微信基于StarRocks的湖仓一体实践
作者:StarRocks Active Contributer、微信 OLAP 内核研发工程师
微信作为国内活跃用户最多的社交软件,其数据平台建设经历了从 Hadoop 到 ClickHouse 亚秒级实时数仓的阶段,但仍旧面临着数据体验割裂、存储冗余的问题。通过 StarRocks 的湖仓一体方案,以及和社区密切配合开发的实时增量物化视图,微信解决了“实时、极速”背后的“统一”诉求。在直播业务场景中,通过湖上建仓的方案改造,使得数据开发同学需要运维的任务数减半,同时存储成本降低65%以上,离线任务产出时间缩短两小时。
当前,基于 StarRocks 的湖仓一体方案已经在微信的多个业务场景中上线使用,包括视频号直播、微信键盘、微信读书和公众号等,集群规模达到数百台机器,数据接入量近千亿,向理想化的湖仓一体形态不断演进。
背景
从 Hadoop 到亚秒级实时数仓建设:多年以前,微信的数据分析架构还是完全基于 Hadoop 生态的,其存在着较多的弊端:首先,查询非常慢,数据延迟高,业务同学进行数据开发也很慢;其次,在架构方面,采用的是流批分离的架构,整体架构非常臃肿。
随着微信业务的不断发展,视频号等推荐系统对个性化体验的强烈诉求,我们基于 ClickHouse 内核打造了亚秒级的 OLAP 实时数仓,广泛用于 A/B 实验平台、BI 分析、实时指标计算等场景中。在基于 ClickHouse 的实时数仓中,我们做到了亿行数据的亚秒级响应,海量数据的低延迟、精确一次接入,实现了流批一体架构。
“实时、极速”后的“统一”诉求:一直以来,数据分析技术栈从 MySQL 开始基本上是沿着两条路线不断往前演进的,一条是实时的路线,另一条是极速的路线。实时的路线经历了从 Lambda 架构到 Kappa 架构,再演进到最近的 Data Lake,形成流批一体;而极速的路线经历了从 Hive 小时以上的分析时延,然后演进到 SparkSQL,再到 Presto/Druid/Kylin 达到分钟级的查询时延,最终演进到了诸如 ClickHouse 这类的 OLAP 数据库,达到亚秒级响应。从未来的趋势来看,两者会形成统一,这也是湖仓一体/Modern OLAP 所要达到的目标。

