NLP论文阅读记录 - 2021 | RefSum:重构神经总结
文章目录
- 前言
- 0、论文摘要
- 一、Introduction
-
- 1.1目标问题
- 1.2相关的尝试
- 1.3本文贡献
- 二.前提
-
- 堆叠
- 重新排序
- 三.本文方法
-
- 3.1 总结为两阶段学习
-
- 3.1.1 基础系统
- 3.1.2 元系统
- 3.2 重构文本摘要
-
- 3.2.1 重构
- 3.2.2 预训练重构
- 3.2.3 微调重构
- 3.2.4 应用场景
-
- 3.2.4.1 重构为基础学习者
- 3.2.4.2 重构为元学习者
- 四 实验效果
-
- 4.1数据集
- 4.2 对比模型
- 4.3实施细节
- 4.4评估指标
- 4.5 实验结果
-
- 4.5.1 Exp-I:单一系统重排序
- 4.5.2 Exp-II:多系统堆叠汇总级
- 4.5.3 Exp-III:19 个最佳性能系统的概括
- 4.5.4 Exp-IV:在更流行的数据集上的有效性
- 4.6 细粒度分析
- 五 总结
- 思考
前言

RefSum: Refactoring Neural Summarization(2104)
code
paper
0、论文摘要
尽管最近的一些作品显示了不同最先进系统之间潜在的互补性,但很少有作品尝试研究文本摘要中的这个问题。其他领域的研究人员通常会参考重新排序或堆叠技术来解决这个问题。
在这项工作中,我们强调了以前方法的一些局限性,这促使我们提出一个新的框架 Refactor,它提供了文本摘要和摘要组合的统一视图。
在实验上,我们进行了涉及 22 个基础系统、4 个数据集和 3 个不同应用场景的综合评估。
除了 CNN/DailyMail 数据集 (46.18 ROUGE-1) 上的最新结果之外,我们还详细阐述了我们提出的方法如何解决传统方法的局限性,以及 Refactor 模型的有效性揭示了性能洞察改进。
我们的系统可以直接被其他研究人员用作现成的工具,以实现进一步的性能改进。
一、Introduction
1.1目标问题
在神经文本摘要中,系统设计者通常在模型架构(Rush et al., 2015; Kedzie et al., 2018)、解码策略(Paulus et al., 2018)(例如波束搜索)等方面有灵活的选择。结果,即使在相同的数据集上,这些选择的不同选择偏差也会导致不同的系统输出(Kedzie et al., 2018;Hossain et al., 2020)。
1.2相关的尝试
为了结合不同设置下系统输出的互补性,研究人员在两阶段学习方面做了一些初步的努力(Collins and Koo,2005;Huang,2008;González-Rubio et al.,2011;Mizumoto and Matsumoto,2016),
包括(i) 基础阶段:首先在不同的设置下生成不同的输出,
(ii) 元阶段:然后以不同的方式聚合它们,例如使用高级模型组合多个低级模型的堆栈( Ting 和 Witten,1997),或重新排序(Collins 和 Koo,2005),其目的是对一个系统的不同输出进行重新排序。
尽管这些方法各自在不同的场景中发挥作用,但它们都存在以下潜在的局限性:
(i) 临时方法:大多数现有方法都是针对特定场景而设计的。
例如,李等人。 (2015)和纳拉扬等人。 (2018b) 采用重新排序技术来选择通常由一个系统生成的值得总结的句子。相比之下,洪等人。 (2015)侧重于不同系统生成的摘要,并使用非神经系统组合方法,使它们优势互补。很少有研究探讨不同场景中存在的互补性是否可以在一个统一的框架中利用。
