kvm 虚拟化原理补充:x86虚拟化相关原理
文章目录
-
-
- 1 x86 cpu 虚拟化
- 2 x86 内存虚拟化
- 3 x86 kvm 执行流程
- 4 x86 vm entry/exit
- 5 x86 创建 vm 虚机
- 6. x86 vcpu 调度
- 7 x86 虚拟页表初始化
-
1 x86 cpu 虚拟化
x86硬件辅助虚拟化分为:Intel-VT,AMD-V。
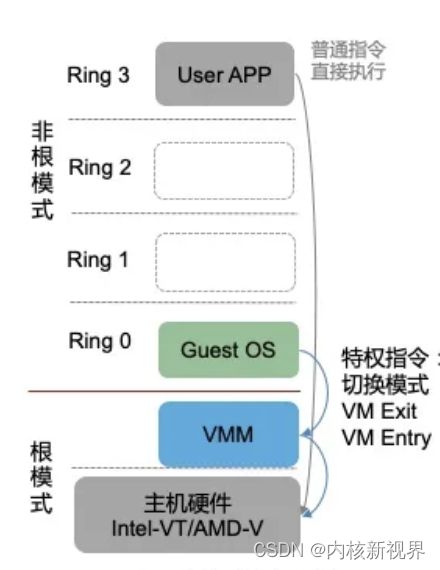
VMM 运行在 VMX root 模式,该模式运行 host os。
客户机 guest os 运行在 VMX non-root 模式。
VMX 分为 root 模式和 non-root 模式,各自都有自己的 0-3 ring 级别。

kvm vcpu 在三种模式中运行:
- 客户模式(Guest Mode):运行 GuestOS,执行客户机非 IO 操作指令。
- 用户模式(User Mode):运行 qemu,实现 IO 模拟与虚机管理。
- 内核模式(Kernel Mode):运行 KVM 内核,实现模式的切换(VM exit/VM entry),执行特权与敏感指令。
kvm内核加载时执行 VMXON 指令进入 VMX 操作模式,VMM 进入 VMX root 模式,可执行 VMXOFF 指令退出。
客户机执行特权或者敏感指令时触发 vm exit,系统挂起客户机,通过 VMCALL 调用 VMM 切换到 root 模式执行,vm exit 开销大。
vmm 执行完成后,可执行 VMLAUCH 或者 VMRESUME 指令触发 vm entry 切换到 non-root 模式,系统自动加载客户机运行(对比 aarch64 则是使用 eret 从 el2 切换到 el1 进入 vcpu)。
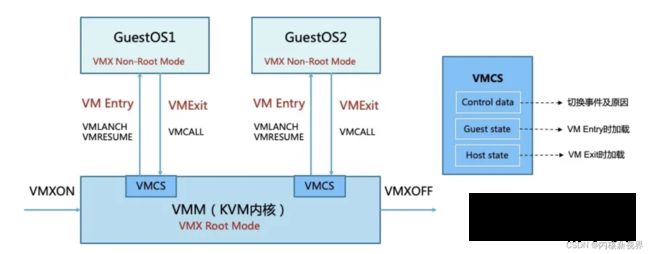
VMX 定义了 VMCS(Virtual Machine Control Structure)数据结构来记录 vcpu 相关的寄存器内容与控制信息,发生 vm exit 或者 vm entry 时需要查询和更新 VMCS。
VMM 为每个 vcpu 维护一个 VMCS,存储在内存中 VMCS 区域,通过 VMCS 指针管理。
VMCS 主要包括三个部分信息:1)control data 主要保存触发模式切换的事件及原因;2)Guest state 保存客户机运行时状态,在 vm entry 时加载;3)Host state 保存 VMM 运行时状态,在 vm exit 时加载;通过读写 VMCS 结构对客户机进行控制。
2 x86 内存虚拟化
EPT 与 VPID
内存存放 cpu 将要执行的指令或者数据,内存大小与访问效率对系统性能至关重要。
内存虚拟化目标是保障内存空间的合理分配,管理,隔离,以及搞笑可靠地使用。
需要将客户机虚拟地址GVA(Guest Virtual Address)转换为主机上的物理地址HPA(Host Physical Address )。没有硬件辅助虚拟化之前,VMM 为每个 Guest 维护一份影子页表,通过软件维护 GVA 到 HPA 的映射。
Intel 引入了硬件辅助内存虚拟化拓展页表EPT(Extend Page Table),AMD 的是嵌入页表NPT(Nested Page Table),作为 cpu 的内存管理单元 mmu 的拓展,通过硬件来实现 GVA,GPA 到 HPA 的转换(对比 aarch64 使用 stage2 mmu 页表映射)。通过查询 EPT 将 GPA 转换为 HPA。EPT 的控制权在 VMM 上,只有 cpu 工作在 non-root 模式时才参与该内存转换。引入 EPT 后,客户机读写 CR3 寄存器或者客户机 page fault,执行 INVLPG 指令等不会触发 vm exit,由此降低了内存转换复杂度,提升转换效率额。
cpu 使用 tlb 缓存虚拟地址到物理地址的映射,地址转换时 cpu 先根据 GPA 查找 tlb,如果未找到映射 HPA,将根据页表映射填充 tlb,再进行地址转换。不过客户机的vcpu切换执行时需要刷新 tlb,影响了内存访问效率。intel 引入 VPID(Virtual-Processor Identifier)技术在硬件上为 tlb 增加一个标志,每个 tlb 表项与一个 VPID 关联,唯一对应一个 vcpu,当 vcpu 切换时可根据 VPID 找到并保留已有的 tlb 表项,减少 tlb 刷新。
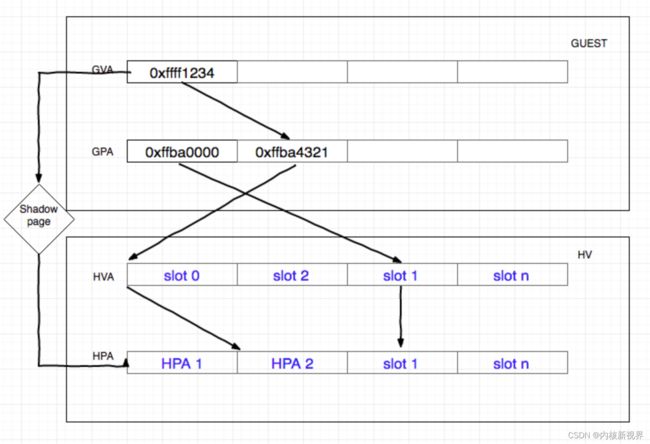
影子页表由 qemu-kvm 进程维护,实际上就是客户机的页表到主机的页表映射,但是维护工作复杂,引入 ept 硬件加速:
EPT 可以看作是个硬件的影子页表,在客户机中通过增加 EPT 寄存器,当客户机产生了 CR3 和页表的访问时,由于对 CR3 中页表地址的访问是 GPA,当地址为空时,产生 page fault,如果在软件维护影子页表时会 vm exit,并处理此异常。但是在 EPT 中,该异常忽略。客户机不会退出,而是按照传统的缺页中断处理,在缺页中断处理中产生 EXIT_REASON_EPT_VIOLATION,客户机退出,qemu-kvm 捕获异常,分配物理地址并建立 GVA -> HPA 映射,保存到 EPT 中,将 EPT 载入 MMU,下次转换时直接根据 CR3 查询 EPT 来完成 GVA -> HPA 的转换。以后的转换由硬件完成,提高效率,且不再需要为每个进程维护一套页表,减少内存开销。
3 x86 kvm 执行流程

首先启动 qemu,通过 ioctl 等系统调用向内核申请指定资源,创建好虚机环境,启动虚机内的 OS,执行 VMLAUCH 指令(vm entry),即进入了客户机代码执行流程。如果客户机发生外部中断或者缺页等事件,暂停客户机执行(vm exit),执行必要处理,重新进入客户机(VMRESUME,vm entry),如果是 IO 请求,则返回 qemu 处理 io。
qemu 通过 ioctl 进入内核模式,在 kvm driver 中获取当前物理 cpu 的引用。之后将客户机状态从 VMCS 中读出,并装入物理 cpu 中。执行 VMLAUCH 指令使得物理处理器进入 non-root 模式,运行客户机代码。当客户机执行一些特权指令或者发生外部事件时,比如 IO 访问,对控制寄存器的操作,MSR 的读写等,都会导致物理 cpu 发生 vm exit,停止运行客户机,将客户机保存到 VMCS 中,主机状态装入物理处理器中,处理器进入 root 模式,kvm 取得控制权,通过读取 VMCS 中 VM_EXIT_REASON 字段得到引起 vm exit 的原因。从而调用 kvm_exit_handler 处理函数。如果由于 IO 获得信号到达,则退出到用户空间的 qemu 处理。处理完毕后,重新进入客户机模式运行客户机代码。
4 x86 vm entry/exit
vm entry 是从 root 模式切换到 non-root 模式,即 VMM 切换到客户机上,这个状态由 VMM 发起,发起之前先保存 VMM 中的关键寄存器内容到 VMCS 中,然后进入 vm entry,vm entry 附带参数主要 3 个:1)客户机是否处于 64 bit 模式;2)msr vm entry 控制;3)注入事件;
1)只在 VMLAUCH 有意义,3)更多是在 VMRESUME,从 VMM 发起 vm entry 更多是因为3),2)主要用来每次更新 msr。
vm exit 是 cpu 从 non-root 模式切换到 root 模式,从客户机切换到 VMM 的操作,vm exit 触发的原因很多,执行敏感或者特权指令,发生中断,模拟特权资源等。
敏感指令有三个方面:
- 行为没有变化的,该指令能够正确执行。
- 行为有变化的,直接产生 vm exit。
- 行为有变化的,但是是否产生 vm exit 受到 vm-execution控制域控制。
5 x86 创建 vm 虚机
(1)创建虚机 KVM_CREATE_VM
kvm_dev_ioctl_create_vm
-> kvm_arch_init_vm(初始化 kvm->arch,更新 kvmclock 函数)
-> hardware_enable_all
struct kvm {
struct mm_struct *mm; /* userspace tied to this vm */
struct kvm_memslots __rcu *memslots[KVM_ADDRESS_SPACE_NUM]; /*qemu模拟的内存条模型*/
struct kvm_vcpu *vcpus[KVM_MAX_VCPUS]; /* 模拟的CPU */
atomic_t online_vcpus;
int last_boosted_vcpu;
struct list_head vm_list; //HOST上VM管理链表,
struct kvm_io_bus *buses[KVM_NR_BUSES];
struct kvm_vm_stat stat;
struct kvm_arch arch; //这个是host的arch的一些参数
atomic_t users_count;
long tlbs_dirty;
struct list_head devices;
};
hardware_enable_all 针对每个 cpu 执行 on_each_cpu(hardware_enable_nolock, NULL, 1);
其中包括 kvm_cpu_vmxon 打开 vmx 操作模式。
(2)创建 vcpu KVM_CREATE_VCPU
kvm_vm_ioctl_create_vcpu
-> kvm_arch_vcpu_create(重点)