在微信的数据分析场景中,主要面临三个方面的挑战:
- 海量数据:在我们的业务场景下,数据规模很大,单表日增万亿,单次查询扫描数据量在10亿以上,同时需要计算的指标和维度可能会非常多(50+维度,100+指标);
- 极速:微信业务场景对查询耗时要求极高,查询耗时 TP 90 需要在5秒以内,同时要求数据低时效(秒/分钟);
- 统一:我们希望能够实现计算侧和存储侧的统一。
过去,在基于 ClickHouse 的实时数仓中,我们已经解决了海量数据和极速的挑战,但还有一个统一的需求没有解决。
湖仓一体
湖仓一体要解决的是通用大数据计算引擎处理 OLAP 数仓体验割裂、存储多份的问题。过去,无论是在湖上面还是仓上面,都存在着相应的困境。
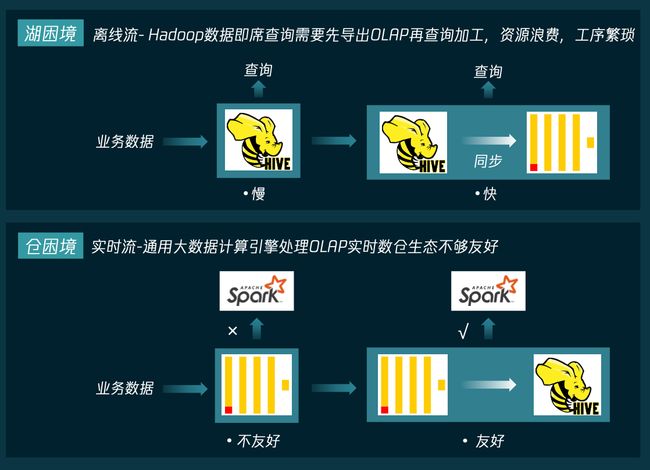
湖上面面临的主要问题是查询性能太慢,如果需要对 Hadoop 中的数据进行即席查询,则需要先将数据导出到 OLAP 数据库中再进行查询加工,造成了资源的浪费,工序繁琐;而仓上面,存在着通用大数据计算引擎处理 OLAP 实时数仓生态不够友好的问题,例如,Spark 无法直接分析 ClickHouse 中的数据,如果要进行查询分析,则需要先将数据从 ClickHouse 落回 Hive 中。总结来看,过去的架构存在的问题就是:
- 两份存储
- 口径不一致
- 额外的数据导入导出步骤
- 数据分析流程难以标准化
通过湖仓一体架构,我们希望能够真正解决上述问题,实现存储统一、接口统一、元数据统一,亚秒级查询与分钟级查询统一等,最终理想化的湖仓一体形态:面向SQL,用户不再需要感知底层架构。
技术路线一:湖上建仓
实现湖仓一体的第一种技术路线是湖上建仓,即在数据湖基础上实现数仓的功能,代替传统数仓,构建 Lakehouse:在传统 Hadoop 系统中引入 Delta lake、Hudi、Iceberg 或 Hive 3.0 等更新技术;引入 Presto、Impala 等 SQL on Hadoop 查询引擎;引入 Hive Meta Store 进行统一元数据和权限管理;引入对象存储作为底层存储等数仓特性,形成湖仓一体,业务比较有代表性的是 Databricks 提出的湖仓一体架构。 在微信内部,湖上建仓的架构经历了从 Presto+Hive 到 StarRocks + Iceberg 的演变过程,通过使用 StarRocks 替代 Presto,数据的时效性从小时/天级提高到了分钟级,同时查询效率从分钟级提高到了秒级/分钟级,其中80%的大查询用 StarRocks解决,秒级返回,剩下的超大查询通过 Spark 来解决。
- 秒级: 中大表,秒级返回,StarRocks
- 分钟级:大表查询,分钟级,Spark

与 Presto 相比,StarRocks 直接查湖的性能提升 3-6 倍以上。

目前,在我们的使用场景中,湖上建仓的方案主要通过外挂调度的方式来实现。未来,当 StarRocks 的外表物化视图功能更加成熟以后,会采用更加简洁、方便、易于运维的外表物化视图来实现。

湖上建仓方案具有的优点是成本低,实现简单,同时 Hadoop 生态兼容性更好。但其存在的缺点是:数据延迟较高,需要5-10分钟左右;另外,ODS、DWD 层的查询会比较慢,需要通过本地缓存等方式来进行加速。因此,综合来看,湖上建仓的方案主要还是湖为主,更适合于离线分析为主的场景。
技术路线二:仓湖融合
实现湖仓一体的第二种技术路线是仓湖融合,通过在数仓中加入跨源融合联邦查询的功能,打通内容存储,从而不需要经过 ETL 能够直接分析数据湖。在该方案中,我们采用冷存下沉的手段,实现仓湖数据的统一。

