G3周:CGAN入门:生成手势图像
- 本文为365天深度学习训练营 中的学习记录博客
- 原作者:K同学啊|接辅导、项目定制
Z. 心得感受+知识点补充
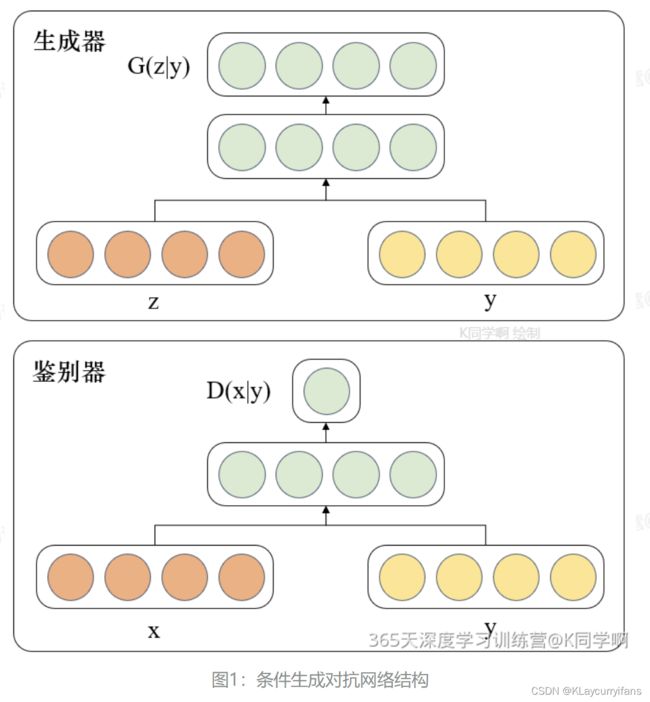
- 条件生成对抗网络(CGAN)是在生成对抗网络(GAN)的基础上进行了一些改进。
- 原始GAN的生成器所生成的图像数据是随机不可预测的,无法控制网络的输出,可控性不强
- 在此基础上,通过对给原始GAN网络中的生成器G和判别器D增加额外条件,本质就是将额外添加的信息融入到生成器和判别器中,其中添加的信息可以是图像的类别、人脸表情和其他辅助信息等,旨在把无监督的GAN转化成有监督学习的CGAN。CGAN网络结构如下图所示:
一、准备工作
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
from torchvision.utils import save_image
from torchvision.utils import make_grid
from torch.utils.tensorboard import SummaryWriter
from torchsummary import summary
import matplotlib.pyplot as plt
import datetime
torch.manual_seed(1)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
batch_size = 128
1. 导入数据
train_transform = transforms.Compose([
transforms.Resize(128),
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5])])
train_dataset = datasets.ImageFolder(root='./data/rps/', transform=train_transform)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=6)
2. 数据可视化
def show_images(images):
fig, ax = plt.subplots(figsize=(20, 20))
ax.set_xticks([]); ax.set_yticks([])
ax.imshow(make_grid(images.detach(), nrow=22).permute(1, 2, 0))
def show_batch(dl):
for images, _ in dl:
show_images(images)
break
show_batch(train_loader)

image_shape = (3, 128, 128)
image_dim = int(np.prod(image_shape))
latent_dim = 100
n_classes = 3
embedding_dim = 100
二、构建模型
# 自定义权重初始化函数,用于初始化生成器和判别器的权重
def weights_init(m):
# 获取当前层的类名
classname = m.__class__.__name__
# 如果当前层是卷积层(类名中包含 'Conv' )
if classname.find('Conv') != -1:
# 使用正态分布随机初始化权重,均值为0,标准差为0.02
torch.nn.init.normal_(m.weight, 0.0, 0.02)
# 如果当前层是批归一化层(类名中包含 'BatchNorm' )
elif classname.find('BatchNorm') != -1:
# 使用正态分布随机初始化权重,均值为1,标准差为0.02
torch.nn.init.normal_(m.weight, 1.0, 0.02)
# 将偏置项初始化为全零
torch.nn.init.zeros_(m.bias)
1. 构建生成器
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
# 定义条件标签的生成器部分,用于将标签映射到嵌入空间中
# n_classes:条件标签的总数
# embedding_dim:嵌入空间的维度
self.label_conditioned_generator = nn.Sequential(
nn.Embedding(n_classes, embedding_dim), # 使用Embedding层将条件标签映射为稠密向量
nn.Linear(embedding_dim, 16) # 使用线性层将稠密向量转换为更高维度
)
# 定义潜在向量的生成器部分,用于将噪声向量映射到图像空间中
# latent_dim:潜在向量的维度
self.latent = nn.Sequential(
nn.Linear(latent_dim, 4*4*512), # 使用线性层将潜在向量转换为更高维度
nn.LeakyReLU(0.2, inplace=True) # 使用LeakyReLU激活函数进行非线性映射
)
# 定义生成器的主要结构,将条件标签和潜在向量合并成生成的图像
self.model = nn.Sequential(
# 反卷积层1:将合并后的向量映射为64x8x8的特征图
nn.ConvTranspose2d(513, 64*8, 4, 2, 1, bias=False),
nn.BatchNorm2d(64*8, momentum=0.1, eps=0.8), # 批标准化
nn.ReLU(True), # ReLU激活函数
# 反卷积层2:将64x8x8的特征图映射为64x4x4的特征图
nn.ConvTranspose2d(64*8, 64*4, 4, 2, 1, bias=False),
nn.BatchNorm2d(64*4, momentum=0.1, eps=0.8),
nn.ReLU(True),
# 反卷积层3:将64x4x4的特征图映射为64x2x2的特征图
nn.ConvTranspose2d(64*4, 64*2, 4, 2, 1, bias=False),
