基于JetCache整合实现一级、二级缓存方案(前置基础知识与原理)

目录
一、场景需求描述
1.1 一二级缓存技术需求背景
1.2 缓存需求说明
1.2.1 需求一
1.2.2 需求二
1.2.3 需求三
1.2.4 需求四
二、 缓存技术方案选择
2.1 技术方案选型思考点
2.1.1 如何保证分布式缓存一级缓存节点的数据一致性
2.1.2 一级缓存过期如何清除
2.1.3 一级缓存的过期策略的考虑
2.2 最终技术选型
2.3 一二级缓存工作流程图
三、技术框架介绍
3.1 Caffeine
3.1.1 简介
3.1.2 写入缓存策略
3.1.3 缓存值清理策略
3.1.4 统计
3.1.5 高效的缓存淘汰算法
3.2 JetCache
3.2.1 简介
3.2.2 使用要求
3.2.3 Redis远程缓存支持
3.2.3.1 spring boot环境下的jedis支持
3.2.3.2 spring boot环境下的lettuce支持
3.2.3 内存缓存支持
3.2.3.1 LinkedHashMapCache
3.2.3.2 CaffeineCache
3.2.4 监控
3.3 Redis
四、缓存扩展需求实现涉及的知识点
4.1 ORM中间件二级缓存扩展
4.1.1 JPA Hibernate缓存扩展
4.1.1.1 Hibernate缓存介绍
4.1.1.1.1 一级缓存
4.1.1.1.2 二级缓存
4.1.1.1.2.1 二级缓存过程
4.1.1.2 Hibernate二级缓存扩展点说明
4.1.1.2.1 RegionFactory
4.1.1.2.2 DomainDataStorageAccess
4.1.1.2.3 RegionFactoryTemplate
4.1.2 Mybatis 二级缓存扩展
4.1.2.1 Mybatis缓存介绍
4.1.2.1.1 一级缓存
4.1.2.1.2 二级缓存
4.1.2.2 Mybatis缓存扩展点说明
4.1.2.2.1 Cache接口
4.2 Sprig Cache 缓存扩展
4.2.1 Spring Cache简介
4.2.2 扩展接口源码分析
4.2.2.1 Cache
4.2.2.2 CacheManager
4.2.3 常用注解说明
4.2.3.1 @Cacheable
4.2.3.2 @CacheEvict
4.2.3.3 @CachePut
4.2.3.4 @Caching
一、场景需求描述
1.1 一二级缓存技术需求背景
我们知道关系数据库(MySQL)数据最终存储在磁盘上,如果每次都从数据库里去读取,会因为磁盘本身的IO影响读取速度,所以就有了像Redis这种的内存缓存。
通过内存缓存确实能够很大程度的提高查询速度,但如果同一查询并发量非常的大,频繁的查询Redis,也会有明显的网络IO上的消耗,那我们针对这种查询非常频繁的数据(热点key),我们是不是可以考虑存到应用内缓存,如:Caffeine。
当应用内缓存有符合条件的数据时,就可以直接使用,而不用通过网络到redis中去获取,这样就形成了两级缓存。
应用内缓存叫做一级缓存,远程缓存(如Redis)叫做二级缓存。以上是选择做一级缓存、二级缓存相结合的缓存方案的初衷。
1.2 缓存需求说明
1.2.1 需求一
基于JetCache实现Caffeine一级缓存、Redis二级缓存等整合。
1.2.2 需求二
基于JPA Hibernate,扩展Hibernate的二级缓存。通过接入本方案实现对Hibernate二级缓存的实现。
1.2.3 需求三
基于JPA,实现对Mybatis-plus的二级缓存扩展。通过接入本方案实现对Mybatis-plus二级缓存的实现。
1.2.4 需求四
Spring Cache 缓存扩展。通过接入本方案实现对Spring Cache缓存的扩展实现。
二、 缓存技术方案选择
2.1 技术方案选型思考点
2.1.1 如何保证分布式缓存一级缓存节点的数据一致性
我们说一级缓存是应用内缓存,那么当你的项目部署在多个节点的时候,如何保证当你对某个key进行修改删除操作时,使其它节点的一级缓存一致呢?
