Neural Tangent Kernel 理解(一)原论文解读
- 欢迎关注WX公众号,每周发布论文解析:PaperShare,
点我关注
NTK的理解系列 暂定会从(一)论文解读,(二)kernel method基础知识,(三)神经网络表达能力,(四)GNN表达能力 等方面去写。当然,可能有的部分会被拆开为多个小部分来写,毕竟每一个点拿出来都可以写本书了。
(本人各个系列旨在让复杂概念通俗易懂,力求获得进一步理解)
Neural Tangent Kernel (NTK) 理论由 [1] 提出,后续有很多跟进的研究工作,比如和我自己领域比较相关的,Simon Du老师提出的Graph neural tangent kernel [2].
NTK在深度学习理论中是很有意思的,通过学习该理论和相关论文,我们能够得到许多启发,所以我准备通过记录自己学习NTK的过程来巩固和分享一些自己的理解。由于本文主要是以自己的视角来看,难免有疏漏,错误和偏见。
我们按照论文的顺序来叙述。
(一) Neural Tangent Kernel 目的
Abstract第一句话:

无限宽的ANN初始化等价于高斯过程,所以可以和Kernel method联系起来。然后作者证明了,训练过程,也可以用一个kernel method来描述,并且能够通过kernel gradient descent来训练,这个kernel就是NTK。
论文目的总结起来就是:
- 理论证明了可以 用NTK来描述ANN训练过程。
- 理论证明了可以 用Kernel gradient descent in funcion space来训练ANN。
- 理论证明了收敛性.
- 理论证明了当数据服从某些特性时,NTK是p.d.的。
- 用least-squares regression举了一个例子。
- 实验结果体现了NTK的一些理论分析。
(二) Neural Tangent Kernel 预备知识
为了方便描述,首先引入一些数学符号和公式定义。
1. 定义一个有 L 层的ANN:
F ( L ) : R P → F F^{(L)}: \mathbb{R}^P \rightarrow \mathcal{F} F(L):RP→F
即,将维度为P的参数 θ \theta θ映射到一个属于函数域 F \mathcal F F的函数 f θ f_{\theta} fθ。 f θ f_{\theta} fθ即:参数为 θ \theta θ的ANN。这里 P = ∑ l = 0 L − 1 ( n l + 1 ) ( n l + 1 ) P=\sum_{l=0}^{L-1}(n_l+1)(n_{l+1}) P=∑l=0L−1(nl+1)(nl+1), n l n_l nl为第 l l l层的输入维度。
2. 定义每一层NN:
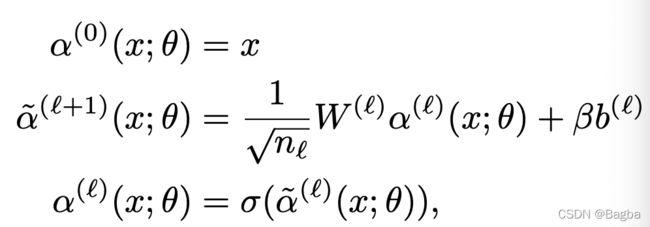
3. Kernel gradient.
要理解这部分内容,需要像泛函分析等的数学基础知识。这里,我用类比简单概念来帮助理解。比如,首先我们将 f θ f_{\theta} fθ想象成一个变量,这个变量的值域是 F \mathcal F F,目标是找到一个optimal的 f θ f_{\theta} fθ,使得cost最小。
3.1 定义cost: C : F → R C: \mathcal F \rightarrow \mathbb{R} C:F→R。
3.2 定义 multi-dimensional kernel K: R n 0 × R n 0 → R n L × R n L \mathbb{R}^{n_0} \times \mathbb{R}^{n_0} \rightarrow \mathbb{R}^{n_L} \times \mathbb{R}^{n_L} Rn0×Rn0→RnL×RnL, 且, K ( x , x ′ ) = K ( x ′ , x ) K(x, x')=K(x', x) K(x,x′)=K(x′,x).
3.3 定义 bilinear map on F \mathcal F F 或叫seminorm ∣ ∣ ⋅ ∣ ∣ p i n ||\cdot||_{p^{in}} ∣∣⋅∣∣pin:
⟨ f , g ⟩ p i n : = E x ∼ p i n [ f ( x ) T g ( x ′ ) ] . \langle f,g \rangle_{p^{in}} := \mathbb{E}_{x \sim p^{in}}[f(x)^Tg(x')]. ⟨f,g⟩pin:=Ex∼pin[f(x)Tg(x′)].
3.4 定义基于kernel K的 bilinear map on F \mathcal F F:
⟨ f , g ⟩ K : = E x , x ′ ∼ p i n [ f ( x ) T K ( x , x ′ ) g ( x ′ ) ] . \langle f,g \rangle_K := \mathbb{E}_{x,x' \sim p^{in}}[f(x)^TK(x, x')g(x')]. ⟨f,g⟩K:=Ex,x′∼pin[f(x)TK(x,x′)g(x′)].
即,求一个在输入概率分布 p i n p^{in} pin下的基于kernel的线性变换下的期望。
3.5 定义 F \mathcal F F的对偶 F ∗ \mathcal F^* F∗: μ : F → R \mu: \mathcal F \rightarrow \mathbb R μ:F→R, where μ = ⟨ d , ⋅ ⟩ p i n \mu = \langle d, \cdot \rangle_{p^{in}} μ=⟨d,⋅⟩pin, d ∈ F d \in \mathcal F d∈F. 这里可以把 μ \mu μ当成一个输入为 f f f的函数,或者是一个线性变换。
3.6 定义一个map Φ K \Phi_K ΦK: F ∗ → F \mathcal F^* \rightarrow \mathcal F F∗→F, 利用kernel的性质: K i , ⋅ ( x , ⋅ ) ∈ F K_{i,\cdot}(x, \cdot) \in F Ki,⋅(x,⋅)∈F, 则可以利用 Φ K \Phi_K ΦK将 μ \mu μ映射为 f f f: f μ = Φ K ( μ ) f_{\mu}=\Phi_K(\mu) fμ=ΦK(μ),对于每一个 i i i, 有: f μ , i ( x ) = μ K i , ⋅ ( x , ⋅ ) = ⟨ d , K i , ⋅ ( x , ⋅ ) ⟩ p i n f_{\mu,i}(x) = \mu K_{i,\cdot}(x, \cdot)=\langle d, K_{i,\cdot}(x, \cdot) \rangle_{p^{in}} fμ,i(x)=μKi,⋅(x,⋅)=⟨d,Ki,⋅(x,⋅)⟩pin
3.6 定义cost function C C C关于 f f f的泛函导数(functional derivative)。给定数据集 x 1 , . . . , x n x_1,...,x_n x1,...,xn, 那么在点 f 0 ∈ F f_0 \in F f0∈F处的导数 ∂ f i n C ∣ f 0 = ⟨ d ∣ f 0 , ⋅ ⟩ \partial^{in}_{f} C|_{f_0}=\langle d|_{f_0}, \cdot \rangle ∂finC∣f0=⟨d∣f0,⋅⟩, 这里 d ∣ f 0 ∈ F d|_{f_0} \in F d∣f0∈F.
3.7 定义kernel gradient : ∇ K C ∣ f 0 ∈ F = Φ K ( ∂ f i n C ∣ f 0 ) \nabla_KC|_{f_0} \in F=\Phi_K\left( \partial^{in}_fC|_{f_0} \right) ∇KC∣f0∈F=ΦK(∂finC∣f0). 这里可以把 x x x的范围从数据集1-n扩展到任意 x x x:

那么, f ( t ) f(t) f(t) 就可以进行kernel gradient descent,只要满足:
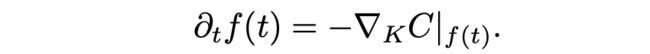
对cost function的进行梯度更新的梯度:

这里,可以保证收敛,因为kernel K K K是p.d.的,只要C是convex,且bounded,则当 t → ∞ t \rightarrow \infty t→∞ 时, f ( t ) f(t) f(t)就可以收敛到全局最优。
明天继续。。。。码我自己的论文去了。。
[1] Jacot, Arthur, Franck Gabriel, and Clément Hongler. “Neural tangent kernel: Convergence and generalization in neural networks.” arXiv preprint arXiv:1806.07572 (2018).
[2] Du, Simon S., et al. “Graph neural tangent kernel: Fusing graph neural networks with graph kernels.” Advances in Neural Information Processing Systems 32 (2019): 5723-5733.