nn.BatchNorm2d(64*2, momentum=0.1, eps=0.8),
nn.ReLU(True),
# 反卷积层4:将64x2x2的特征图映射为64x1x1的特征图
nn.ConvTranspose2d(64*2, 64*1, 4, 2, 1, bias=False),
nn.BatchNorm2d(64*1, momentum=0.1, eps=0.8),
nn.ReLU(True),
# 反卷积层5:将64x1x1的特征图映射为3x64x64的RGB图像
nn.ConvTranspose2d(64*1, 3, 4, 2, 1, bias=False),
nn.Tanh() # 使用Tanh激活函数将生成的图像像素值映射到[-1, 1]范围内
)
def forward(self, inputs):
noise_vector, label = inputs
# 通过条件标签生成器将标签映射为嵌入向量
label_output = self.label_conditioned_generator(label)
# 将嵌入向量的形状变为(batch_size, 1, 4, 4),以便与潜在向量进行合并
label_output = label_output.view(-1, 1, 4, 4)
# 通过潜在向量生成器将噪声向量映射为潜在向量
latent_output = self.latent(noise_vector)
# 将潜在向量的形状变为(batch_size, 512, 4, 4),以便与条件标签进行合并
latent_output = latent_output.view(-1, 512, 4, 4)
# 将条件标签和潜在向量在通道维度上进行合并,得到合并后的特征图
concat = torch.cat((latent_output, label_output), dim=1)
# 通过生成器的主要结构将合并后的特征图生成为RGB图像
image = self.model(concat)
return image
generator = Generator().to(device)
generator.apply(weights_init)
print(generator)
Generator(
(label_conditioned_generator): Sequential(
(0): Embedding(3, 100)
(1): Linear(in_features=100, out_features=16, bias=True)
)
(latent): Sequential(
(0): Linear(in_features=100, out_features=8192, bias=True)
(1): LeakyReLU(negative_slope=0.2, inplace=True)
)
(model): Sequential(
(0): ConvTranspose2d(513, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=0.8, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): ConvTranspose2d(512, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=0.8, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): ConvTranspose2d(256, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(7): BatchNorm2d(128, eps=0.8, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
(9): ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(10): BatchNorm2d(64, eps=0.8, momentum=0.1, affine=True, track_running_stats=True)
(11): ReLU(inplace=True)
(12): ConvTranspose2d(64, 3, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(13): Tanh()
)
)
from torchinfo import summary
summary(generator)
=================================================================
Layer (type:depth-idx) Param #
Generator –
├─Sequential: 1-1 –
│ └─Embedding: 2-1 300
│ └─Linear: 2-2 1,616
├─Sequential: 1-2 –
│ └─Linear: 2-3 827,392
│ └─LeakyReLU: 2-4 –
├─Sequential: 1-3 –
│ └─ConvTranspose2d: 2-5 4,202,496
│ └─BatchNorm2d: 2-6 1,024
│ └─ReLU: 2-7 –
│ └─ConvTranspose2d: 2-8 2,097,152
│ └─BatchNorm2d: 2-9 512
│ └─ReLU: 2-10 –
│ └─ConvTranspose2d: 2-11 524,288
│ └─BatchNorm2d: 2-12 256
│ └─ReLU: 2-13 –
│ └─ConvTranspose2d: 2-14 131,072
│ └─BatchNorm2d: 2-15 128
│ └─ReLU: 2-16 –
│ └─ConvTranspose2d: 2-17 3,072
│ └─Tanh: 2-18 –
Total params: 7,789,308
Trainable params: 7,789,308
Non-trainable params: 0
a = torch.ones(100)
b = torch.ones(1)