在该方案中,数据会先实时接入仓,之后,冷存经过转换下沉到湖,通过 Meta Server 实现仓湖元数据的统一管理,在查询时,能够合并冷热数据读取,同时,通过 SparkLake API 提供对通用离线计算的支持。在该方案中,由于数据是先落仓的,因此数据的实时性会更高,在秒级到2分钟以内,同时 DWD 层的查询响应会更快。但其缺点是成本高(热数据TTL),Hadoop 生态兼容性不如湖上建仓的方案。因此,综合来看,仓湖融合的方案主要还是考虑仓为主,更适合于实时分析为主的场景。
当前,仓湖融合、冷存下沉的湖仓一体方案已经在微信安全的业务场景中落地,接入的大表每日数据量达数十亿,超大表每日数据量千亿以上。小时分区降冷耗时分钟级,天分区降冷耗时小时级;在内存消耗方面,单任务最大消耗 5GB 左右,对集群无明显影响。
同时,通过 BE/FE 参数调优: compaction 线程数比例调整、flush 线程数调整、并发事务数调整,消除了大表并发时的数据挤压,全天稳定运行:
上线前
上线后
湖仓一体架构
从前面的分析中可以看到,湖上建仓和仓湖融合两种方案各有优缺点,分别适用于湖为主和仓为主的业务场景,而在微信的业务场景中,两种路线都有需求。
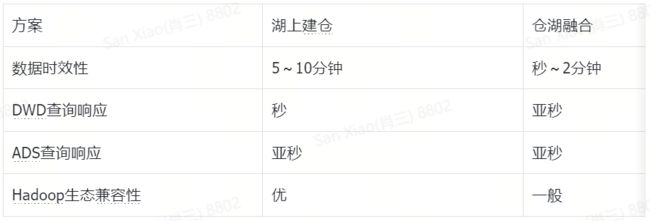
因此,在我们的湖仓一体方案中,采用的是湖上建仓和仓下沉湖的融合方案。

在该方案中,我们同时支持实时接入和准实时接入,用户可以根据自身对成本、性能和数据时效性的要求来选择通过哪种方式进行接入,并且是可切换的。例如,刚开始时,用户对性能、数据时效性要求不是特别高,那么可以选择通过湖接入的方式,这样成本较低,当后续该用户对性能和数据时效性要求变高了,那么他可以切换到仓接入的方式,这样就可以满足需求。因此,在我们的湖仓一体架构中,既能够支持极速 BI 分析的场景,也能够满足通用离线计算的需求。
实时增量物化视图
过去,在 StarRocks 中主要有两种不同类型的物化视图:异步物化视图和同步物化视图。
异步物化视图会根据基表的数据变化,定时触发刷新或手动刷新物化视图更新数据变化,在进行刷新时,需要对整个表或整个分区进行一次完整的 INSERT OVERWRITE,如下图所示。在查询基础表时,优化器会根据物化视图定义自动进行查询改写,从而利用物化视图的预计算结果来对查询进行加速,同时也可以直接查询物化视图表的数据。

