探索可解释及稳定性,AI与博弈,自适应推理——“智源论坛:机器学习青年学者报告会”要点总结
6月10日,北京智源人工智能研究院(BAAI)继“人工智能的数理基础”后,发布“机器学习”重大研究方向,由颜水成教授担任首席科学家,拟针对当前以深度学习、强化学习等为代表的人工智能算法所存在的可解释性缺失、大数据依赖,以及模型场景化这三大问题,聚焦“User-friendly AI”, 以4U(Understandable、Usable、Universal、Ubiquitous)为目标,从四个方面展开前沿人工智能算法研究。
在此之前,“智源论坛(第3期)——机器学习青年学者报告会”已于 2019 年 5 月 17 日邀请清华大学计算机系长聘副教授崔鹏、清华大学交叉信息研究院长聘副教授唐平中、清华大学自动化系助理教授黄高三位智源青年科学家,分享其在这一领域的研究经验。此次论坛主持人为“机器学习”方向智源研究项目经理,360集团人工智能研究院技术总监程斌。

程斌(智源研究项目经理)
论坛伊始,北京智源人工智能研究院副院长刘江在开场辞中表示,深度学习起初仅仅是一个以 Geoffrey Hinton(深度学习鼻祖)为首的小型学术群体,本质上不过是一个由加拿大政府资助的相对缘化的小项目。彼时,谁都没有料到其会在今天带来这样的成就与社会影响。“智源希望通将整个圈子的学者与工程师汇聚起来,随着思想的不断碰撞,也能在人工智能领域做出一些类似的突破,这是我们的初衷”。

刘江(北京智源人工智能研究院)
1
崔鹏:关联统计基础和独立同分布假设是当前机器学习在理论方法层面受制的深层原因
清华大学计算机系长聘副教授、博士生导师崔鹏博士率先带来了《Towards Explainable and Stable Prediction》主题报告,着重分享了其与团队近来在预测的可解释性及稳定性方面的研究。

崔鹏(清华大学)
在很长一段时间内,我们都惯乎将人工智能和机器学习技术应用到各种预测性的场景,常用的像是搜索引擎、推荐系统等在今天看来都算是相当成功的案例。过去的我们也总觉得人工智能犯些错似乎也无伤大雅,无外乎少牟些利,但现如今的人工智能却已然一脚踏入诸多和人乃至人的重大风险密切相关的领域——逐渐在医疗、司法、交通、金融等领域发挥起越来越重要的作用。这就使得我们不得不开始思考:如若人工智能出了问题,究竟会带来多大的风险?一时不察,可能便是性命攸关,或是涉及整个社会公正性的重大失误。因此,是时候把目光投向 AI 技术风险思考这一过去每每被忽略的研究课题了。
但当前人工智能的一个很明显的短板,就是不知其所以然。今天的绝大部分人工智能模型,尤其是深度学习,都是黑盒子模型。给定一个输入,模型会做出一个判断或预测,但没办法告诉我们,他为什么做出这样一个判断或预测,以及我们是否应该信任他的判断。
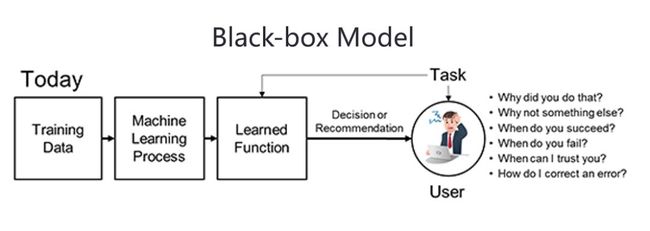
那么这会带来什么问题呢?首先,这直接导致人工智能的输出是不可解释的。我们知道,在很多风险敏感的应用领域,比如医疗、军事、金融等,人机需要协同。而人机协同的重要前提,是人和机器可以相互理解。而今天人工智能技术的输出不可解释,这直接导致了人工智能在这些领域落地难的问题。
此外,新一波人工智能在图像识别领域也取得了非常重大的突破,特别是在数据集上,甚至有媒体称其超过了人的识别能力。当然,在控制环境下确是如此,但若是放之于真实环境下,人工智能仍然存在着非常大的问题。此处以狗的图像识别为例,假设我们给出这样一个分布的数据,来训练一个简单的狗的分类器,而我们的数据未加任何限定(并没有框定只有哪一部分是狗,或者只有这个图片是狗):

我们看到训练数据中大部分狗都在草地上,少部分在普通地面上,那么这种情况下如果给出右侧第二张图这样的 test case,我们训练出的分类器可能就会误判;若是再把狗扔到水里面,该模型更是大概率判断不出这是一只狗的。这里的问题就在于我们给出的 test case 已经超出了其 Training Data 所覆盖的范围。通俗来讲,就是在训练数据中找不出一张图和提供的测试图长得像,这便是又一个我们现在解决不了的问题。
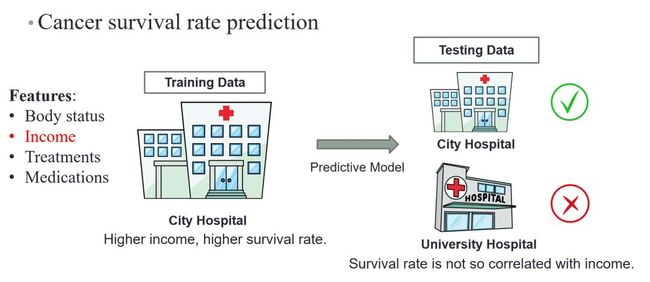
再从实际的 Health Care 中取例:假设我们现在要构建一个用于Cancer Survival Rate Prediction(癌症存活率)的模型,如果通过城市医院的数据来训练,就会发现病人的收入水平会在很大程度上决定其存活率。但如若我们将该模型应用到另一套数据(University Hospital)上来进行病人存活率预测,就会出现非常大的偏差,因为在 University Hospital 中,患者得到的治疗质量高低不取决于收入水平,而是取决于 Research Purpose。因此,将模型应用到分布不同的数据上时就会出现类似的问题。
那么这个问题到底出在哪里呢?事实上,我们今天的机器学习模型大多都是基于原始数据空间里一个所谓的 IID 独立同分布问题,即 Test Distribution 和前面的 Training Distribution 要从同一分布里独立采样出来,也就是说测试数据必须得和训练数据“长得”比较像,这种情况下才能保障其性能:
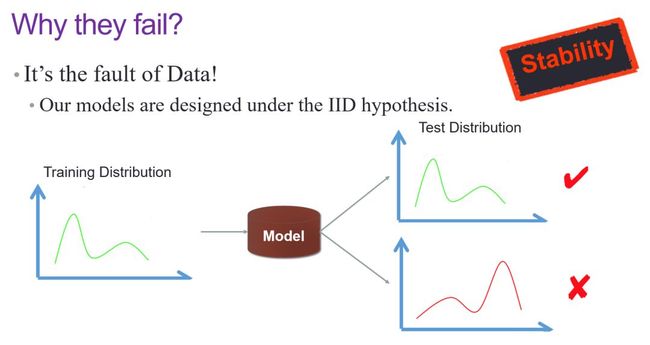
如上图所示,这一点会带来的一个很大的问题就是稳定性(Stability),因为当我们将训练出来的模型应用到不同场景下时,其实很难控制 Test Distribution 与 Training Distribution 的“相像”。而据我们在 ImageNet 数据集上做的统计数据显示,模型的最终 performance 在很大程度上会受到 NI 这一指标的影响(统计中定义的指标,指示其不 IID 的程度)。