2.1.2 一级缓存过期如何清除
我们说redis作为二级缓存,我们有它的缓存过期策略(定时、定期、惰性),那你的一级缓存呢,过期如何清除呢?
2.1.3 一级缓存的过期策略的考虑
我们说Redis作为二级缓存,Redis是淘汰策略来管理的。具体可参考Redis的8种淘汰策略。那你的一级缓存策略呢?就好比你设置一级缓存数量最大为5000个,那当第5001个进来的时候,你是怎么处理呢?是直接不保存,还是说自定义LRU或者LFU算法去淘汰之前的数据?
2.2 最终技术选型
以上这些问题,都是我们一级缓存面临的问题,通过市场技术调研,我们发现阿里开发的JetCache框架,对以上问题有很好的解决方案,所以就选型了JetCache作为一二级缓存的整合框架。
一级缓存技术(进程级):Caffeine
二级缓存技术(远程分布式级):Redis
一二级缓存整合框架:JetCache
2.3 一二级缓存工作流程图
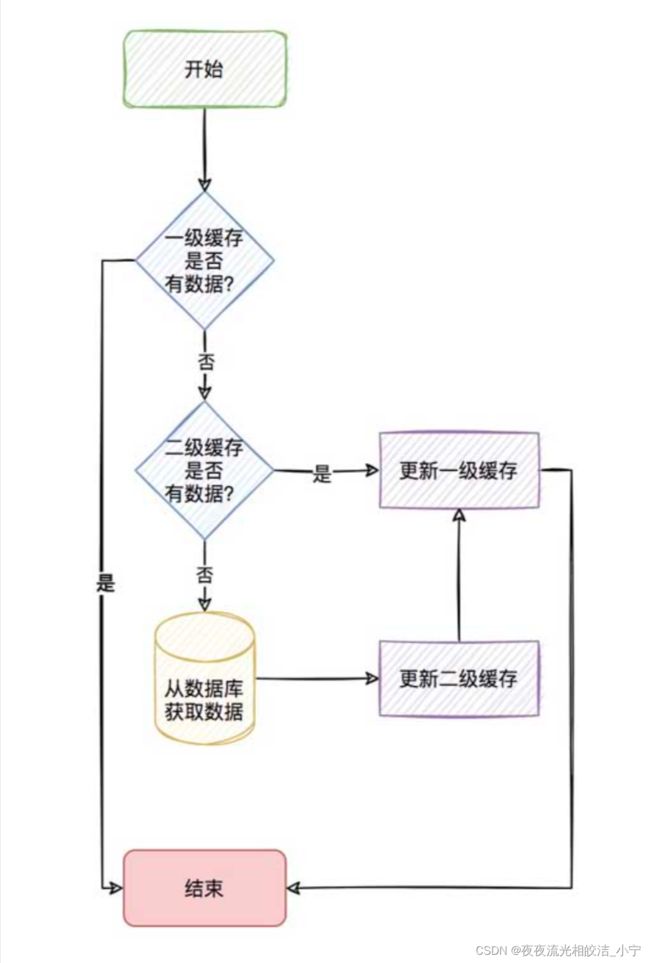
三、技术框架介绍
3.1 Caffeine
3.1.1 简介
Caffeine是基于Java 1.8的高性能本地缓存库,由Guava改进而来,而且在Spring5开始的默认缓存实现就将Caffeine代替原来的Google Guava,官方说明指出,其缓存命中率已经接近最优值。
实际上Caffeine这样的本地缓存和ConcurrentMap很像,即支持并发,并且支持O(1)时间复杂度的数据存取。二者的主要区别在于:
- ConcurrentMap将存储所有存入的数据,直到你显式将其移除;
- Caffeine将通过给定的配置,自动移除“不常用”的数据,以保持内存的合理占用。
因此,一种更好的理解方式是: Cache是一种带有存储和移除策略的Map 。
Caffeine 官网:GitHub - ben-manes/caffeine: A high performance caching library for Java
3.1.2 写入缓存策略
Caffeine有三种缓存写入策略:手动、同步加载和 异步加载。
3.1.3 缓存值清理策略
Caffeine有三种缓存值的清理策略:基于大小、基于时间和 基于引用。
基于容量:当缓存大小超过配置的大小限制时会发生回收。
基于时间:
- 写入后到期策略。
- 访问后过期策略。
- 到期时间由 Expiry 实现独自计算。
基于引用:启用基于缓存键值的垃圾回收。
- Java种有四种引用:强引用,软引用,弱引用和虚引用,caffeine可以将值封装成弱引用或软引用。
- 软引用:如果一个对象只具有软引用,则内存空间足够,垃圾回收器就不会回收它;如果内存空间不足了,就会回收这些对象的内存。
- 弱引用:在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。
3.1.4 统计
Caffeine提供了一种记录缓存使用统计信息的方法,可以实时监控缓存当前的状态,以评估缓存的健康程度以及缓存命中率等,方便后续调整参数。
3.1.5 高效的缓存淘汰算法
缓存淘汰算法的作用是在有限的资源内,尽可能识别出哪些数据在短时间会被重复利用,从而提高缓存的命中率。常用的缓存淘汰算法有LRU、LFU、FIFO等。
FIFO:先进先出。选择最先进入的数据优先淘汰。
LRU:最近最少使用。选择最近最少使用的数据优先淘汰。
LFU:最不经常使用。选择在一段时间内被使用次数最少的数据优先淘汰。
LRU(Least Recently Used)算法认为最近访问过的数据将来被访问的几率也更高。
LRU通常使用链表来实现,如果数据添加或者被访问到则把数据移动到链表的头部,链表的头部为热数据,链表的尾部如冷数据,当数据满时,淘汰尾部的数据。
LFU(Least Frequently Used)算法根据数据的历史访问频率来淘汰数据,其核心思想是“如果数据过去被访问多次,那么将来被访问
的频率也更高”。根据LFU的思想,如果想要实现这个算法,需要额外的一套存储用来存每个元素的访问次数,会造成内存资源的浪费。
Caffeine采用了一种结合LRU、LFU优点的算法:W-TinyLFU,其特点:高命中率、低内存占用。
Caffeine的底层数据存储采用ConcurrentHashMap。因为Caffeine面向JDK8,在jdk8中ConcurrentHashMap增加了红黑树,在hash冲突严重时也能有良好的读性能。
3.2 JetCache