(ii) 基础元学习差距:两个学习阶段之间的参数化模型相对独立
例如,周等人。 (2017)和黄等人。 (2020) 采用 seq2seq (Sutskever et al., 2014) 框架作为组合的元模型,它将多个基础系统的输出作为机器翻译输入的一部分。结果,如图1所示,元模型和基础系统之间不存在参数共享,这阻碍了元模型充分利用基础系统中编码的知识。
(iii) 训练-测试分布差距:对于元学习阶段,训练和测试分布之间存在分布差距。
图1阐明了这一现象:Hypo的训练分布与Hypo’的测试分布不同。虽然两者都是基础阶段的输出,但 Hypo 会更准确(更接近黄金摘要),因为它是训练阶段的输出。

1.3本文贡献
在这项工作中,我们的目标是通过提出一个名为 Refactor 的通用框架来解决这些限制,该框架不仅可以作为通过从源文档中选择句子来构建摘要的基础系统,还可以作为元系统来选择最佳句子来自多个候选人的系统输出。
基础系统和元系统的统一使它们能够共享一组参数,从而缩小“基础-元学习差距”。此外,我们为重构提出了一种预训练然后微调的范例,以减轻“训练-测试分布差距”。在实践中,我们提出的Refactor可以应用于不同的场景。例如,作为元系统,它可以用于多个系统组合或单个系统重新排名。
总之,我们的贡献如下:
(1)我们剖析了利用不同系统之间的互补性时影响两阶段学习性能的两个主要因素:(i)基础元学习差距(ii)训练测试分布差距;
(2)我们证明这两种类型的差距可以通过促进第 4 节中两个阶段之间的通信来缓解,因此提出了一种新的范式,其中基础学习器和元学习器使用共享参数进行参数化;
(3)我们做了全面的实验(22个最高分系统,4个数据集)。除了在 CNN/DailyMail 数据集(§5)上大幅取得最先进的结果之外,所提出的 Refactor 的功效还为性能改进开辟了一个发人深省的方向:而不是追求纯粹的最终结果对于最终系统,一个有前途的探索是将不同类型的归纳偏差与相同的参数化函数分阶段合并。
我们的实验结果表明,当前最先进的摘要系统中存在由解码算法(例如波束搜索)§5.5或系统组合§5.6引入的互补性,我们的模型可以有效地利用这些互补性来提高系统性能。
二.前提
现有的工作通常以端到端的方式设计系统(Sutskever 等人,2014 年;Sukhbaatar 等人,2015 年),虽然有效,但在某些情况下也被证明是不够的(Glasmachers,2017 年;Webb 等人) .,2019)。
一种更灵活的范式,即阶段式学习,不是以端到端的方式优化系统,而是将整体过程分解为不同的阶段。基本思想是分阶段合并不同类型的归纳偏差,两个典型的例子是:堆叠和重新排名。
堆叠
堆叠(又名堆叠泛化)是一种使用高级模型组合较低级模型以实现更高预测精度的通用方法(Ting 和 Witten,1997)。在NLP研究中,这种方法在机器翻译(MT)任务中得到了广泛的探索。传统上,它用于提高统计机器翻译系统的性能(González-Rubio et al., 2011;Watanabe and Sumita, 2011;Duh et al., 2011;Mizumoto and Matsumoto, 2016)。最近的一些工作(Zhou et al., 2017; Huang et al., 2020)也将这种方法扩展到神经机器翻译,其中元模型和基础系统都是神经模型。有一些关于摘要系统组合的工作(Hong et al., 2015),其中基于特征的元模型用于组合无监督文本摘要系统。