既然已确认这类新问题的存在,又该如何解决?我们先来梳理一下,假设我们现在要用 Distribution 1 这个 Training Distribution 来训练一个模型(Model),如果我们的优化目标是优化其在 Distribution 1 下的准确性(Accuracy),那这里就是 IID Learning,因为我们假设是同一个 Distribution;那么假如优化目标是优化 Distribution n 下面的 Accuracy n,也就是说一个训练下面训练的数据能不能应用到另外一个 Distribution 下面?

那么 Transfer Learning 是否能解决这个问题呢?其实解决不了,因为 Transfer Learning 的假设是 Test Data 是已知的——已知 Test Data,才能已知 Test Distribution——已知Test Distribution,才知道原来这个模型应该往哪个方向去做 shiftting。
但是这在我们的真实应用场景下,其实也满足不了实际需求,因为大多数情况下我们训练一个模型,例如训练一个模型卖给不同的客户,对于其后续的应用场景一无所知,自然也无法控制其是否和我们的训练数据属于一个 Distribution。所以我们提出是不是还存在第三类问题,这类问题就是说我们在 Distribution 1 下面训练出来的一个模型,我们的优化目标是要优化其在不同 Distribution 下的精度方差。换言之,假设将我们在一个分布下面所训练出来的模型应用到很多未知分布上去,是否能控制其 performance 在所有这些分布上相对稳定,这是一个我们希望解决的问题,也是所谓的 Stable Prediction 问题。
而上文提到的两个风险中,一个是所谓的“稳定性”问题,一个是所谓的“可解释性”问题——实际上这两者最终都指向了一个统计量,也就是 Causality。我们经研究发现,如果用 Causality 指标替代掉原来的 Correlation 架构,就有可能解决这两个问题。
Causality for Explainability

如果我们把所有的图像里面的特征可视化出来,比如上图中圈出来的这些特征,可以分为两类,其一是确实和“狗”的这个标签存在比较强的 Correlation,但如果在此前的数据分布下面,因为大量的狗都会在草地上,所以草地这个 feature 实际上也会和狗产生比较大的关联,Correlation 也不会低。这个问题也解释了为什么当我们把这样一个场景给换掉,同样一只狗扔到水里可能就无法识别了。
我们认为上图中红框和黄框圈出的都是 Correlation feature,当然这里还可以再做一个区分,就是这些 Correlation feature 中到底哪些是 Causal feature(the feature cause the image to be a dog),例如狗的鼻子、眼睛、耳朵等特征。理想化的情况就是我们能更很好地辨别区分出 Causality,并据此呈现判断结果,他人就会很容易理解。所以如果我们能引入 Causality,就能够自然提升模型的可解释性。
Causality for Stability

另外,模型为什么会不稳定?假设原始特征是 X,那么 X 其实可以分化成两部分,分别是 S 和 V,如果 S 是 Causal feature 的部分, V 是Non-causal feature 的部分,那么如果用 Causal feature 去做预测,实际上对于整体数据的分布变化并不那么敏感。如果依据这些特征去识别,不管是在草地上还是水里或天上,都能判断它是一只狗。因此这里的关键问题是如何减掉 V 所带来的这种虚假性的关联,这是我们解决 Stability 问题的一个比较重要的途径。
如何解决 Stable Prediction 问题
传统的机器学习框架实际上都是这样的一个简单的 Correlation 架构,我们只关心一件事情,就是每一个输入变量和输出变量之间的关联:

在分布不变的情况下,我们就认为在 Training Distribution 里 X 和 Y 的关联,T 和 Y 的 关联可以作用到 Test Data 里面去,所以 X 和 T 对 Y 有预测效力。当然如果其分布产生了一些变化,它们之间的关联就不一定能够保持住。
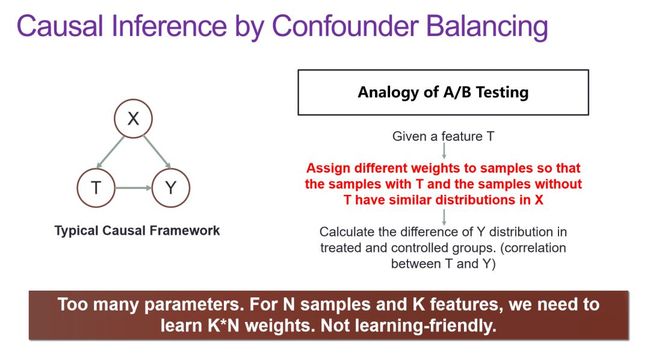
而如上图所示,Causal Framework 是一个这样一个三角形的结构,这个三角形结构的意思是说当我们试图去度量 T 对 Y 的作用时,要去控制 X。举个很简单的例子,比如我们现在在测试某种药物对于某种病的治愈率效果,那么我们肯定要找两群人,这两群人他们都患有同样的病,但是同时还必须保证他们在一些生物学指标上也一致,比如年龄、体重、身高、身体状态等的分布。与此同时,其中一群人给药,另一群人给安慰剂(避免心理作用)。最后我们就看这两组人在该疾病的治愈率上是否有差别。总结一下就是,假如这两群人在 X 上都能控制一致,而他们最后的治愈率也确实有差别,即在X 上都一样,只在 T 上不一样,我们就有理由认为 Y 的差异肯定是由 T 导致的(当然前提是所有变量都能控制住)。
Causality Framework 和 Correlation Framework 间最大的区别就在于,后者的情况下我们只关心输入和输出之间的关系,很少甚至从来不去讨论输入变量之间的关系,或者很少去做这方面的处理和控制;而前者实际上有很大一部分都是在做输入变量之间的辨识,而在这个辨识下面更有可能发现一些更可靠的关系,如果我们用这样的一个关系做预测的话,很显然稳定性就会更强。
实际上做 Causal Inference,最直接的就是做上文提到的这种控制实验(Control Experiment),但是当然又有一些场景我们没办法做控制实验,也就是说只有数据,却不能控制数据的产生过程,这种情况又该怎么办?这里就涉及到了 Absolute Matching,即在数据规模足够大的情况下,我们可以不去控制,但采样两组数据,使得这两组数据在 X 上的分布是差不多的,而且只在 T 上有差别,然后去看 Y 的变化。当数据规模足够大时,我们可以这么做,两组数据让它们的 X 能做 Absolute Matching。
但这个方法的要求显然太高了,我们无疑找不到到两组只有一个 feature 不同的数据,所以我们需要对这个方法进行放松,由此而来的一个比较常用的做法就是 Confounder Balancing,也就是说虽然我们可能找不到这样两组数据让它们的 X 一样,但是我们可以对样本进行加权,通过对采样数据的样本进行加权,使得加权以后的它们在 X 上的 Distribution 是一样的。这是能做到的,极端情况下样本的权重都变成零,那不就一样了吗?当然这是一个 trivial solution,那就是说在 nontrivial solution 里,我们能否找到这样一组权重使得此二者的 Distribution 相同。