3.2.1 简介
JetCache是一个基于Java的缓存系统封装,提供统一的API和注解来简化缓存的使用。 JetCache提供了比SpringCache更加强大的注解,可以原生的支持TTL、两级缓存、分布式自动刷新,还提供了 `Cache`接口用于手工缓存操作。 当前有四个实现,`RedisCache`、`TairCache`(此部分未在github开源)、`CaffeineCache`(in memory)和一个简易的 `LinkedHashMapCache`(inmemory),要添加新的实现也是非常简单的。
全部特性:
- 通过统一的API访问Cache系统
- 通过注解实现声明式的方法缓存,支持TTL和两级缓存
- 通过注解创建并配置 `Cache`实例
- 针对所有 `Cache`实例和方法缓存的自动统计
- Key的生成策略和Value的序列化策略是可以配置的
- 分布式缓存自动刷新,分布式锁 (2.2+)
- 异步Cache API (2.2+,使用Redis的lettuce客户端时)
- Spring Boot支持
3.2.2 使用要求
JetCache需要JDK1.8、Spring Framework4.0.8以上版本。Spring Boot为可选,需要1.1.9以上版本。如果不使用注解(仅使用jetcache-core),Spring Framework也是可选的,此时使用方式与Guava/Caffeine cache类似。
3.2.3 Redis远程缓存支持
3.2.3.1 spring boot环境下的jedis支持
redis有多种java版本的客户端,JetCache2.2以前使用jedis客户端访问redis。
3.2.3.2 spring boot环境下的lettuce支持
从JetCache2.2版本开始,增加了对luttece客户端的支持,jetcache的luttece支持提供了异步操作和redis集群支持。
3.2.3 内存缓存支持
3.2.3.1 LinkedHashMapCache
LinkedHashMapCache是JetCache中实现的一个最简单的Cache,使用LinkedHashMap做LRU方式淘汰。
3.2.3.2 CaffeineCache
Caffeine是基于Java 1.8的高性能本地缓存库,由Guava改进而来,而且在Spring5开始的默认缓存实现就将Caffeine代替原来的Google Guava,官方说明指出,其缓存命中率已经接近最优值。
3.2.4 监控
当yml中的jetcache.statIntervalMinutes大于0时,通过@CreateCache和@Cached配置出来的Cache自带监控。JetCache会按指定的时间定期通过logger输出统计信息。

3.3 Redis
JetCache缓存框架中支持Redis 的Jedis和Lettuce客户端访问Redis,Redis本身是分布式远程字典服务,支持Key-Value类型的数据存储。
四、缓存扩展需求实现涉及的知识点
4.1 ORM中间件二级缓存扩展
4.1.1 JPA Hibernate缓存扩展
4.1.1.1 Hibernate缓存介绍
Hibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,它将POJO与数据库表建立映射关系,是一个全自动的ORM框架,Hibernate可以自动生成SQL语句,自动执行。
Hibernate官网:Hibernate ORM 5.6.15.Final User Guide
4.1.1.1.1 一级缓存
第一级别的缓存是Session级别的缓存,它是属于事务范围的缓存。这一级别的缓存由hibernate管理的,一般情况下无需进行干预;
当应用程序调用Session的save()、update()、saveOrUpdate()、get()或load(),以及调用查询接口的 list()、iterate()或filter()方法时,如果在Session缓存中还不存在相应的对象,Hibernate就会把该对象加入到第一级缓存中。
4.1.1.1.2 二级缓存
第二级别的缓存是SessionFactory级别的缓存,它是属于进程范围或集群范围的缓存。这一级别的缓存可以进行配置和更改,并且可以动态加载和卸载。 Hibernate还为查询结果提供了一个查询缓存,它依赖于第二级缓存。
4.1.1.1.2.1 二级缓存过程