然而,由于需要不断进行分区级的 INSERT OVERWRITE 刷新,当基础表的数据量比较大时,这一刷新的过程开销会非常大,容易影响集群整体负载和稳定性;同时,物化视图是通过异步刷新来更新数据的,更适合于离线数仓场景,而不适用于实时数仓场景。
同步物化视图能够在数据写入基础表的时候同步刷新物化视图。与异步物化视图不同的是,同步物化视图的结果是作为一个 Index 和基础表绑定在一起的,物化视图本身对用户不可见,不能直接查询。在查询基础表数据时,能够基于基础表中存在的同步物化视图进行透明加速
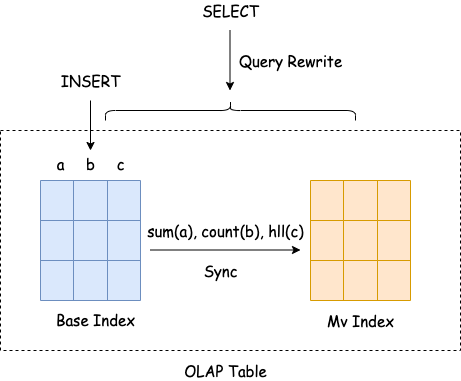
然而, StarRocks 的同步物化视图具有一些限制:
- 不支持复杂表达式,仅能够对基础表中的列进行简单的聚合操作,无论是维度列还是指标列中,都不能包含复杂表达式;
- 不支持输出列别名;
- 基础表中的列不能在物化视图中被多次引用;
- 仅支持少量聚合函数,不支持通用聚合函数;
- 物化视图数据与基础表强绑定,无法直接查询物化视图数据。
在湖仓一体场景下,对于实时性、性能要求高的场景,我们需要通过实时增量物化视图来进行加速。微信的实时物化视图具有如下一些特点:
- 大规模,单表数据量大,因此物化视图只能增量更新,不能全量刷新
- 实时性要求高:需要同步刷新,不能异步刷新
- 多表指标拼接:多个基础表的物化视图计算指标拼接到同一个物化视图目标表中
- 在物化视图写入时进行高性能维表关联
- ...
针对这些特点和要求,我们基于 StarRocks 的物化视图功能,与社区共同在过去的同步物化视图基础上进行了新的探索,以适应这类更加复杂的分析
物化视图增强技术路线: 多流同步物化视图 -> 全局字典关联 -> streaming 物化视图(doing) -> 湖上增量同步物化视图
目前实现到第二阶段,已经可以实现多数 ClickHouse 增量同步物化视图的能力,下边详细介绍:
多流同步物化视图
在新的实时增量物化视图设计中,我们将基础表与存储物化视图结果的目标表进行了解耦,物化视图本身仅用来表达计算逻辑,如下图所示。这样做有多个方面的原因:
- 在数仓体系中,基础表通常属于 ODS 层,需要保留3~7天,而存储物化视图结果的目标表属于 DWS 层,通常需要保留半年到一年,将这两者解耦之后,我们才能够分别为其定义不同的存储周期。
- 将物化视图的计算逻辑和计算结果完全解耦,业务不需要关心具体的计算逻辑,直接查询物化视图目标表中存储的指标结果即可,能够极大提高易用性,同时能够将上下游业务逻辑解耦,上游计算逻辑发生变化不会影响下游使用。
- 最后,只有将两者解耦,我们才能够实现多个基础表的协议关联,通过让多个基础表的物化视图计算结果写同一个目标表,从而完成指标拼接。

基于全局字典的维表关联
在我们的物化视图场景中,另一个比较关联的需求是基于全局字典的维表关联。维表关联是在 BI 场景、流式计算中一个非常通用的问题。在过去,我们需要依赖于 Flink 任务在上游先完成维表关联的工作,得到中间表,然后再将中间表写入物化视图进行查询加速。而基于高性能的全局字典功能,我们能够在数据写入时,通过查询字典表,直接在 OLAP 数据库的内部完成维度表的关联,从而不再需要依赖于繁重的 Flink 任务,同时,字典表也可以用于优化 BI 查询的 JOIN 性能。

未来
当前,我们已经支持多流同步物化视图,同时社区全局字典功能也基本可用。但是,目前的多流同步物化视图仍然存在较多限制:例如,不支持 JOIN,不支持通用聚合函数等。未来,我们希望新的 Stream MV 能够消除上述限制,进一步满足更多的业务场景;更进一步,Stream MV 结合外表物化视图,达到湖上实时增量物化视图,成为更好的湖上建仓方案。
总结与展望
当前,基于 StarRocks 的湖仓一体方案已经在微信的多个业务场景中上线使用,包括视频号直播、微信键盘、微信读书和公众号等,集群规模达到数百台机器,数据接入量近千亿。
在收益方面,我们以一个具体的业务来举例,在直播业务场景中,通过湖上建仓的方案改造,使得数据开发同学需要运维的任务数减半,同时存储成本降低 65% 以上,离线任务产出时间缩短两小时。
未来,我们希望不断探索和完善现有的湖仓一体架构,最终能够达到理想中的湖仓一体:
- 面向 SQL,用户不再感知底层架构;
- 接入/查询体验统一,存储统一;
- 秒级/分钟级延迟架构体验统一,亚秒/分钟级分析统一;
- 单个/百 QPS 体验统一;
- SQL 交互标准统一。
致谢:感谢“腾讯大数据团队”提供稳定内部集群和各类技术支持,帮助业务落地;感谢" StarRocks 社区"在功能开发,问题定位解决上的诸多帮忙,祝愿社区发展的越来越好!
本文由 mdnice 多平台发布