在这样的思路引导下,一系列 Confounder Balancing 的方法相继被提出。但事实上,我们的目标并不是做 Causal Inference,而是如何把 Causality 引到 Learning 里面来。但这个问题又需要用到太多参数,实操起来绝非易事。所以我们就想沿着这个方法能不能再进一步放松,于是便有了 Global Balancing:
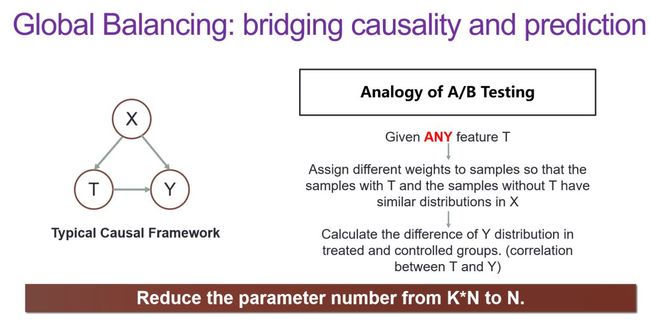
所谓 Global Balancing,就是希望找到一组权重,使得给定任意的 T,都能去 balance 剩下的这些 X——即希望找到一组权重,给定任意 feature 后,其他 feature 在这组权重下的 Distribution 都能够达到一个比较好的平衡。这个要求看起来很高,但在样本数据量足够大的情况下,理论上还是可以找到的。如果存在这样的一组权重,它可以平衡所有的 T,那整个优化问题、学习问题,实际上只需要对每一个样本学一个权重就可以,这个参数量还是可以忍受的,也就是 N。
以上就是我们研究的核心想法,在研究过程中我们首先从理论上证明了,当这里的 N 趋近于无穷时,我们的确存在这样一组样本权重,它使得对于任意的 T,剩下的 X 的分布都会被平衡住。而有了这样一个权重以后,我们就希望能够通过这种 Global Balancing 的方式把这组权重学出来,从而相当于在做机器学习时多了一个维度,我们可以把这个权重套到各种学习模型上去,像是 Reweighted Logistic Loss;我们后来又把这套思想和 Autoencoder 的框架做了一个嫁接;今年又尝试将 weighted sample 的思想套到 CNN 结构中去……
为了支撑这项研究工作,我们最近做了一个数据集,叫做 NICO:

该数据集和 ImageNet 最大的区别就在于每一类图像被分成了 10 个 contexts,每一个 context 下面大概都有一千多张 image,希望借此来探究一个环境下训练出来的数据是否能够被应用到其他环境下,其稳定性又是否能够被控制。
从 NI 指标的角度来看,ImageNet 大概在 2~2.5,如果通过对其 bias 进行一定的控制,则可以达到 5~5.5,乃至 6 ,也就是说提供了一个可以让大家尝试不同程度 Non-IID 的 Image Dataset。只有能在这个 Dataset 上取得 stable performance,才能说明这是个可靠的模型。

于是我们就测试了自己的方法,如上图所示,柱形表示的是该 category 下其 Non-IID 的程度;曲线描述的是我们的方法相对于 Correlation bias 方法的 improvement 程度,此处可以看到还是存在一个共振的。然后我们在不同的模拟数据和 Distribution 下测试该模型的 performance 的稳定性,不难发现,较之传统方法,我们的模型在不同 Distribution 下的抖动并不大,较为稳定:
最后是关于 insights 的实验,就是弄清楚我们的模型所强调的 feature 与 Causalition 的区别。如下图所示,红框圈出的是我们的 highlighted feature,绿框则是 Causalition 方法的 highlighted feature。对比可以发现,除了在 Object 上,Causalition 还有很多会落到 Background 上面。但我们的方法在不做任何 Object Localization 的情况下,大部分 feature 都会落到 Object 上去,因此从这一层面来看,其具有支持可解释性的能力。


最后,现在谈及 Predictive Modeling,包括机器学习,我们可能都是以 Accuracy 为主,但这不应该是一个完全的 performance 追问的问题。Stability 和 Explainability 实际上非常重要,这让我们能够去信赖机器学习模型这样一个维度。我们现在正在尝试引入 Causality,事实证明这也确实能够解决一些问题,但是如何将 Causality 与预测模型有效地结合起来仍然是一个需要更多人加入进来共同探索的问题。
2
唐平中:AI≠机器学习,源头上的人工智能讲的是什么?
清华大学交叉信息研究院长聘副教授、博士生导师唐平中本次的报告主题为《AI and Games》。讲解过程中,唐平中博士追根溯源,跳出“机器学习”问题本身,更上一层,阐述了 AI 自开蒙以来便持续关注的问题——AI 与博弈。