1) 条件查询的时候,总是发出一条select * from table_name where …. (选择所有字段)这样的SQL语句查询数据库,一次获得所有的数据对象。
2) 把获得的所有数据对象根据ID放入到第二级缓存中。
3) 当Hibernate根据ID访问数据对象的时候,首先从Session一级缓存中查;查不到,如果配置了二级缓存,那么从二级缓存中查;查不到,再查询数据库,把结果按照ID放入到缓存。
4) 删除、更新、增加数据的时候,同时更新缓存。
4.1.1.2 Hibernate二级缓存扩展点说明
官网:(https://docs.jboss.org/hibernate/orm/5.6/userguide/html_single/Hibernate_User_Guide.html#caching-config)

4.1.1.2.1 RegionFactory
RegionFactory 是创建缓存的工厂,所有的缓存都是通过RegionFactory 来获取的,而RegionFactory 是在EnabledCaching构造方法中初始化的。
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by Fernflower decompiler)
//
package org.hibernate.cache.spi;
import java.util.Map;
import org.hibernate.boot.spi.SessionFactoryOptions;
import org.hibernate.cache.CacheException;
import org.hibernate.cache.cfg.spi.DomainDataRegionBuildingContext;
import org.hibernate.cache.cfg.spi.DomainDataRegionConfig;
import org.hibernate.cache.spi.access.AccessType;
import org.hibernate.engine.spi.SessionFactoryImplementor;
import org.hibernate.engine.spi.SharedSessionContractImplementor;
import org.hibernate.service.Service;
import org.hibernate.service.spi.Stoppable;
public interface RegionFactory extends Service, Stoppable {
String DEFAULT_QUERY_RESULTS_REGION_UNQUALIFIED_NAME = "default-query-results-region";
String DEFAULT_UPDATE_TIMESTAMPS_REGION_UNQUALIFIED_NAME = "default-update-timestamps-region";
// 初始化RegionFactory
void start(SessionFactoryOptions var1, Map var2) throws CacheException;
boolean isMinimalPutsEnabledByDefault();
// 获得缓存策略
AccessType getDefaultAccessType();
String qualify(String var1);
default CacheTransactionSynchronization createTransactionContext(SharedSessionContractImplementor session) {
return new StandardCacheTransactionSynchronization(this);
}
// 生成时间戳,用于时间戳缓存
long nextTimestamp();
default long getTimeout() {
return 60000L;
}
// 创建一个实体领域模型的Region,使用该对象来缓存实体,可以理解为实体缓存的holder
DomainDataRegion buildDomainDataRegion(DomainDataRegionConfig var1, DomainDataRegionBuildingContext var2);