-> kvm_arch_vcpu_setup
-> kvm_arch_vcpu_postcreate
struct kvm_vcpu {
struct kvm *kvm;
#ifdef CONFIG_PREEMPT_NOTIFIERS
struct preempt_notifier preempt_notifier;
#endif
struct kvm_run *run; //运行时的状态
struct kvm_vcpu_stat stat; //一些数据
struct kvm_vcpu_arch arch; //当前VCPU虚拟的架构,默认介绍X86
}
(3)运行 vcpu KVM_RUN
kvm_arch_vcpu_ioctl_run
-> vcpu_load
...
-> vcpu_run(for(;;){...})
...
-> vcpu_put
kvm_vmx_exit_handlers(退出原因及对应处理)
static int (*const kvm_vmx_exit_handlers[])(struct kvm_vcpu *vcpu) = {
[EXIT_REASON_EXCEPTION_NMI] = handle_exception,
[EXIT_REASON_EXTERNAL_INTERRUPT] = handle_external_interrupt,
[EXIT_REASON_TRIPLE_FAULT] = handle_triple_fault,
[EXIT_REASON_NMI_WINDOW] = handle_nmi_window,
// 访问了IO设备
[EXIT_REASON_IO_INSTRUCTION] = handle_io,
...
...
完整代码框架图:

static int vcpu_run(struct kvm_vcpu *vcpu)
{
int r;
struct kvm *kvm = vcpu->kvm;
vcpu->srcu_idx = srcu_read_lock(&kvm->srcu);
vcpu->arch.l1tf_flush_l1d = true;
for (;;) {
if (kvm_vcpu_running(vcpu)) {
r = vcpu_enter_guest(vcpu); // 进入客户机模式
} else {
r = vcpu_block(kvm, vcpu);
}
if (r <= 0)
break;
kvm_clear_request(KVM_REQ_UNBLOCK, vcpu);
if (kvm_cpu_has_pending_timer(vcpu)) // 检测是否有挂起的 timer
kvm_inject_pending_timer_irqs(vcpu);
// 检测是否有用户空间的中断注入
if (dm_request_for_irq_injection(vcpu) &&
kvm_vcpu_ready_for_interrupt_injection(vcpu)) {
r = 0;
vcpu->run->exit_reason = KVM_EXIT_IRQ_WINDOW_OPEN;
++vcpu->stat.request_irq_exits;
break;
}
// 是否有阻塞的信号
if (signal_pending(current)) {
r = -EINTR;
vcpu->run->exit_reason = KVM_EXIT_INTR;
++vcpu->stat.signal_exits;
break;
}
// 如果需要重调度,执行一个调度
if (need_resched()) {
srcu_read_unlock(&kvm->srcu, vcpu->srcu_idx);
cond_resched();
vcpu->srcu_idx = srcu_read_lock(&kvm->srcu);
}
}
srcu_read_unlock(&kvm->srcu, vcpu->srcu_idx);
return r;
}
在 vcpu_enter_guest 中进入了客户机,然后一直是 vcpu 运行,当这个函数退出时,说明执行了 vm exit 指令,此时已经退出客户机进入 root 模式了。
退出之后,检查退出原因,如果有时钟中断发生,则插入一个时钟中断,如果是用户空间的中断发生,则退出原因填写 KVM_EXIT_INTR。
对于退出事件的处理,vcpu_enter_guest 中已经处理了一部分,处理的是虚机本身退出的事件。虚机退出就会执行 vmx_handle_exit,比如虚机内部写磁盘 io 导致退出,就在 vcpu_enter_guest 中处理(只是设置了退出的原因为 io,并没有真正执行 io)。kvm 想要知道退出的原因,就需要 vmcs 结构起作用,vmcs 中有一个 vm-exit 信息。退出 vm 后,如果内核没有完成处理,则需要退出到 qemu 中处理。