唐平中(清华大学)
现在大家总觉得 AI 就是机器学习,但遥想当年却又并非如此——80 年代 ,AI 的唯一目标就是要赢 checker;90 年代又想赢国际象棋,于是乎就有了 IBM 深蓝(Deep Blue),全无模式原理,只有大量的 Alpha-Beta Pruning 加 Tree search,忽得名 AI;去年又转战德州扑克,四个顶级德扑选手同 AI 三日对战,那个 AI 里也没有任何 Machine Learning,反倒拿下了 NIPS Best Paper……因此,我们首先得从 Machine Learning 往上跳一层,看看还有什么别的内容,先理解什么是 AI,比如 AI 从最初的起点一路走来,一直在关心的事情就是“paly games”——我们关注的领域也就是 AI and Games。
何为博弈?对于这个问题,不同人自有不同的定义,经济学里玩的是所谓的囚徒困境(prisoner's dilemma),每个人有两个 dilemma;AI 领域研究的是一类很复杂的博弈,定义为“Decision making by multiple, selfish agents”。我们在传统 AI 中关注的是 Single-agnet decision making,翻译一下就是,大脑先获得一些信息,然后预测,继而决策,例如明天是否要带伞的问题。除此之外,目前还存在一类新问题,叫做 Multi-agent decision making。事实上,这类问题早在一些经济学场景中出现过,指的是我们现在做决策,除却环境信息、个人看法等因素之外,还很大程度上受到对手决策的影响,类似股市行情的涨跌,乃至现阶段的中美贸易战。换言之,我们不仅要考虑自身看法、自身信息以及环境信息,还需要预测对手可能会有的做法,这其实也是传统 AI 研究中惯常被忽略的问题。
相较而言,传统博弈研究处于非常标准且简化的环境下;如今的博弈却又很是复杂(例如 Dota),我们如何在其上做出好的决策就成了个不容回避的问题。以德州扑克为例,一桌六七个人,每个人都有极其复杂的 action space,对于对手下一步操作的预测就很不明晰。假设对手此前一直选择弃牌(fold),但当其遇上一波好牌,不再弃牌时,我们根本无法预测。如果 past data 显示该对手在过去 50 轮当中都不敢 All in,那么我们据此得出的第 51 轮预测肯定也是如此,但其若突然改变路数瞬间翻盘,我们对此也是全无应对策略。著名华人扑克职业选手邱芳全(David Chiu)就曾在一次国际德州扑克决赛中上演过这样一出扑克史上经典的“弃牌”牌局。
因此,所谓的“预测”在这样的环境中可以说是无甚意义,那么遇到类似情况我们又当如何决策呢?这个问题的本质其实就是“博弈”——我们需要对博弈进行建模,并在该博弈上搜寻其 Optimal Strategy(最优策略)。

博弈研究有三类经典问题:
1. 建模。即对于当前的环境,应该选用一个什么样的数学模型;
2. 预测和处方。How rational agents should behave,即 predict 和 prescribe,前者为预测对手的 action;后者则类似医生开处方,意思是“我觉得你应该这么玩,我教你这么玩”。“会怎么玩”和“应该怎么玩”,这里是两个不同的概念;
3. 设计。即在知道下面有一堆非常聪明的 agent 之后,我们要怎样设计一个 Game 给他们玩,当然我们希望通过这个设计来达到自己的目的,比如广告拍卖,面对极为机智的广告主,我们要如何从中获得最高收益。
除此之外,从 AI 的角度来看,现今的 AI 和博弈有两个主要赛道。第一个赛道相对初级但也很重要,谈的是怎样去玩一个博弈,也就是 How to compute a solution concept。

在这个问题上,如果看经济学方面的书,去了解纳什定理,它也只会告诉我们任何一个博弈都存在纳什均衡(Nash equilibrium)这么一个陈述,并没有给出算法,我们仍旧不知道如何去算。因此,这显然是一个计算机科学问题,本质就是一个 AI 算法问题。
事实上,John Von Neumann(冯·诺依曼)早在 1928 年就曾提出,所有 zero-sum game 都有一个 Polynomial time,这是一种线性规划。因此在 zero-sum game 中,这是个线性规划就能解决的多项式算法。但是在 general sum game 里,例如中美贸易战,这不属于 theory game 的范畴,双方既有竞争也有共赢。那么在这类博弈中,若要计算其纳什均衡,复杂程度无疑极高,这个问题直到 2006 年才得到解决(PPAD hard)。
在这一领域,大家也相继进行了一番探索,下图便涉及到了 Scinece 2015的一篇 paper,研究了德扑的玩法:

假设现在牌桌上有两个人,每个人都拿出一个亿来赌,此时的 Original 里有一个巨大的 Game,其叶子结点个数多达 10 的 161 次方,所以首先第一步要进行抽象化(Abstraction),从而得到一个更简单的 representation,也就是把胜率相同的叶子结点组合起来,将其缩成一个小的 Game。这个小 Game 有可能和之前不一样,但其实几乎近似于(almost approximate)该初始 Game,然后我们对这个 Game 进行求解。
总体而言,这个方法解决了两个问题:一是将一个大的 Game 通过一些输出结果上的等价性进行抽象缩小,这也是 large extnesive-form games 上的一个最重要的研究领域。以围棋为例,我们现在有非常多的 situation,那么能否把这些 situation 组合到一个很抽象的 situation 上用于统一决策。在围棋问题上,AlphaGo 目前的成功大家有目共睹,但其据离纳什均衡差得还太远,也就是说我们完全有可能把围棋这个博弈的纳什均衡用 Go 给做出来,然后每一盘都碾压 AlphaGo。但在德扑上做不到这一点,在德扑上我们没办法用 CMU 的 agent,因为它已经把 Nash equilibrium 算出来,而,依据冯·诺依曼的定理,在 zero -sum game 上玩纳什均衡是不可能输的,以上就是围棋和德扑最本质的区别。
现在两人德扑问题解决了,但新问题在于如果不是“two player”模式,而是“six player”,这个 Game 更大了的话,又该如何处理?此时冯·诺依曼的定理已然失效,在双人局里的必胜法门纳什均衡也失去了保障。
上述两个问题都需要从本质上加以分析,通过 Learning 的办法,学习一个好策略,或者通过 Search 找到一个 Optimal Strategy,这是两个完全不同的路子——围棋适用于前者,德扑适用于后者。与此同时,德扑的研究领域也非常大,很多人在做 large extensive-form game,其在军事领域的应用算是非常重要的场景。