// 创建查询缓存
QueryResultsRegion buildQueryResultsRegion(String var1, SessionFactoryImplementor var2);
// 创建时间戳缓存。时间戳缓存Region存放了对于查询结果相关的表进行插入, 更新或删除操作的时间戳。Hibernate 通过时间戳缓存Region来判断被缓存的查询结果是否过期
TimestampsRegion buildTimestampsRegion(String var1, SessionFactoryImplementor var2);
}
4.1.1.2.2 DomainDataStorageAccess
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by Fernflower decompiler)
//
package org.hibernate.cache.spi.support;
import org.hibernate.engine.spi.SharedSessionContractImplementor;
public interface DomainDataStorageAccess extends StorageAccess {
default void putFromLoad(Object key, Object value, SharedSessionContractImplementor session) {
this.putIntoCache(key, value, session);
}
}4.1.1.2.3 RegionFactoryTemplate
RegionFactoryTemplate是RegionFactory的一个模版类。
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by Fernflower decompiler)
//
package org.hibernate.cache.spi.support;
import org.hibernate.cache.cfg.spi.DomainDataRegionBuildingContext;
import org.hibernate.cache.cfg.spi.DomainDataRegionConfig;
import org.hibernate.cache.internal.DefaultCacheKeysFactory;
import org.hibernate.cache.spi.AbstractRegionFactory;
import org.hibernate.cache.spi.CacheKeysFactory;
import org.hibernate.cache.spi.DomainDataRegion;
import org.hibernate.cache.spi.QueryResultsRegion;
import org.hibernate.cache.spi.TimestampsRegion;
import org.hibernate.engine.spi.SessionFactoryImplementor;
public abstract class RegionFactoryTemplate extends AbstractRegionFactory {
public RegionFactoryTemplate() {
}
public DomainDataRegion buildDomainDataRegion(DomainDataRegionConfig regionConfig, DomainDataRegionBuildingContext buildingContext) {
this.verifyStarted();
return new DomainDataRegionTemplate(regionConfig, this, this.createDomainDataStorageAccess(regionConfig, buildingContext), this.getImplicitCacheKeysFactory(), buildingContext);
}
protected CacheKeysFactory getImplicitCacheKeysFactory() {