b = b.long()
a = a.to(device)
b = b.to(device)
2. 构建鉴别器
import torch
import torch.nn as nn
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
# 定义一个条件标签的嵌入层,用于将类别标签转换为特征向量
self.label_condition_disc = nn.Sequential(
nn.Embedding(n_classes, embedding_dim), # 嵌入层将类别标签编码为固定长度的向量
nn.Linear(embedding_dim, 3*128*128) # 线性层将嵌入的向量转换为与图像尺寸相匹配的特征张量
)
# 定义主要的鉴别器模型
self.model = nn.Sequential(
nn.Conv2d(6, 64, 4, 2, 1, bias=False), # 输入通道为6(包含图像和标签的通道数),输出通道为64,4x4的卷积核,步长为2,padding为1
nn.LeakyReLU(0.2, inplace=True), # LeakyReLU激活函数,带有负斜率,增加模型对输入中的负值的感知能力
nn.Conv2d(64, 64*2, 4, 3, 2, bias=False), # 输入通道为64,输出通道为64*2,4x4的卷积核,步长为3,padding为2
nn.BatchNorm2d(64*2, momentum=0.1, eps=0.8), # 批量归一化层,有利于训练稳定性和收敛速度
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64*2, 64*4, 4, 3, 2, bias=False), # 输入通道为64*2,输出通道为64*4,4x4的卷积核,步长为3,padding为2
nn.BatchNorm2d(64*4, momentum=0.1, eps=0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64*4, 64*8, 4, 3, 2, bias=False), # 输入通道为64*4,输出通道为64*8,4x4的卷积核,步长为3,padding为2
nn.BatchNorm2d(64*8, momentum=0.1, eps=0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Flatten(), # 将特征图展平为一维向量,用于后续全连接层处理
nn.Dropout(0.4), # 随机失活层,用于减少过拟合风险
nn.Linear(4608, 1), # 全连接层,将特征向量映射到输出维度为1的向量
nn.Sigmoid() # Sigmoid激活函数,用于输出范围限制在0到1之间的概率值
)
def forward(self, inputs):
img, label = inputs
# 将类别标签转换为特征向量
label_output = self.label_condition_disc(label)
# 重塑特征向量为与图像尺寸相匹配的特征张量
label_output = label_output.view(-1, 3, 128, 128)
# 将图像特征和标签特征拼接在一起作为鉴别器的输入
concat = torch.cat((img, label_output), dim=1)
# 将拼接后的输入通过鉴别器模型进行前向传播,得到输出结果
output = self.model(concat)
return output
discriminator = Discriminator().to(device)
discriminator.apply(weights_init)
print(discriminator)
Discriminator(
(label_condition_disc): Sequential(
(0): Embedding(3, 100)
(1): Linear(in_features=100, out_features=49152, bias=True)
)
(model): Sequential(
(0): Conv2d(6, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): LeakyReLU(negative_slope=0.2, inplace=True)
(2): Conv2d(64, 128, kernel_size=(4, 4), stride=(3, 3), padding=(2, 2), bias=False)
(3): BatchNorm2d(128, eps=0.8, momentum=0.1, affine=True, track_running_stats=True)
(4): LeakyReLU(negative_slope=0.2, inplace=True)
(5): Conv2d(128, 256, kernel_size=(4, 4), stride=(3, 3), padding=(2, 2), bias=False)
(6): BatchNorm2d(256, eps=0.8, momentum=0.1, affine=True, track_running_stats=True)
(7): LeakyReLU(negative_slope=0.2, inplace=True)
(8): Conv2d(256, 512, kernel_size=(4, 4), stride=(3, 3), padding=(2, 2), bias=False)
(9): BatchNorm2d(512, eps=0.8, momentum=0.1, affine=True, track_running_stats=True)
(10): LeakyReLU(negative_slope=0.2, inplace=True)
(11): Flatten(start_dim=1, end_dim=-1)
(12): Dropout(p=0.4, inplace=False)
(13): Linear(in_features=4608, out_features=1, bias=True)