还有一个问题叫做 Computing Stackelberg equilibrium:假设现在你我双方玩一个博弈,我有两种策略,一种策略是你先动我来跟,一种是我方先采取行动。换言之,Stackelberg equilibrium 讨论的就是我是“领动者”,还是“跟随者”的问题——到底应该 commit to a strategy,还是选择 best response。举个简单的例子,比如一个机场有 10 个门,但是只有 5 个警察,每个门后面保护的东西也可能不一样,我们随机做一些案件,包含国际航班和国内航班,守卫的价值也各有差异,那么该如何分配警力进行巡逻?之前惯用的做法是,不告知分配计划,随机出现在一些场合然后搜查,当然恐怖分子看到巡逻之后,会自然生成 best response,这是一种做法。还有一种做法是事先告知我是警力分配,让恐怖分子来观察警方。
到底这两种做法哪个更好?大家的直观反映通常都会更倾向于第一种,但理论却证明第二种方法更优,但需要用到随机化原则(randomization),依据随机策略告知各个门概率,这本质上也是 AI and Games 的问题,是警方和恐怖分子间的博弈,警方在 lead 和 follow 间抉择,应该选择 lead。
当然最近我们看到最多的还是 Learning in games,就是在一些大的博弈中,我们没有办法精确算出最优策略,能够暴力求解 Optimal Strategy 的案例实属罕见(例如双人德扑、国际象棋),但在一些人、机双方都玩得比较差的情况下,机器通常会选择 Learning in games,即“Optimize strategies using self-play or past interactions”,其中便包括围棋的案例,这实际上是一件耗费巨大的工作,Facebook 田渊栋为了复现 Alpha-zero 便投入颇多。
前段时间有新闻报道称,Dota2 世界冠军 OG 输给了 OpenAI;人工智能在星际方面也取得了一定的进展。但是这里最大的挑战还是六人德扑——“Large extensive-form game with incomplete information”一直都是一个主要赛道,其挑战在于:① 该博弈远大于二人;② 我们不知道到底要算一个什么样的策略,首先纳什均衡已经不适用了,所以肯定要先由 AI 学者提出一个目标,然后将其具现化,相关研究成果无疑是对博弈和 AI 这一交叉学科的贡献。这是一个非常实际的问题,涉及理论和实践两个方面,关键的讨论点在于,当对手在玩自己的 policy 时,我们应当如何击败其 policy。
Multi-agent Reinforcement Learning 会有一些 solution,比如我现在有几个红球、几个绿球,绿球想逃避,红球想追逐,那红球之间能不能生出一些比较合理的策略?像是 MADDPG 就是一种 solution,它通过一些比较好的强化学习算法,能够在一个非常小的局域内,使两红球间形成协作(collaboration),这是做得好的地方,但也有不足之处,问题就在于没有一个具体的评估标准,策略的好坏很难界定。如果基于绿球的策略达到“最佳响应”,红球的 reward 又可能会随之减少——我们在定义 Strategy 或是 Policy 的好坏程度时,是红绿球成对评判的。这一系列问题的最大应用场景依旧是在军事领域,例如怎样做好 Autonomous team combat,最终也都归结到 Large extensive-form game 问题。
第二个赛道是做 Mechanism design:假设现在有一群非常聪明的人,都很擅长玩某个 Game,但我们研究的不是如何玩这个 Game,而是设计一个 Game 给大家玩,从而达到自己的目的。Mechanism design 是一个非常传统的经济学问题,在微观经济学中算是个颇为重要的课题。1994 年、2004 年、2007 年,2012 年的诺贝尔奖得主,研究的都是关于 Mechanism design 的内容,其中最重要的主流应用就是 Internet advertising auctions——如何在互联网卖广告。事实上,所有的互联网公司都是广告公司,怎样设计拍卖让大家竞价可谓是一个躲不过的主题。

那么这里“设计”的到底是什么?以卖苹果为例,在未知买家估值的情况下,如何卖出商品,使收益最大化?问题的难度一在怎么卖单个苹果,这个问题的解决对应了 2007 年的诺贝尔奖;再者是当商品数量为两个以上时,要如何最大化收益,这个问题至今悬而未决,在理论层面还有待突破,当然我们对此也取得了一系列进展,其中便包括图灵奖得主姚期智于 2013~2017 这四年间的研究。其于 2015 年发布的论文当属该领域的最优结果,其通过研究找到了多人多商品最优拍卖的一个常数近似,就是我们总是能够得到最优结果的一个常数分之一,例如常数近似为 2 approximation 的话,就能得到最优收益(revenue)的一半,这是一个非常重要理论的结果。此外,我们在一些具体场景上也做了诸多工作,也在 EC 大会(ACM Conference on Economics and Computation)上,发表了一系列文章,阐述了如何在一些特殊场景下,寻找最优拍卖方式。

以具体的广告合作为例,本质上是在最优拍卖一堆参数,包括排序、价格等。我们在这里做了一些比较大胆的尝试——用 AI 来使之最优化,这不是一个单纯的 Machine Learning 问题,还是一个行为经济学问题,因为我们还需要对对方的行为进行预测,本质上是 approximate function,也就是从广告主对过去收益等的观察,到其明天出价的一个映射,我们在预测其策略。我们先利用神经网络对广告主的行为进行建模,然后通过 Reinforcement Learning 的办法来最优化广告位参数(比如每个人的保留价是多少,每个人权重多少),接着再通过强化学习以及行为经济学建模来对大平台的核心指标进行优化。
另外,还有一个更加面向社会的问题也非常重要,那就是 Kidney Exchange,相关研究成果同时也获得了 2012 年的诺贝尔奖:
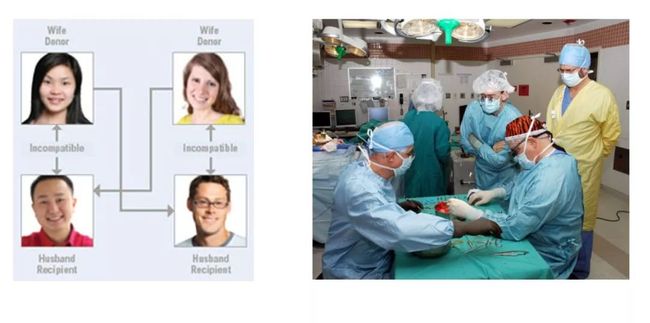
假设现在有一位肾病患者,在中国没有别的办法,只有等待亲人捐助,以及守着很长的 Waiting List 等待肾源这两个途径。对此,美国提出了一个新方法,就是当患者的亲人不符合捐赠配型时,可以选择进入一个名为“Kidney Exchange”的 Database,相当于患者和待捐赠亲属一同进入一个市场,然后在这里重新匹配到合适的肾源,但前提是该患者的捐赠者也要把肾捐给别人,具体情况如上图所示,形成了一个 cycle。
虽然这个问题看起来就只是数据库里找匹配的小事,却也依旧难处多多,其一便是当涉及 6 个人时,就会变得极其难算,即 NP-Hard to approximate 问题。随着患者和捐赠者数量的攀升,其在算法上会变得非常难,很难厘清所谓的“最优解”;再者,这个系统中还包括一些特殊情况,例如难于匹配的血型、病危患者等,面对这些问题,我们又要怎样将这些特殊因素考虑在内;与此同时,还涉及 Dynamic System 的问题,即随着新人员的加入,原本匹配的最优解极有可能被打破,因此就需要做到动态匹配,这就又牵扯到很多算法、预测、学习乃至经济学方面的问题。
我们在该领域也进行了大量研究,第一次我们提出了一个肺交换的算法,以前肺交换是没有算法的,但是我们提出一个肺交换的机制。我们还考虑到了肾脏交换的稳定性,这是个纯算法问题,指的是在考虑到 Global Optimality 的同时,还要考虑到每个人的 incentive,这也是个非常有趣的问题。
最后再来总结一下上文提到的两个赛道,第一个赛道是计算最优策略,对于一个很重要的博弈,比如围棋、德扑等,要如何算出其最优策略,我们从Learning、Tree Search、Abstraction 等角度出发提出了解决办法;另外一个赛道就是如何设计博弈,以达到自身目标,最大化收益。
3
黄高:突破静态模型计算思路,自适应推理可能是神经网络的未来发展趋势
本次论坛最后,由清华大学自动化系助理教授、博士生导师黄高博士为大家带来了《面向快速推理的神经网络结构》主题分享,从 DneseNet 的提出动机及优势、深度卷积神经网络的历史进展,以及自适应神经网络这三方面着手,探讨了这个有关深度学习的话题。