重新排序
重排序是一种通过对现有系统的输出进行重新排序来提高性能的技术,已广泛应用于不同的 NLP 任务,例如选区解析(Collins and Koo,2005;Huang,2008)、依存解析(Zhou et al., 2016;Do 和 Rehbein,2020)、语义解析(Ge 和 Mooney,2006;Yin 和 Neubig,2019)、机器翻译(Shen 等,2004;Mizumoto 和 Matsumoto,2016)。
比较重排序和堆叠,两者都涉及两阶段学习,第一阶段将提供多个候选输出作为第二阶段的输入。然而,它们的不同之处在于第一阶段如何生成多个候选输出。
具体来说,重新排序通常使用一个基本系统在推理过程中解码 k 个最合格的结果。
相比之下,堆叠会生成通常来自不同基础系统的多个输出。
三.本文方法
3.1 总结为两阶段学习
3.1.1 基础系统
基础阶段的系统旨在根据输入文本生成摘要。
具体来说,给定一个包含 n 个句子的文档 D = {s1, · · ·, sn},我们将 C 称为由摘要系统生成的 D 的候选摘要,它可以以多种形式参数化:

其中 BASE(, θbase) 表示一个基本系统,可以通过特定的实验设置实例化为提取模型或抽象模型:
训练方法 T 、解码策略 S。
3.1.2 元系统
在实践中,参数化函数BASE(·)、训练方法T和解码策略S的不同选择通常会导致不同的候选摘要,C = {C1,···,Ck},其中C表示一组不同的候选摘要。
元系统的目标是通过流行技术(例如重新排序和系统组合)来利用 C 之间的互补性。
具体来说,给定一组候选摘要 C,使用元系统重新构建新的候选摘要 C*
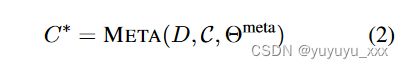
其中 θmeta 表示元系统的可学习参数。
3.2 重构文本摘要
尽管现有元系统有效,但正如第 1 节中简要提到的,
它们面临两个主要问题:(i) 基础元学习差距和 (ii) 训练测试分布差距。
3.2.1 重构
在本文中,我们提出了模型重构,该模型通过选择文档句子的最佳组合来生成摘要的观点统一了基础系统和元系统的目标。因此,基础系统和元系统都旨在选择最佳候选摘要,它们仅在候选摘要集的构建方式上有所不同。例如,当候选摘要集C是通过直接枚举文档句子的不同组合形成时,Refactor可以是一个基础系统;当C代表来自不同系统的摘要时,Refactor可以是一个元系统。
这个公式有两点优点:
(1) 无论系统选择何处(从文档句子或多个系统输出),所选择的定义良好摘要的标准都是共享的。因此,基础系统和元系统的学习过程可以使用一组参数进行参数化,最大化两个阶段的信息共享并缩小基础-元学习差距。
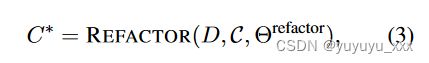
其中 REFACTOR(·, θrefactor) 是 Refactor 模型,候选摘要 C 可以通过不同的方式构建。
(2) 此外,学习从文档句子中选择候选摘要使系统能够看到具有不同分布的更多样化的候选摘要。这对于解决训练-测试分布差距是有效的,其中训练样本中元系统输出的分布偏离测试样本。
具体来说,我们提出的 Refactor 首先学习从文档句子中选择候选摘要(预训练的 Refactor),然后学习从不同的系统输出中选择候选摘要(微调的 Refactor)。
3.2.2 预训练重构