(14): Sigmoid()
)
)
summary(discriminator)
=================================================================
Layer (type:depth-idx) Param #
Discriminator –
├─Sequential: 1-1 –
│ └─Embedding: 2-1 300
│ └─Linear: 2-2 4,964,352
├─Sequential: 1-2 –
│ └─Conv2d: 2-3 6,144
│ └─LeakyReLU: 2-4 –
│ └─Conv2d: 2-5 131,072
│ └─BatchNorm2d: 2-6 256
│ └─LeakyReLU: 2-7 –
│ └─Conv2d: 2-8 524,288
│ └─BatchNorm2d: 2-9 512
│ └─LeakyReLU: 2-10 –
│ └─Conv2d: 2-11 2,097,152
│ └─BatchNorm2d: 2-12 1,024
│ └─LeakyReLU: 2-13 –
│ └─Flatten: 2-14 –
│ └─Dropout: 2-15 –
│ └─Linear: 2-16 4,609
│ └─Sigmoid: 2-17 –
Total params: 7,729,709
Trainable params: 7,729,709
Non-trainable params: 0
a = torch.ones(2,3,128,128)
b = torch.ones(2,1)
b = b.long()
a = a.to(device)
b = b.to(device)
c = discriminator((a,b))
c.size()
torch.Size([2, 1])
三、训练模型
1. 定义损失函数
adversarial_loss = nn.BCELoss()
def generator_loss(fake_output, label):
gen_loss = adversarial_loss(fake_output, label)
return gen_loss
def discriminator_loss(output, label):
disc_loss = adversarial_loss(output, label)
return disc_loss
2. 定义优化器
learning_rate = 0.0002
G_optimizer = optim.Adam(generator.parameters(), lr = learning_rate, betas=(0.5, 0.999))
D_optimizer = optim.Adam(discriminator.parameters(), lr = learning_rate, betas=(0.5, 0.999))
3. 训练模型
# 设置训练的总轮数
num_epochs = 100
# 初始化用于存储每轮训练中判别器和生成器损失的列表
D_loss_plot, G_loss_plot = [], []
# 循环进行训练
for epoch in range(1, num_epochs + 1):
# 初始化每轮训练中判别器和生成器损失的临时列表
D_loss_list, G_loss_list = [], []
# 遍历训练数据加载器中的数据
for index, (real_images, labels) in enumerate(train_loader):
# 清空判别器的梯度缓存
D_optimizer.zero_grad()
# 将真实图像数据和标签转移到GPU(如果可用)
real_images = real_images.to(device)
labels = labels.to(device)
# 将标签的形状从一维向量转换为二维张量(用于后续计算)
labels = labels.unsqueeze(1).long()
# 创建真实目标和虚假目标的张量(用于判别器损失函数)
real_target = Variable(torch.ones(real_images.size(0), 1).to(device))
fake_target = Variable(torch.zeros(real_images.size(0), 1).to(device))
# 计算判别器对真实图像的损失
D_real_loss = discriminator_loss(discriminator((real_images, labels)), real_target)
# 从噪声向量中生成假图像(生成器的输入)
noise_vector = torch.randn(real_images.size(0), latent_dim, device=device)
noise_vector = noise_vector.to(device)
generated_image = generator((noise_vector, labels))
# 计算判别器对假图像的损失(注意detach()函数用于分离生成器梯度计算图)
output = discriminator((generated_image.detach(), labels))
D_fake_loss = discriminator_loss(output, fake_target)
# 计算判别器总体损失(真实图像损失和假图像损失的平均值)
D_total_loss = (D_real_loss + D_fake_loss) / 2
D_loss_list.append(D_total_loss)
# 反向传播更新判别器的参数
D_total_loss.backward()
D_optimizer.step()
# 清空生成器的梯度缓存
G_optimizer.zero_grad()
# 计算生成器的损失
G_loss = generator_loss(discriminator((generated_image, labels)), real_target)
G_loss_list.append(G_loss)
# 反向传播更新生成器的参数
G_loss.backward()
