} LSIoU分别为交叉熵损失和SIoU损失, λ \lambda λ为平衡两个损失项的权重。
Inference
在推理时间,我们使用 a r g m a x argmax argmax抽样法从模型可能性 P ( Y t ∣ Y t − N : t − 1 , ( C , Z , X t ) ) P\left(Y^t|Y^{t-N:t-1},(C,Z,X^t)\right) P(Yt∣Yt−N:t−1,(C,Z,Xt))中进行采样。我们发现其他随机抽样技术或期望的性能与 argmax 采样相当。不需要额外的 EOS 令牌结束序列预测,因为序列长度在我们的问题中是固定的。在获得离散标记后,我们将它们去量化以获得连续坐标。