预训练的 Refactor 将文档 D = {s1, · · · , sn} 以及一组候选摘要 C = {C1, · · · , Cm} 作为输入,可以通过枚举源的可能组合来构造具有启发式修剪的句子。
例如,提取系统可用于修剪不太可能的句子以控制候选者的数量。 REFACTOR(·, θrefactor) 被实例化为评分函数,量化候选摘要 Ci 与源的匹配程度文件D。

其中 D 和 Ci 分别表示文档和摘要表示,由 BERT (Devlin et al., 2019) 模型计算。 SCORE(·) 是衡量文档和候选摘要之间相似度的函数。
情境相似度函数
为了实例化 SCORE(·),我们遵循Zhang 等人中提到的形式。 (2019b);赵等人。 (2019);高等人。 (2020),在测量文档和摘要之间的语义相似性方面表现出了卓越的性能。
具体来说,SCORE(·)是基于贪婪匹配算法定义的,该算法将一个文本序列中的每个单词与另一文本序列中最相似的单词进行匹配,反之亦然。给定由 BERT 编码的文档嵌入矩阵 D = 〈d1, · · · , dk〉 和候选嵌入矩阵 C = 〈c1, · · · , cl〉,SCORE(·) 可以计算为:
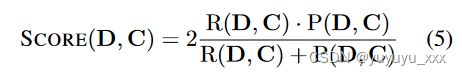
其中加权召回率R、精度P定义如下:
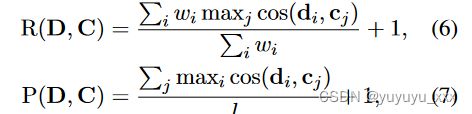
wi 是文档中第 i 个标记的权重。我们使用加权召回率 R 的假设是,对于文本摘要,源文档中的标记具有不同的重要性,并且摘要应该捕获源文档中最重要的信息。因此,我们引入了一个由双层 Transformer 构建的加权模块(Vaswani et al., 2017),分配权重 wi:
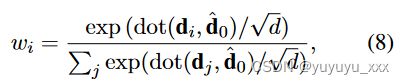
其中 ˆ D = Transformer(D) 和 ˆ d0 = ˆ D[0] 表示对全局信息进行编码的“[CLS]”标记的嵌入。 d 是 di 的维度。
学习目标
我们使用排名损失来学习参数 θrefactor,其灵感来自于一个假设(Zhong et al., 2020),即一个好的候选摘要应该尽可能接近源文档。正式地,
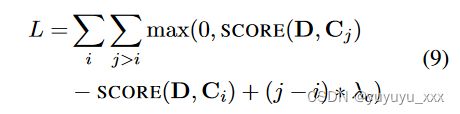
其中 Ci 和 Cj 表示候选列表中的第 i 个和第 j 个样本,该样本按参考摘要 ^ C 和候选之间的 ROUGE (Lin, 2004) 分数降序排序。即,对于 i < j,ROUGE(Ci, ˆ C) > ROUGE(Cj, ˆ C)。 λc 是设置为 0.01 的相应裕度。
3.2.3 微调重构
为了适应特定类型输入的分布,我们然后使用基本系统生成的输出来微调重构。具体来说,微调也是基于Eq.如图9所示,其中候选摘要C是由基础系统在不同应用场景下生成的。
为什么预训练和微调很重要?
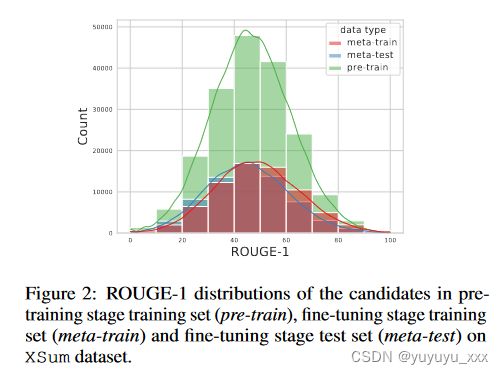
我们使用真实案例详细阐述了所提出的两步训练。图 2 描绘了 XSum 数据集上的预训练阶段训练集、微调阶段训练集和测试集中候选摘要的 ROUGE-1 分数分布,其中我们对相同数量的{文档,候选摘要}对进行采样。我们可以观察到:
(i) 在微调阶段,训练样本和测试样本之间存在分布差距。
(ii) 在预训练阶段,预训练的 Refactor 已经看到了大量具有不同性能的候选摘要mance(ROUGE值),提高了泛化能力。