G_optimizer.step()
# 打印当前轮次的判别器和生成器的平均损失
print('Epoch: [%d/%d]: D_loss: %.3f, G_loss: %.3f' % (
(epoch), num_epochs, torch.mean(torch.FloatTensor(D_loss_list)),
torch.mean(torch.FloatTensor(G_loss_list))))
# 将当前轮次的判别器和生成器的平均损失保存到列表中
D_loss_plot.append(torch.mean(torch.FloatTensor(D_loss_list)))
G_loss_plot.append(torch.mean(torch.FloatTensor(G_loss_list)))
if epoch%10 == 0:
# 将生成的假图像保存为图片文件
save_image(generated_image.data[:50], './images/sample_%d' % epoch + '.png', nrow=5, normalize=True)
# 将当前轮次的生成器和判别器的权重保存到文件
torch.save(generator.state_dict(), './training_weights/generator_epoch_%d.pth' % (epoch))
torch.save(discriminator.state_dict(), './training_weights/discriminator_epoch_%d.pth' % (epoch))
Epoch: [1/100]: D_loss: 0.459, G_loss: 1.847
Epoch: [2/100]: D_loss: 0.429, G_loss: 1.891
Epoch: [3/100]: D_loss: 0.378, G_loss: 2.014
Epoch: [4/100]: D_loss: 0.410, G_loss: 2.024
Epoch: [5/100]: D_loss: 0.391, G_loss: 1.965
Epoch: [6/100]: D_loss: 0.422, G_loss: 2.121
Epoch: [7/100]: D_loss: 0.386, G_loss: 1.826
Epoch: [8/100]: D_loss: 0.369, G_loss: 1.891
Epoch: [9/100]: D_loss: 0.445, G_loss: 1.864
Epoch: [10/100]: D_loss: 0.393, G_loss: 1.648
Epoch: [11/100]: D_loss: 0.480, G_loss: 1.720
Epoch: [12/100]: D_loss: 0.475, G_loss: 1.587
Epoch: [13/100]: D_loss: 0.435, G_loss: 1.493
Epoch: [14/100]: D_loss: 0.431, G_loss: 1.545
Epoch: [15/100]: D_loss: 0.426, G_loss: 1.539
Epoch: [16/100]: D_loss: 0.432, G_loss: 1.590
Epoch: [17/100]: D_loss: 0.448, G_loss: 1.670
Epoch: [18/100]: D_loss: 0.426, G_loss: 1.670
Epoch: [19/100]: D_loss: 0.438, G_loss: 1.640
Epoch: [20/100]: D_loss: 0.418, G_loss: 1.697
Epoch: [21/100]: D_loss: 0.425, G_loss: 1.710
Epoch: [22/100]: D_loss: 0.440, G_loss: 1.711
Epoch: [23/100]: D_loss: 0.404, G_loss: 1.668
Epoch: [24/100]: D_loss: 0.447, G_loss: 1.821
Epoch: [25/100]: D_loss: 0.418, G_loss: 1.664
Epoch: [26/100]: D_loss: 0.432, G_loss: 1.754
Epoch: [27/100]: D_loss: 0.433, G_loss: 1.747
Epoch: [28/100]: D_loss: 0.385, G_loss: 1.777
Epoch: [29/100]: D_loss: 0.408, G_loss: 1.754
Epoch: [30/100]: D_loss: 0.556, G_loss: 2.157
Epoch: [31/100]: D_loss: 0.357, G_loss: 1.710
Epoch: [32/100]: D_loss: 0.351, G_loss: 1.775
Epoch: [33/100]: D_loss: 0.382, G_loss: 1.757
Epoch: [34/100]: D_loss: 0.356, G_loss: 1.800
Epoch: [35/100]: D_loss: 0.392, G_loss: 1.887
Epoch: [36/100]: D_loss: 0.387, G_loss: 1.942
Epoch: [37/100]: D_loss: 0.341, G_loss: 1.912
Epoch: [38/100]: D_loss: 0.359, G_loss: 1.883
Epoch: [39/100]: D_loss: 0.428, G_loss: 2.079
Epoch: [40/100]: D_loss: 0.340, G_loss: 1.952
Epoch: [41/100]: D_loss: 0.341, G_loss: 1.979
Epoch: [42/100]: D_loss: 0.487, G_loss: 2.264
Epoch: [43/100]: D_loss: 0.344, G_loss: 1.975
Epoch: [44/100]: D_loss: 0.330, G_loss: 1.968
