聚簇索引和二级索引介绍
前言
本篇文章主要介绍聚簇索引和二级索引的区别,以及从存储结构出发怎样更有效地优化SQL。
一、索引介绍
1.目的
更快地查询到想要的数据
2.实现方式
在写数据(增、删、改)时动态维护指定的数据结构,每个数据结构都是一个索引;查询时根据某个数据结构来查询。
3.举个栗子
一本3000页的《三国演义》对应数据库的一张表,目录对应索引,内容对应表中的数据。
想要查看第21章的内容,不使用索引时,最坏的情况可能需要翻3000页。使用索引的话,只需翻开书的目录(目录可能占据5页),然后发现第21章在1689页,进而直接翻开1689页即可。
二、索引创建与查询
创建一张表,并插入5条数据
CREATE TABLE `person` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`age` int DEFAULT NULL,
PRIMARY KEY (`id`)
);
INSERT INTO `person`(`id`, `name`, `age`) VALUES (1, 'Jack', 12);
INSERT INTO `person`(`id`, `name`, `age`) VALUES (2, 'Bob', 13);
INSERT INTO `person`(`id`, `name`, `age`) VALUES (3, 'Jession', 11);
INSERT INTO `person`(`id`, `name`, `age`) VALUES (4, 'Lisa', 14);
INSERT INTO `person`(`id`, `name`, `age`) VALUES (5, 'Haro', 16);
1. 聚簇索引
每张表都有对应的聚簇索引,MySQL优先按主键建立聚簇索引;如果你没有指定主键,使用唯一键;如果连唯一键也没有,mysql会自动建一个rowid字段,用它来组织这棵 B+树
按主键建立聚簇索引,存储结构如图所示:
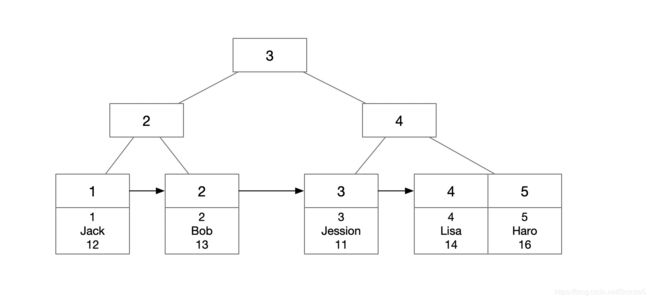
聚簇索引的叶子节点包含数据行,id大于3的数据放在右边,小于3的数据放在左边。
如果各位想了解这棵树是怎么构造起来的,可以参考构造B+树网站,自己手动构造下。
查询
select * from person where id = 5;
此时MySQL就会使用聚簇索引查询,依次查询到3-4-5,此时就能直接获取到id=5的数据。
2. 二级索引
-- 创建普通索引
CREATE INDEX idx_name ON person (name);
创建二级索引,存储结构如图所示:
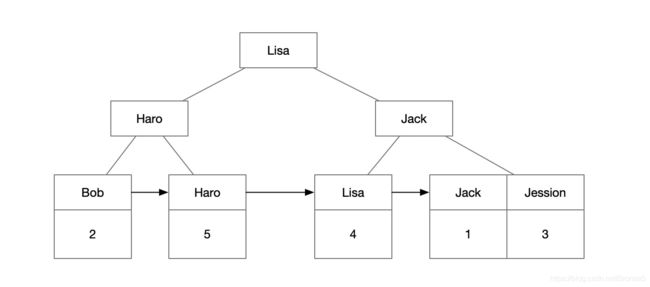
可以看到,二级索引的叶子节点存储的是主键值。
查询
select * from person where name = 'Jack';
这样的查询会经过两个步骤,
1. 先在二级索引的B+树中查到Jack对应的主键id值为1;
2. 然后拿主键id值,去聚簇索引中查询真正的数据。
三、SQL优化思路
1. 磁盘
- 不要建立太多索引,这样会建立很多B+树,很占磁盘容量。
- 一个索引中的字段不要太多,否则树中的每个节点都很大。
2. 写操作
- 尽量少创建无用的索引。因为每个写操作执行时,都会更新所有索引对应的B+树。
3. 查询
- 尽量不要使用select * 。如果select 后面的字段都是二级索引中的字段,MySQL就不会再去聚簇索引中查找完整数据了。
四、总结
聚簇索引
- B+树的数据结构,叶子节点包含
完整的数据行。 - 每张表都有自己的聚簇索引。
二级索引
- B+树的数据结构,叶子节点
仅包含数据的主键。 - 用户每创建一个索引,就会生成一颗B+树。
- 使用二级索引查询完整数据行时,会执行两个步骤:先查二级索引,然后再查聚簇索引。