在第 5 节中,我们将展示预训练和微调范式优于一步训练,其中模型是使用基础系统生成的数据直接训练的。
3.2.4 应用场景
我们的Refactor可以在不同的场景中充当不同的角色,如下所示。
3.2.4.1 重构为基础学习者
预先训练的Refactor不仅可以为更好地选择候选摘要而进行微调,而且还可以被视为一个基本系统,提供一个系统输出。Refactor的这个特性最大化了两个训练阶段之间的参数共享。
3.2.4.2 重构为元学习者
当我们有多个系统摘要时,预训练的 Refactor 和微调的 Refactor 都可以用作元系统来选择最佳候选者。
在这项工作中,我们探索以下设置:
(1)单一系统:它考虑使用波束搜索对从单一抽象系统生成的候选摘要进行重新排序。
(2)多系统摘要级别:其任务是从不同系统的结果中选择最佳候选摘要。
(3)多系统句子级:我们还朝着提取和抽象系统摘要的细粒度融合迈出了一步。
具体来说,这里的候选摘要是通过在句子级别结合不同系统的结果来生成的。
四 实验效果
4.1数据集
我们主要在四个数据集上进行实验,其统计数据如表 1 所示。
- CNNDM2(Hermann et al., 2015)是一个广泛使用的数据集,包含新闻文章和用作参考摘要的相关亮点。我们关注 Nallapati 等人的工作。 (2016)用于数据预处理。
XSum3(Narayan 等人,2018a)包含从 BBC 收集的在线文章,其中包含高度抽象的一句话摘要。
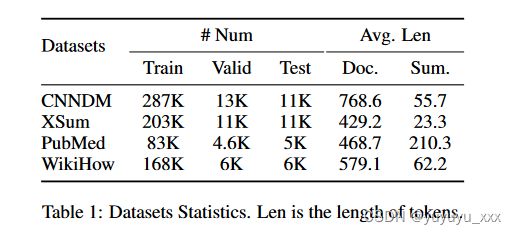
PubMed4(Cohan 等人,2018)包含从 PubMed.com 收集的科学论文。
WikiHow5(Koupaee 和 Wang,2018)是使用在线 WikiHow 知识库根据文章构建的大型数据集。
4.2 对比模型
下面,我们主要使用 BART、GSum 和 PEGASUS 作为基础系统,因为它们在至少一个数据集上实现了最先进的性能。
BART(Lewis et al., 2020)是一种大型预训练序列到序列模型,在抽象摘要方面实现了强大的性能。
GSum (Dou et al., 2020) 使用额外的指导信息增强了 BART 的性能,从而在 CNNDM 数据集上实现了当前最先进的性能。
PEGASUS(Zhang 等人,2020)在各种汇总数据集上实现了具有竞争力的性能,并且是 XSum 数据集上当前最先进的。
为了对我们提出的模型进行全面评估,我们另外收集了 19 个得分最高的系统作为 CNNDM 上的基础系统。6 具体而言,对于第 5.7 节,我们使用以下系统:指针生成器+覆盖率(参见 et al., 2017) 、REFRESH(Narayan 等人,2018b)、fastAbsRL-rank(Chen 和 Bansal,2018)、CNN-LSTM-BiClassifier(Kedzie 等人,2018)、CNN-Transformer-BiClassifier(Zhong 等人,2019)、 CNN-Transformer-Pointer (Zhong et al., 2019)、BERT-Transformer-Pointer (Zhong et al., 2019)、Bottom-Up (Gehrmann et al., 2018)、NeuSum (Zhou et al., 2018)、 BanditSum (Dong et al., 2018)、twoStageRL (Zhang et al., 2019a)、preSummAbs (Liu and Lapata, 2019)、preSummAbsext (Liu and Lapata, 2019)、HeterGraph (Wang et al., 2020)、MatchSum (钟等人,2020),