黄高(清华大学)
Dense Connectivity
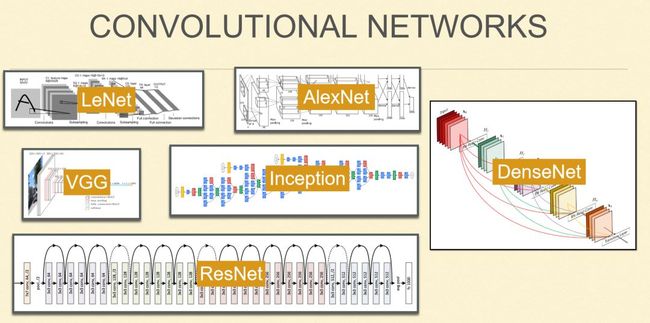
众所周知,深度学习在过去几年取得很大进展,各种各样的网络模型迭出,在深度学习背后做出了非常大的贡献,其中不乏一些比较典型的网络结构。
LeNet 模型最早于 90 年代经由Yann LeCun提出,是第一个能够商业化的深度学习模型,更是获得了今年的图灵奖;AlexNet 诞生于深度学习爆发的 2012 年,彼时曾通过这个模型在 ImageNet 数据集上,以超过第二名将近 10 个点的巨大优势,夺得当年竞赛的冠军,也是让深度学习广泛被计算机视觉以及机器学习学者所接受的里程碑式成就;2014 年,牛津大学提出 VGG,Google 随后亦提出了 Inception 模型;2015 年,MSRA 提出 ResNet,该结构在网络上实现了一个很巧妙的改动,通过跳层连接可以让我们把深度学习真正做得很深,模型真正做到 100 层以上;2016 年,我们开始投入研究 DenseNet,后于 2017 年发布相关工作。
事实上,提出 DneseNet 背后的动因是受到 ResNet 的启发。在传统卷积神经网络模型中,一层一层的结构随着愈加深入,优化起来会变得很困难。因为基于梯度法,需要一层一层往前传,先算前项的 prediction,然后通过反向传播、反向计算,再一层一层传回来,所以当网络层数比较多的时候,信号就极有可能消失,梯度等于零,这个网络也就没办法训练了。
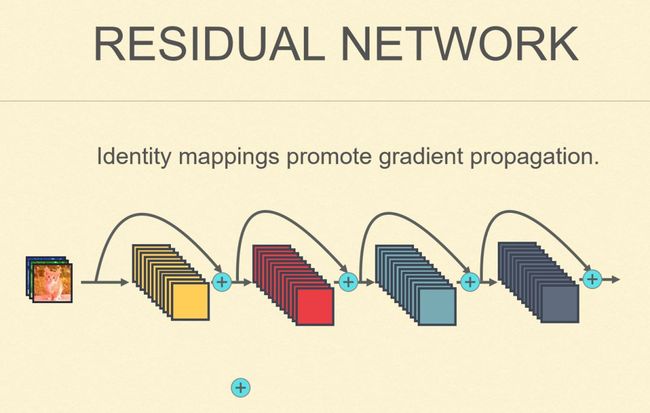
为了解决这个困难,当时微软研究院的研究员何海明及其合作者提出了 ResNet 的概念,在每一层上加一个跳层连接,所谓的跳层连接其实就是一个单位映射。较之原本的非线性映射(可以理解成矩阵运算),单位映射不管乘多少次都是 1,巧妙规避了梯度消失的问题。虽然跳层连接在网络里看起来就是一条连边,但其实大部分信号都是在单位映射,也就是在上面这个路径上传播(见上图),所以这样的网络变得比较稳定。从而能够训到很深的模型。
后来我们又在此基础上做了一个很有意思的小改进,因为我们在训练这个模型的时候,通常会用随机梯度法,每次都要求梯度,然后做迭代,于是我们引入一个残差单元,也就是一个非线性映射加上一个单位映射,给它分配一枚硬币,然后在每次做随机梯度法的时候,都把这些硬币随机掷一次。然后将对应反面的这些残差单元的非线性映射扔掉,剩下单位映射,单位映射其实就是把输入拷贝到输出,所以这也就等价于一个更浅的网络,再在其上进行前向计算和反向计算,然后去跟进这个网络的参数。
随着网络变浅,计算量自然也变小了,优化起来梯度消失的情况也会随之减弱,这是在一次迭代。因为我们做 SGD 可能有上百万次迭代,所以我们在另一次迭代时,又随机掷一次硬币,然后再随机扔掉一些非线性映射。所以在训练过程中,每一次迭代时我们都有可能随机选择一些非线性映射扔掉。网络在训练时,其深度在随机变化,所以我们把这个算法叫做随机深度。
备注:但是测试的时候我们把所有单元都用上了,因为如果我们在测试时仍选择扔掉一些的话,其 performance 就会受影响的。这我们在训练 ResNet 时做的一个微小的改动,但是可以看到一个非常大的提升。
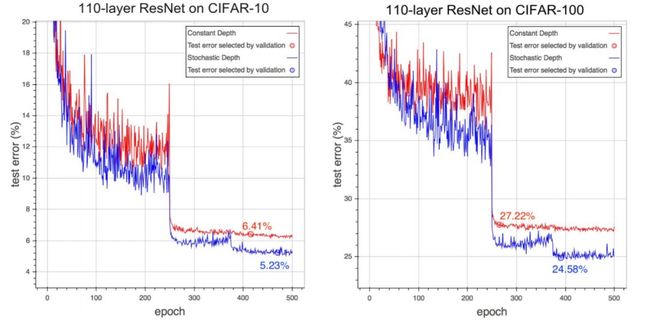
例如在两个 CIFAR 图像识别数据集上,红色是标准的 ResNet 模型,我们把那个随机深度网络用上去,纵轴是测试误差,如上图所示,蓝色曲线比红色曲线大概要高超 10%。
这个算法非常简单,但是给我们带来了一些很重要启示,其中很重要的一点就是提升了网络的鲁棒性。原本随着网络变得很深,每层做的事情就发生了变化,如果想把中间某一层扔掉,那前一层的特征就传到后面去了,每一层得到的特征都从它紧邻的上一层来。在这种情况下,如果是一个串型网络,且中间某一层学了一些不好的特征,那么后面所有层都可能会受到影响。而现在我们加入这样一种机制,使得训练时可以直接拿掉某些层,并且不干扰网络的正常训练,这就说明该网络不会过度依赖其中某一层或两层,更为鲁棒。另外就是把网络变浅,可以创造很多短路径,从未为其优化创造优势。
与此同时,这也证明了我们的网络都是冗余的,因为训练时抽掉一些层后,网络仍然可以正常训练,其预测也不会产生变化。换言之,当网络变深后,其冗余性也在增加,每一层学的信号都非常有限,本质上就是在学一个很小的残差。一方面,残差可能有助于提升鲁棒性;另一方面,其在实际应用中,却又会导致深度学习的计算量过大,而计算开销素来是深度学习方面一个比较令人头疼的问题,而为了将其应用到很多设备上,我们对其计算效率也提出了更高的要求。
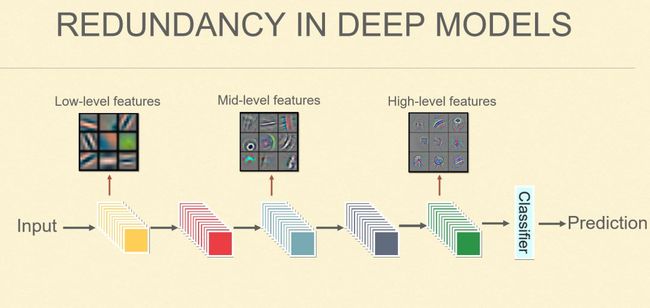
如上图所示,深度学习是从浅到深层的特征,浅层提取一些 low-level 的特征,例如颜色、纹理等;而相对比较 high-level 的特征则可能是一些比较抽象的特征,像是图像中有无眼睛、鼻子等,最后的 Classifier 建立在最为 high-level 的特征上。但其实对于某些样本,比如识别一匹斑马,我们的 prediction 其实更倾向于用到一些很浅层的特征,因为我们要将其同一匹马区分开来,就必须要用这种类似于颜色及纹理等的特征。而在这种网络中,此类特征需要一层一层地往后,最后才能传至 Classifier,通俗一点理解也就是说:这个特征我们在前两层就提到了,但是仍需要一层一层往后传,这个传递的过程不是零损耗的,仍需要一直会做运算,哪怕就是学一个和单位映射一样的变化,也要做一个很正式的矩阵运算。
既然网络需要做如此多冗余之事,每一层都要学几百上千个特征图,仰赖网络的宽度,才能保证我们的信号能够顺利地往后传。如果网络变得很窄,这个网络也就无法继续训练了。沿着这个思路分析,我们能否把网络变得窄一点,每一层就学自己的新特征,后面的网络如果需要用到前面的特征,就直接连过去——我们称之为 Dense Connectivity,直接把所有有用的特征,通过这种显式的连接,直接传到后面,而不需要隐式地在这个网络里面一层一层地往后传。如此一来,网络就会变得很精简,每一个类只学习需要学的一些新特征,并存到特征库中,网络后面的层需要用的时候,直接可以通过这些连边获得,从而得到一个非常 dense,但又非常高效的网络。