6. x86 vcpu 调度
qemu 中有:
int kvm_cpu_exec(CPUState *cpu)
{
cpu_exec_start(cpu);
do {
kvm_arch_pre_run(cpu, run);
smp_rmb();
run_ret = kvm_vcpu_ioctl(cpu, KVM_RUN, 0);
attrs = kvm_arch_post_run(cpu, run);
switch (run->exit_reason) {
case KVM_EXIT_IO:
case KVM_EXIT_MMIO:
case KVM_EXIT_IRQ_WINDOW_OPEN:
...
...
} while (ret == 0);
cpu_exec_end(cpu);
qemu_mutex_lock_iothread();
}
static void *qemu_kvm_cpu_thread_fn(void *arg)
{
CPUState *cpu = arg;
int r;
rcu_register_thread();
r = kvm_init_vcpu(cpu);
/* signal CPU creation */
cpu->created = true;
qemu_cond_signal(&qemu_cpu_cond);
qemu_guest_random_seed_thread_part2(cpu->random_seed);
do {
if (cpu_can_run(cpu)) {
r = kvm_cpu_exec(cpu);
if (r == EXCP_DEBUG) {
cpu_handle_guest_debug(cpu);
}
}
qemu_wait_io_event(cpu);
} while (!cpu->unplug || cpu_can_run(cpu));
}
static void qemu_kvm_start_vcpu(CPUState *cpu)
{
char thread_name[VCPU_THREAD_NAME_SIZE];
cpu->thread = g_malloc0(sizeof(QemuThread));
cpu->halt_cond = g_malloc0(sizeof(QemuCond));
qemu_cond_init(cpu->halt_cond);
snprintf(thread_name, VCPU_THREAD_NAME_SIZE, "CPU %d/KVM",
cpu->cpu_index);
qemu_thread_create(cpu->thread, thread_name, qemu_kvm_cpu_thread_fn,
cpu, QEMU_THREAD_JOINABLE);
}
从上面代码可以看到,每个 vcpu 在 qemu 对应一个线程,那么 vcpu 受到内核的调度策略影响。从而自然可以发生 vcpu 被抢占等可能。(服务器没有抢占模型,是否 vcpu 会被另一个 vcpu 抢占?是否有其他路径抢占?)
如何向 vcpu 注入中断?
通过向真实 cpu 模拟注入 nmi 中断来实现。
kvm 通过 KVM_CREATE_IRQCHIP 来创建一个 irqchip 模拟,qemu再通过KVM_IRQ_LINE ioctl 注入中断。
中断注入后,需要 vcpu 立即响应,但是在 smp 下,目标 vpu 还在客户机运行,需要提供机制让目标 vcpu 停止运行,退出 vm 处理中断,此时使用 kvm_vcpu_kick,向目标 vcpu 发送一个 ipi 中断。后续再次进入客户机之前,检查请求阶段 inject_pending_event 检查到中断注入,通过写 vmcs 结构注入中断。
7 x86 虚拟页表初始化
在vcpu初始化的时候,要调用kvm_init_mmu来设置不同的内存虚拟化方式。
void kvm_init_mmu(struct kvm_vcpu *vcpu, bool reset_roots)
{
if (reset_roots) {
uint i;
vcpu->arch.mmu->root_hpa = INVALID_PAGE;
for (i = 0; i < KVM_MMU_NUM_PREV_ROOTS; i++)
vcpu->arch.mmu->prev_roots[i] = KVM_MMU_ROOT_INFO_INVALID;
}
if (mmu_is_nested(vcpu))
init_kvm_nested_mmu(vcpu);
else if (tdp_enabled)
init_kvm_tdp_mmu(vcpu); // 支持 EPT
else
init_kvm_softmmu(vcpu);
}
tdp_page_fault -> gva gpa hva hpa (ept: gva - hpa)