Unilm-v1(Dong 等人,2019)、Unilm-v2(Dong 等人,2019)、T5(Raffel 等人,2020)。
神经系统组合器:我们使用 BERTScore(Zhang 等人,2019b)作为神经模型的无监督基线,这是一种基于相应的 BERT 编码表示计算文本对相似度的自动评估指标。我们用它来直接计算源文档和候选摘要之间的相似度得分。
非神经系统组合器:我们使用 RankSVM7(Joachims,2002)作为非神经基线。我们对开发集进行交叉验证以进行超参数搜索,并在开发集上训练模型。附录 A 中列出了这组功能。 预言机:我们使用 ROUGE 将我们的模型与样本最小、最大和随机预言机进行比较。
4.3实施细节
对于 CNNDM 的第 5.5、第 5.6 和第 5.7 节中的以下实验,我们使用通过枚举源文档中句子组合生成的候选集来预训练 Refactor 模型。
为了减少候选者的数量,我们遵循Zhong等人的观点,通过提取模型BERTSum(Liu和Lapata,2019)修剪分配较低分数的句子。 (2020)。一个数据样本的最大候选数为 20。
预训练的重构也被用作第 5.6 节中的基础系统,其输出与其他基础系统一起用作候选摘要。
对于不同的实验,我们在基础系统的输出上微调预训练的 Refactor,并将该模型命名为fine-tuned Refactor。
为了分析所提出的两阶段训练的有效性,我们在没有预训练步骤的情况下额外训练模型,这被称为监督重构。
我们使用的预训练 BERT 模型来自 Transformers 库(Wolf 等人,2020)。8 我们使用 Adam 优化器(Kingma 和 Ba,2015)进行学习率调度。

其中warmup_steps为10000。验证集上的模型性能用于选择检查点。在 4 个 GTX-1080-Ti GPU 上进行预训练大约需要 40 小时,而微调大约需要 20 小时。
4.4评估指标
4.5 实验结果
4.5.1 Exp-I:单一系统重排序

我们使用 BART 和 GSum 进行此实验,并使用波束搜索来生成候选摘要,其中波束大小设置为 4。
结果列于表中。如图 2 所示,
它表明(1)Refactor 可以显着提高基础系统的性能,
(2)微调的 Refactor 优于直接在基础系统输出上训练的有监督的 Refactor,显示了两步训练的有效性。值得注意的是,我们观察到微调的 Refactor 可以将 BART 在 ROUGE-1 上的性能从 44.26 提高到 45.15,
这表明波束搜索选择的 top-1 输出并不总是最好的,并且 Refactor 可以有效地利用通过考虑引入的互补性所有波束搜索结果。
4.5.2 Exp-II:多系统堆叠汇总级
摘要级别 对于摘要级别组合,我们探索了两系统组合(BART 和预训练的 Refactor)和三系统组合(BART、GSum 和预训练的 Refactor)。结果如表所示。 3.

句子级 对于句子级组合,我们使用 BART 和预训练的 Refactor 作为基础系统。将每个系统输出的句子合并在一起形成候选句子集,并将候选集中三个句子的所有组合生成为候选摘要。
为了修剪候选者,我们使用三元组阻塞来过滤掉两个句子中存在相同三元组的候选者。测试集中候选者的平均数量为 15.8。结果如表所示。 4.