DenseNet 的想法其实很简单,很多人基本上一看到上面这张图就知道是怎么回事了,但同时也多会认为将网络变成密集连接方式之后,会导致计算量增加,因为我们的确在网络上增加了很多连边,再加之连边数是平方增长的,在视觉上不免给人带来“增加了很多计算量”的感觉。但其实恰恰相反,我们这个网络最大的特点就是能够节省计算量,这也是一大优势所在。原来的网络虽然看起来没有这么密集的连边,但是每一个连边都是很大的矩阵运算,每一层需要的计算量都非常大。而在 DenseNet 中,每一层需要的计算量其实非常少。详见其与 ResNet 这一经典的模型的对比数据:

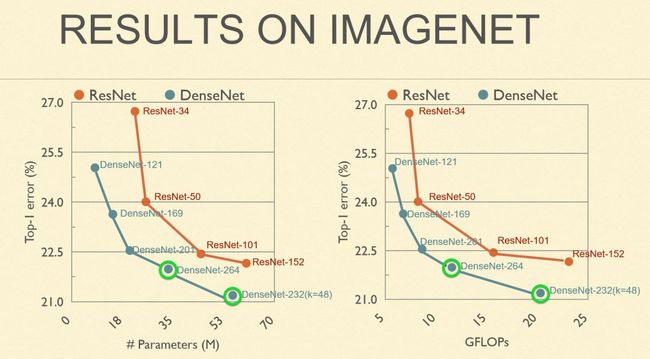
通过下图我们可以看到一个更直观的对比,这是一个错误率曲线,纵轴是错误率,横轴是参数量,右图对应的是计算量,蓝色点对应的是 5 个 Dense 模型。从中我们不难发现,在同等计算量下,DenseNet 模型可以精确度更高,错误率更低。或者说同样的 performance 下,DenseNet 模型可以做到小一倍左右:
近来优秀的网络结构
DenseNet 是我们 2017 年的主要工作内容,这之后在宏观网络结构设计方面其实还有很多不错进展,下面将进行一些简单的回顾:
1. Multi-Scale Networks

我们原本的网络都是一个串型的过程,就是从第一层往后传,从浅层到深层。但是现在有四项不同的工作,都在从不同的角度发现多尺度的网络,并在不同的问题上表现出很好的性能。所谓多尺度,横轴还是深度,但纵轴变为 skill/resolution。过去我们是过几层然后再下采样,现在则是立刻朝着纵轴方向做下采样,横轴沿着深度去增加其表达能力。
2. Neural Architecture Search