Epoch: [45/100]: D_loss: 0.333, G_loss: 2.034
Epoch: [46/100]: D_loss: 0.357, G_loss: 2.165
Epoch: [47/100]: D_loss: 0.355, G_loss: 2.154
Epoch: [48/100]: D_loss: 0.319, G_loss: 2.067
Epoch: [49/100]: D_loss: 0.354, G_loss: 2.202
Epoch: [50/100]: D_loss: 0.364, G_loss: 2.164
Epoch: [51/100]: D_loss: 0.307, G_loss: 2.183
Epoch: [52/100]: D_loss: 0.342, G_loss: 2.333
Epoch: [53/100]: D_loss: 0.519, G_loss: 2.449
Epoch: [54/100]: D_loss: 0.292, G_loss: 2.117
Epoch: [55/100]: D_loss: 0.296, G_loss: 2.203
Epoch: [56/100]: D_loss: 0.381, G_loss: 2.258
Epoch: [57/100]: D_loss: 0.318, G_loss: 2.319
Epoch: [58/100]: D_loss: 0.287, G_loss: 2.245
Epoch: [59/100]: D_loss: 0.294, G_loss: 2.271
Epoch: [60/100]: D_loss: 0.327, G_loss: 2.332
Epoch: [61/100]: D_loss: 0.304, G_loss: 2.368
Epoch: [62/100]: D_loss: 0.267, G_loss: 2.339
Epoch: [63/100]: D_loss: 0.437, G_loss: 2.554
Epoch: [64/100]: D_loss: 0.338, G_loss: 2.412
Epoch: [65/100]: D_loss: 0.278, G_loss: 2.335
Epoch: [66/100]: D_loss: 0.265, G_loss: 2.430
Epoch: [67/100]: D_loss: 0.482, G_loss: 2.622
Epoch: [68/100]: D_loss: 0.470, G_loss: 2.800
Epoch: [69/100]: D_loss: 0.249, G_loss: 2.336
Epoch: [70/100]: D_loss: 0.248, G_loss: 2.392
Epoch: [71/100]: D_loss: 0.271, G_loss: 2.485
Epoch: [72/100]: D_loss: 0.259, G_loss: 2.444
Epoch: [73/100]: D_loss: 0.259, G_loss: 2.547
Epoch: [74/100]: D_loss: 0.240, G_loss: 2.582
Epoch: [75/100]: D_loss: 0.261, G_loss: 2.562
Epoch: [76/100]: D_loss: 0.273, G_loss: 2.536
Epoch: [77/100]: D_loss: 0.270, G_loss: 2.608
Epoch: [78/100]: D_loss: 0.270, G_loss: 2.674
Epoch: [79/100]: D_loss: 0.243, G_loss: 2.684
Epoch: [80/100]: D_loss: 0.285, G_loss: 2.690
Epoch: [81/100]: D_loss: 0.899, G_loss: 2.765
Epoch: [82/100]: D_loss: 0.456, G_loss: 2.312
Epoch: [83/100]: D_loss: 0.293, G_loss: 2.443
Epoch: [84/100]: D_loss: 0.247, G_loss: 2.535
Epoch: [85/100]: D_loss: 0.246, G_loss: 2.565
Epoch: [86/100]: D_loss: 0.236, G_loss: 2.611
Epoch: [87/100]: D_loss: 0.232, G_loss: 2.672
Epoch: [88/100]: D_loss: 0.234, G_loss: 2.739
Epoch: [89/100]: D_loss: 0.250, G_loss: 2.732
Epoch: [90/100]: D_loss: 0.225, G_loss: 2.801
Epoch: [91/100]: D_loss: 0.229, G_loss: 2.827
Epoch: [92/100]: D_loss: 0.270, G_loss: 2.903
Epoch: [93/100]: D_loss: 0.239, G_loss: 2.881
Epoch: [94/100]: D_loss: 0.317, G_loss: 2.845
Epoch: [95/100]: D_loss: 0.243, G_loss: 2.881
Epoch: [96/100]: D_loss: 0.201, G_loss: 2.919
Epoch: [97/100]: D_loss: 0.227, G_loss: 2.862
Epoch: [98/100]: D_loss: 0.270, G_loss: 2.968
Epoch: [99/100]: D_loss: 0.284, G_loss: 2.922
Epoch: [100/100]: D_loss: 0.221, G_loss: 2.898
四、模型分析
1. 加载模型
generator.load_state_dict(torch.load('./training_weights/generator_epoch_100.pth'), strict=False)
generator.eval()
Generator(