我们有以下观察结果:
(1)预训练的 Refactor 已经可以超越基础系统,
(2)微调可以进一步提高的表现。
同时,我们注意到有两个例外:
(i)对于句子级组合,监督重构与微调重构具有相似的性能。我们假设这是因为这里微调数据中的候选数量相对较多,因此直接对微调数据进行训练就足够了。
(ii) 在表 3 中的三系统组合设置中,预训练的 Refactor 无法优于 GSum 模型。 3. 原因可能是GSum比其他两个系统具有更强的性能,这直观地使得系统组合的预期增益低于其他设置。
4.5.3 Exp-III:19 个最佳性能系统的概括
为了评估 Refactor 的泛化能力,我们探索了另一种设置,即直接使用预训练的 Refactor 来选择多个系统的输出,而无需进行微调。
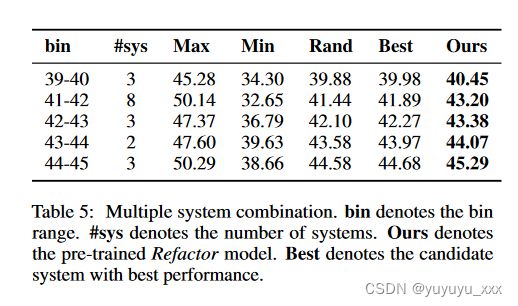
为此,我们在 CNNDM 数据集上收集了 19 个表现最好的摘要系统。在这里,我们研究我们的重构是否可以提高具有相似性能的候选系统的性能。此外,我们还旨在研究不同系统性能的范围宽度如何影响 Refactor 的性能。因此,我们根据候选系统的平均 ROUGE-1 分数将其分为等宽的 bin,并分别评估每个 bin 上的重构。
在选项卡中。在图 5 中,我们报告了每个宽度为 1 的 bin 中预言机、Refactor 和最佳候选系统的平均 ROUGE-1 分数。Refactor 始终优于最佳候选系统,显示了其泛化能力。
接下来,在图 3 中,我们绘制了不同 bin 宽度下 Refactor 性能的变化。我们将给定 bin 宽度的 Refactor 的成功率定义为 bin 的数量,其中 Refactor 优于按 bin 总数归一化的单个最佳基本系统。我们观察到重构
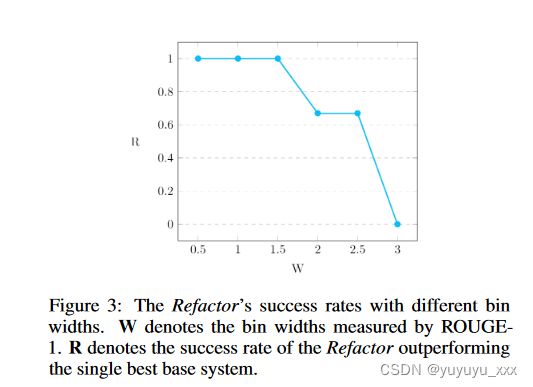
当基础系统的系统级性能相似时,更有可能提高基础系统的性能。直观上,如果一个基础系统明显优于其他系统,那么 Refactor 就更难以使用其他系统来补充最好的基础系统。
4.5.4 Exp-IV:在更流行的数据集上的有效性
接下来,我们继续使用其他文本摘要数据集来评估我们提出的方法在 CNNDM 数据集之外的优势。这里使用的一些数据集没有像 CNNDM 数据集那样得到充分研究,因此在这些数据集上表现最好的系统较少。因此,这里我们重点进行单系统设置的实验。
设置 关于预训练的重构,我们使用提取预言机来选择文档句子并使用这些句子的组合作为候选。此外,由于在 Xsum 上抽象系统的性能大大优于提取系统,因此我们使用预先训练的 BART模型与 Diverse Beam Search(Vijayakumar 等人,2018)为每个样本生成 16 个候选者进行预训练。关于系统重新排名,我们使用 BART 作为基础系统来生成候选摘要,但 Xsum 数据集除外,我们使用 PEGASUS,因为它可以实现更好的性能。与§5.5类似,我们使用集束搜索的输出作为候选。我们选择前 4 个输出作为候选。
结果如表所示。图 6 表明 Refactor 能够对基础系统带来稳定的改进。这些数据集的平均摘要长度从 23.3 (XSum) 到 210.3 (Pubmed) 不等。因此,这里的结果表明重构可以应用于具有不同特征的数据集。在 XSum 数据集上,预训练的 Refactor 优于微调的 Refactor。这可能是由于我们使用 BART 引入的额外预训练数据所致,该数据足以有效地训练 Refactor 以重新排列 PEGASUS 输出。