此前我们设计网络凭借的都是人类的经验和灵感,但其中还包含很多繁琐的工作,比如到底该用几层,每一层该用多少个节点,然后这些连边到底有多紧密等等,而这些很琐碎的事都可以交由算法来做,用机器学习本身来学这个模型,其本质是用一个网络来设计另一个网络。这从大的层面上来看,叫AutoML(自动机器学习),在结构方面叫 Neural Architecture Search,也是一个相当热门的研究方向。
3. Group Convolution
前面两点谈的都是宏观网络结构,一是设计多尺度网络,二是用机器自动做搜索。而在微观方面,更多关注的是网络的细节。卷积网络最重要的就是卷积操作,而卷积近年来也有很多变种,其中不乏非常有效的成果,比如非常典型的 Group Convolution。
Group Convolution 的想法很简单:原来的卷积是密集连接的,假设输入有 C 个通道,输出有 C 个通道,且任何两个通道之间都是相连的。而Group Convolution 就是把输入和输出分组,只有组与组之间才要连接,从而实现一种稀疏的连接(因为组之间就不会有连边了)。这种稀疏化的卷积的直接结果就是计算量的减少。
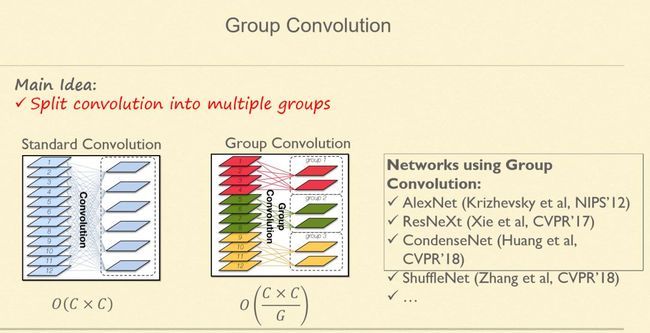
如果我们分成 G 个组,其计算量就是原来的 G 分之一。当然这在一定程度上也会导致性能的下降。但正如前文所述,卷积网络的冗余性其实很高,所以性能上的下降也相对比较少,而且其所带来的效率提升也是极为显著的,两相综合,计算效率自然得到了大幅度提升。最早的 AlexNet 用的正是这种想法,只是用得比较简单,就是两个 Group。再后来像是 ResNeXt、CondenseNet,以及现在面向手机端做的 ShuffleNet,都在使用 Group Convolution 这种结构。
4. Depth-wise Separable Convolution
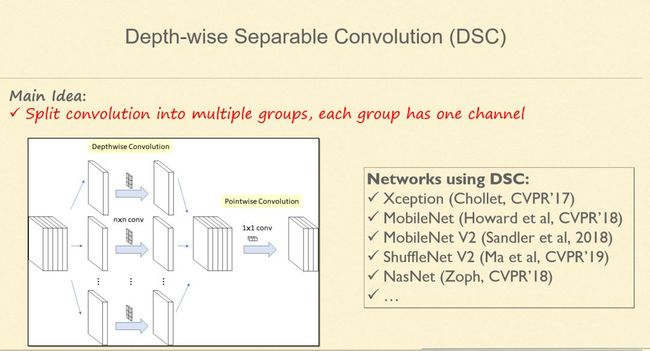
Group Convolution 做到极致就是 Depth-wise Separable Convolution。那么何为极致?就是每个 Group 只有一个通道,把卷积输入变成有多少个通道就分成多少个组,组与组之间有连边。这其实是现在做高效卷积神经网络一个比较标准的模块,特别是面向手机端做的深度学习应用,比较有代表性的案例有 MobileNet、ShuffleNet 等。
5. Squeeze and excitation network
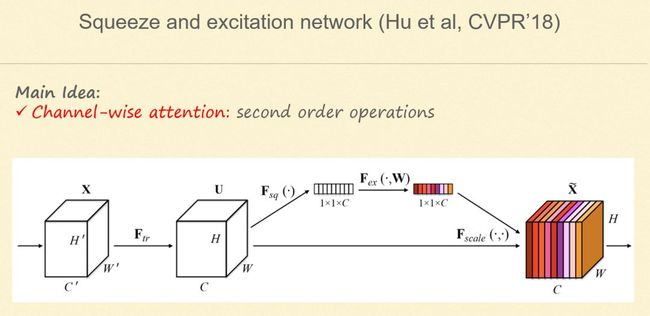
还有一个比较有意思的工作就是,我们在做卷积时,给其加上一个 Attention 机制,即通过学习通道之间的关系,调节特征图通道之间的权重,从而达到 Attention 集中的目的,改善网络的表达能力。
6. Dilated Convolution

卷积通常是在一个图片上逐行逐列地扫过去,其扫过的区域就是卷积的大小(比如 3×3 的卷积)。为了增加其感受野,提出了一种膨胀卷积(Dilated convolution),在获得更大的感受野之余,不会增加计算量。
7. Deformable convolution
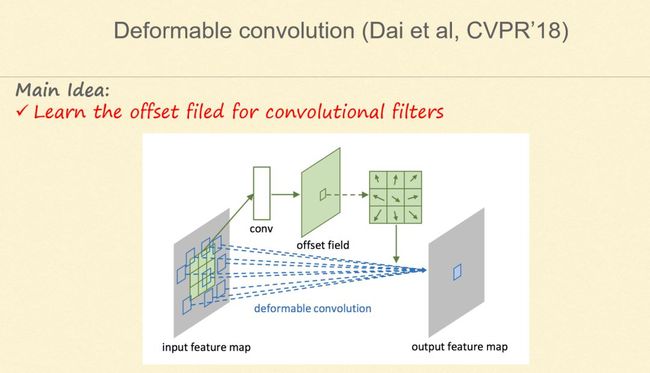
若将 Dilated Convolution 做得更巧妙一些,就是 Deformable Convolution,即不要求卷积扫的位置是个规整的矩形,其在做分类以及侦察方面相当有效。
……
自适应推理(Adaptive Inference)
深度学习在计算机视觉、语音识别、对抗博弈等领域展现出了巨大的应用潜力。在某些特定的任务上,深度神经网络的表现已经接近甚至超越了人类的水平。在性能不断提升的同时,深度学习模型的计算开销也在急剧增长。当前广泛应用的深度学习模型仍然是静态神经网络,即模型一旦被训练好,在推理时所使用的网络结构与参数都不再发生变化。这种静态计算模式在实际应用中会造成大量的冗余计算,增加系统的能耗和运行时间。
在这样的背景下,自适应推理既有可能成为未来的发展的方向。近年来不少研究都聚焦于提升神经网络的计算效率,例如前文提到的 MobileNet 模型、ShuffleNet 模型等,都在探索深度学习在小型化设备上的应用。此外,还有大量的研究致力于通过模型剪枝、参数量化等方式降低神经网络的计算开销。
自适应推理突破了静态模型计算的思路,实现了依赖于每个独立样本的动态计算,为提升深度模型的计算效率提供了全新的思路。这种自适应计算方式具有几个明显的优势:① 可以大幅减少神经网络中的冗余计算,在不损失模型精度的同时显著提升模型的效率;② 能够很好地兼容已有的模型小型化方法,充分吸收模型剪枝、参数量化、轻量化卷积、自动模型搜索等领域的最新成果;③ 能够使计算设备实时调整其计算负荷,以动态适应用户需求或者环境变化;④ 自适应计算使得深度学习的推理模式与人脑的感知模式变得更为接近,将可能在两者之间建立起新的桥梁,进而促进深度学习在可解释性、鲁棒性等方面的研究。
近几年,自适应推理在深度学习领域已经取得了初步的研究进展。但目前自适应计算仍具有较大的局限性:① 仅能处理分类等相对简单的任务;② 自适应方式较为单一,目前较为成熟的只有样本自适应模式;③ 理论方法不够成熟,启发式方法导致算法难以达到最优。
面对自适应推理的优势与瓶颈,黄高博士及其团队正在探索如何通过自适应推理提升深度学习模型的计算效率、动态适应性、鲁棒性以及可解释性。同时建立系统的自适应推理理论框架,并在自适应计算的背景下研究新的机器学习问题。
【相关阅读】
打破惯用范式,以数学与统计构建新一代人工智能方法论
穿越传统藩篱,当统计学闯入人工智能“后花园”
无数学不华为?人工智能时代的数学家还将走得更远