(label_conditioned_generator): Sequential(
(0): Embedding(3, 100)
(1): Linear(in_features=100, out_features=16, bias=True)
)
(latent): Sequential(
(0): Linear(in_features=100, out_features=8192, bias=True)
(1): LeakyReLU(negative_slope=0.2, inplace=True)
)
(model): Sequential(
(0): ConvTranspose2d(513, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=0.8, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): ConvTranspose2d(512, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=0.8, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): ConvTranspose2d(256, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(7): BatchNorm2d(128, eps=0.8, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
(9): ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(10): BatchNorm2d(64, eps=0.8, momentum=0.1, affine=True, track_running_stats=True)
(11): ReLU(inplace=True)
(12): ConvTranspose2d(64, 3, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(13): Tanh()
)
)
# 导入所需的库
from numpy import asarray
from numpy.random import randn
from numpy.random import randint
from numpy import linspace
from matplotlib import pyplot
from matplotlib import gridspec
# 生成潜在空间的点,作为生成器的输入
def generate_latent_points(latent_dim, n_samples, n_classes=3):
# 从标准正态分布中生成潜在空间的点
x_input = randn(latent_dim * n_samples)
# 将生成的点整形成用于神经网络的输入的批量
z_input = x_input.reshape(n_samples, latent_dim)
return z_input
# 在两个潜在空间点之间进行均匀插值
def interpolate_points(p1, p2, n_steps=10):
# 在两个点之间进行插值,生成插值比率
ratios = linspace(0, 1, num=n_steps)
# 线性插值向量
vectors = list()
for ratio in ratios:
v = (1.0 - ratio) * p1 + ratio * p2
vectors.append(v)
return asarray(vectors)
# 生成两个潜在空间的点
pts = generate_latent_points(100, 2)
# 在两个潜在空间点之间进行插值
interpolated = interpolate_points(pts[0], pts[1])
# 将数据转换为torch张量并将其移至GPU(假设device已正确声明为GPU)
interpolated = torch.tensor(interpolated).to(device).type(torch.float32)
output = None
# 对于三个类别的循环,分别进行插值和生成图片
for label in range(3):
# 创建包含相同类别标签的张量
labels = torch.ones(10) * label
labels = labels.to(device)
labels = labels.unsqueeze(1).long()
print(labels.size())
# 使用生成器生成插值结果
predictions = generator((interpolated, labels))
predictions = predictions.permute(0,2,3,1)
pred = predictions.detach().cpu()
if output is None:
output = pred
else:
output = np.concatenate((output,pred))
torch.Size([10, 1])
torch.Size([10, 1])
torch.Size([10, 1])
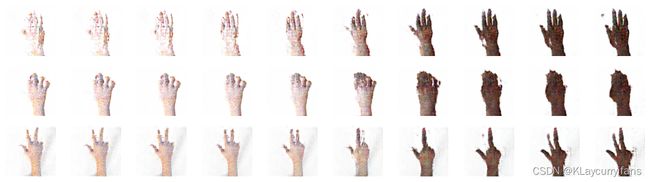
output.shape
nrow = 3
ncol = 10
fig = plt.figure(figsize=(15,4))
gs = gridspec.GridSpec(nrow, ncol)
k = 0
for i in range(nrow):
for j in range(ncol):
pred = (output[k, :, :, :] + 1 ) * 127.5
pred = np.array(pred)
ax= plt.subplot(gs[i,j])
ax.imshow(pred.astype(np.uint8))
ax.set_xticklabels([])
ax.set_yticklabels([])
ax.axis('off')
k += 1
plt.show()