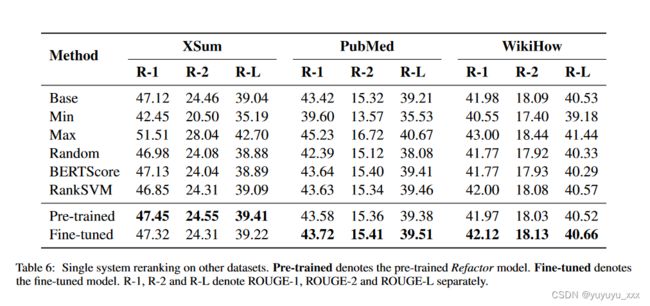
模型与 Diverse Beam Search(Vijayakumar 等人,2018)为每个样本生成 16 个候选者进行预训练。关于系统重新排名,我们使用 BART 作为基础系统来生成候选摘要,但 Xsum 数据集除外,我们使用 PEGASUS,因为它可以实现更好的性能。与§5.5类似,我们使用集束搜索的输出作为候选。我们选择前 4 个输出作为候选。
结果如表所示。图 6 表明 Refactor 能够对基础系统带来稳定的改进。这些数据集的平均摘要长度从 23.3 (XSum) 到 210.3 (Pubmed) 不等。因此,这里的结果表明重构可以应用于具有不同特征的数据集。在 XSum 数据集上,预训练的 Refactor 优于微调的 Refactor。这可能是由于我们使用 BART 引入的额外预训练数据所致,该数据足以有效地训练 Refactor 以重新排列 PEGASUS 输出。
4.6 细粒度分析
我们对 Refactor 进行了细粒度的评估,以了解改进主要来自哪里。
设置
我们选择第 5.6 节中 CNNDM 测试集的摘要级系统组合设置作为案例研究,其中基础系统是:BART 和预训练的 Refactor,然后我们使用微调的 Refactor9 将它们组合起来。
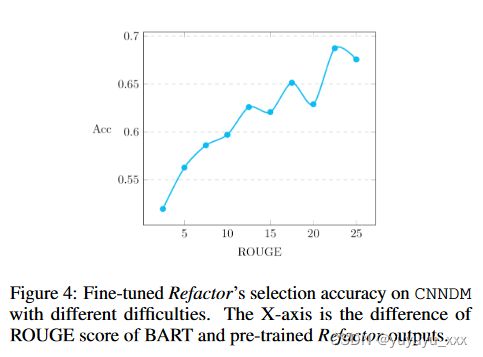
具体来说,
我们首先 (i) 将 δ(CBART, CPretrain) 定义为候选摘要 C 上的性能(即 ROUGE)差距。
(ii) 然后根据性能将测试样本划分到不同的桶 S1,…,Sn 中间隙δ。
(iii) 计算每个桶的选择准确度,这表示重构能够从两个候选摘要中识别出最佳摘要的准确程度。
结果如图4所示。我们观察到,随着差距δ变大,选择精度不断提高,这表明Refactor在具有不同性能的候选摘要上表现更好。结合第 5.7 节中得到的结果,我们得出结论,当基础系统有效互补时,Refactor 具有最大的潜在收益——它们具有相似的系统级性能,但摘要级性能不同。例如,每个基础系统在具有不同特征的数据子集上的性能可能明显优于其他系统,但在整个数据集中无法优于其他系统。
五 总结
我们通过将文本摘要制定为两阶段学习问题,提出了利用现代文本摘要系统的互补性的总体框架。
我们提出的模型 Refactor 可以用作基础系统或元系统,有效地缓解两阶段学习中引入的学习差距。实验结果表明,Refactor 能够提升基础系统的性能,并在 CNNDM 和 XSum 数据集上实现了最先进的性能。
我们相信这项工作为提高文本摘要系统的性能开辟了一个新的方向,除了搜索更好的模型架构的迭代过程之外——性能的提升可以通过充分研究和利用具有不同架构的不同系统的互补性来实现,问题表述、解码策略等
思考
不提供数据,第一阶段需要自己弄,4个摘要{“article”: str, “summary”: str, “candidates”: [str]}格式如下
第二阶段 模型根据相似度选择最相似的摘要,同时学习一个排序损失来让模型学习不同摘要之间的区别。
学习选择摘要来匹配参考摘要,但是没有对不同摘要进行一个排序
具体来说,我们提出的重构首先学习从文档句子中选择候选摘要(预训练重构),然后学习从不同的系统输出中选择候选摘要(微调重构)。
出发点:1.利用具有互补性的不同系统,联合成一个更强的系统。
2.提升已有的单个模型的性能。