linux 内核链表操作
操作系统内核, 如同其他程序, 常常需要维护数据结构的列表. 有时, Linux 内核已经同
时有几个列表实现. 为减少复制代码的数量, 内核开发者已经创建了一个标准环形的, 双
链表; 鼓励需要操作列表的人使用这个设施.
当使用链表接口时, 你应当一直记住列表函数不做加锁. 如果你的驱动可能试图对同一个
列表并发操作, 你有责任实现一个加锁方案. 可选项( 破坏的列表结构, 数据丢失, 内核
崩溃) 肯定是难以诊断的.
为使用列表机制, 你的驱动必须包含文件
类型 list_head 结构:
struct list_head { struct list_head *next, *prev; };
真实代码中使用的链表几乎是不变地由几个结构类型组成, 每一个描述一个链表中的入口
项. 为在你的代码中使用 Linux 列表, 你只需要嵌入一个 list_head 在构成这个链表的
结构里面. 假设, 如果你的驱动维护一个列表, 它的声明可能看起来象这样:
struct todo_struct
{
struct list_head list;
int priority; /* driver specific */
/* ... add other driver-specific fields */
};
列表的头常常是一个独立的 list_head 结构. 图链表头数据结构显示了这个简单的
struct list_head 是如何用来维护一个数据结构的列表的.
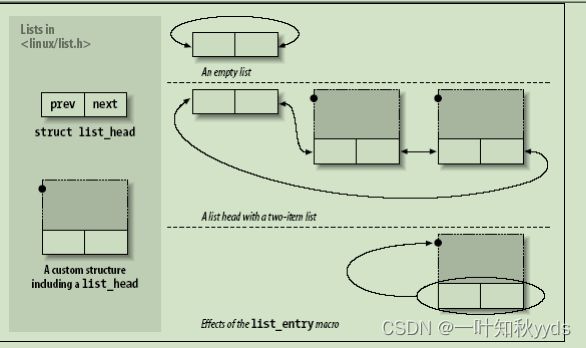
链表头数据结构
链表头必须在使用前用 INIT_LIST_HEAD 宏来初始化. 一个"要做的事情"的链表头可能声
明并且初始化用:
struct list_head todo_list;
INIT_LIST_HEAD(&todo_list);
LIST_HEAD(todo_list);
几个使用链表的函数定义在
list_add(struct list_head *new, struct list_head *head);
在紧接着链表 head 后面增加新入口项 -- 正常地在链表的开头. 因此, 它可用来
构建堆栈. 但是, 注意, head 不需要是链表名义上的头; 如果你传递一个
list_head 结构, 它在链表某处的中间, 新的项紧靠在它后面. 因为 Linux 链表
是环形的, 链表的头通常和任何其他的项没有区别.
list_add_tail(struct list_head *new, struct list_head *head);
刚好在给定链表头前面增加一个新入口项 -- 在链表的尾部, 换句话说.
list_add_tail 能够, 因此, 用来构建先入先出队列.
list_del(struct list_head *entry);
list_del_init(struct list_head *entry);
给定的项从队列中去除. 如果入口项可能注册在另外的链表中, 你应当使用
list_del_init, 它重新初始化这个链表指针.
list_move(struct list_head *entry, struct list_head *head);
list_move_tail(struct list_head *entry, struct list_head *head);
给定的入口项从它当前的链表里去除并且增加到 head 的开始. 为安放入口项在新
链表的末尾, 使用 list_move_tail 代替.
list_empty(struct list_head *head);
如果给定链表是空, 返回一个非零值.
list_splice(struct list_head *list, struct list_head *head);
将 list 紧接在 head 之后来连接 2 个链表.
list_head 结构对于实现一个相似结构的链表是好的, 但是调用程序常常感兴趣更大的结
构, 它组成链表作为一个整体. 一个宏定义, list_entry, 映射一个 list_head 结构指
针到一个指向包含它的结构的指针. 它如下被调用:
list_entry(struct list_head *ptr, type_of_struct, field_name);
这里 ptr 是一个指向使用的 struct list_head 的指针, type_of_struct 是包含 ptr
的结构的类型, field_name 是结构中列表成员的名子. 在我们之前的 todo_struct 结构
中, 链表成员称为简单列表. 因此, 我们应当转变一个列表入口项为它的包含结构, 使用
这样一行:
struct todo_struct *todo_ptr = list_entry(listptr, struct todo_struct, list);
list_entry 宏定义使用了一些习惯的东西但是不难用.
链表的遍历是容易的: 只要跟随 prev 和 next 指针. 作为一个例子, 假设我们想保持
todo_struct 项的列表已降序的优先级顺序排列. 一个函数来添加新项应当看来如此:
void todo_add_entry(struct todo_struct *new)
{
struct list_head *ptr;
struct todo_struct *entry;
for (ptr = todo_list.next; ptr != &todo_list; ptr = ptr->next)
{
entry = list_entry(ptr, struct todo_struct, list);
if (entry->priority < new->priority) {
list_add_tail(&new->list, ptr);
return;
}
}
list_add_tail(&new->list, &todo_struct)
}
但是, 作为一个通用的规则, 最好使用一个预定义的宏来创建循环, 它遍历链表. 前一个
循环, 例如, 可这样编码:
void todo_add_entry(struct todo_struct *new)
{
struct list_head *ptr;
struct todo_struct *entry;
list_for_each(ptr, &todo_list)
{
entry = list_entry(ptr, struct todo_struct, list);
if (entry->priority < new->priority) {
list_add_tail(&new->list, ptr);
return;
}
}
list_add_tail(&new->list, &todo_struct)
}
使用提供的宏帮助避免简单的编程错误; 宏的开发者也已做了些努力来保证它们进行正常.
存在几个变体:
list_for_each(struct list_head *cursor, struct list_head *list)
这个宏创建一个 for 循环, 执行一次, cursor 指向链表中的每个连续的入口项.
小心改变列表在遍历它时.
list_for_each_prev(struct list_head *cursor, struct list_head *list)
这个版本后向遍历链表.
list_for_each_safe(struct list_head *cursor, struct list_head *next, struct
list_head *list)
如果你的循环可能删除列表中的项, 使用这个版本. 它简单的存储列表 next 中下
一个项, 在循环的开始, 因此如果 cursor 指向的入口项被删除, 它不会被搞乱.
list_for_each_entry(type *cursor, struct list_head *list, member)
list_for_each_entry_safe(type *cursor, type *next, struct list_head *list,
member)
这些宏定义减轻了对一个包含给定结构类型的列表的处理. 这里, cursor 是一个
指向包含数据类型的指针, member 是包含结构中 list_head 结构的名子. 有了这
些宏, 没有必要安放 list_entry 调用在循环里了.
如果你查看
单独的, 单指针列表头类型的双向链表; 它常用作创建哈希表和类型结构. 还有宏用来遍
历 2 种列表类型, 打算作使用 读取-拷贝-更新 机制(在第 5 章的"读取-拷贝-更新"一
节中描述 ). 这些原语在设备驱动中不可能有用; 看头文件如果你愿意知道更多信息关于
它们是如何工作的.