return DefaultCacheKeysFactory.INSTANCE;
}
protected DomainDataStorageAccess createDomainDataStorageAccess(DomainDataRegionConfig regionConfig, DomainDataRegionBuildingContext buildingContext) {
throw new UnsupportedOperationException("Not implemented by caching provider");
}
public QueryResultsRegion buildQueryResultsRegion(String regionName, SessionFactoryImplementor sessionFactory) {
this.verifyStarted();
return new QueryResultsRegionTemplate(regionName, this, this.createQueryResultsRegionStorageAccess(regionName, sessionFactory));
}
protected abstract StorageAccess createQueryResultsRegionStorageAccess(String var1, SessionFactoryImplementor var2);
public TimestampsRegion buildTimestampsRegion(String regionName, SessionFactoryImplementor sessionFactory) {
this.verifyStarted();
return new TimestampsRegionTemplate(regionName, this, this.createTimestampsRegionStorageAccess(regionName, sessionFactory));
}
protected abstract StorageAccess createTimestampsRegionStorageAccess(String var1, SessionFactoryImplementor var2);
}总结:
Hibernate内部实现了大多数的扩展,我们只需要扩展RegionFactory和DomainDataStorageAccess接口既可以自定义Hibernate的二级缓存。Hibernate为实现RegionFactory提供了一个模版类RegionFactoryTemplate,我们直接通过实现该类和DomainDataStorageAccess,即可自定义Hibernate二级缓存。
4.1.2 Mybatis 二级缓存扩展
4.1.2.1 Mybatis缓存介绍
MyBatis 是一款优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 POJOs(Plain Ordinary Java Object,普通的 Java对象)映射成数据库中的记录。
缓存流程图:
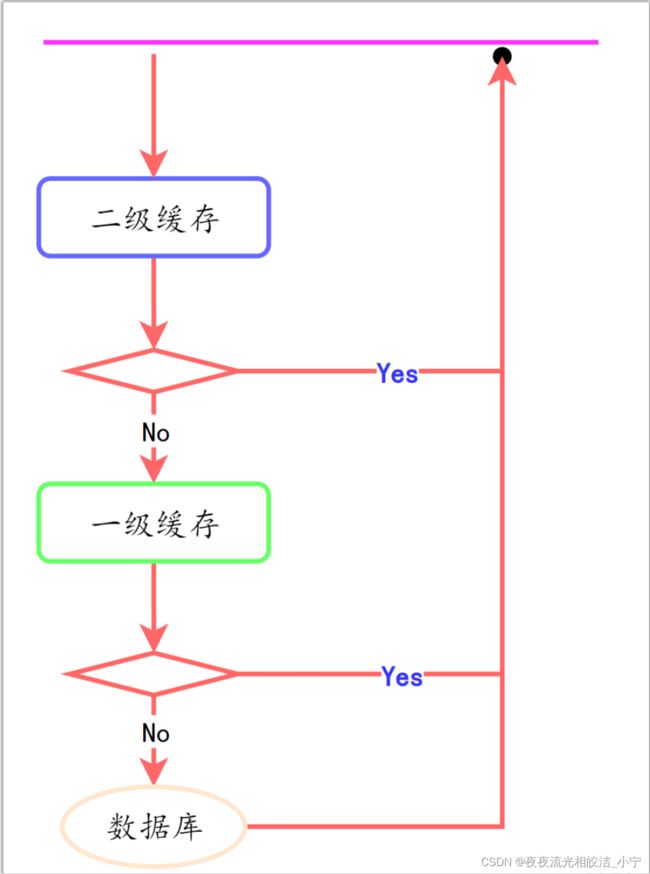
一二级缓存关系:

4.1.2.1.1 一级缓存
一级缓存是在MyBatis的SqlSession级别上运作的。在同一个SqlSession中执行的查询会被缓存起来,以便在后续的查询中重用。默认情况下,MyBatis启用了一级缓存。
4.1.2.1.2 二级缓存
二级缓存是在Mapper级别上运作的。这意味着在多个SqlSession之间,查询的结果可以被缓存起来并重用。MyBatis使用基于命名空间的二级缓存,这意味着每个Mapper都有自己的缓存。
4.1.2.2 Mybatis缓存扩展点说明
4.1.2.2.1 Cache接口
Mybatis只有一个核心的缓存接口Cache,他的实现类只有一个,是PerpetualCache,不管是一级缓存还是二级缓存,都是使用的PerpetualCache缓存实现类。我们看下Cache的源码,分析下他的方法
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by Fernflower decompiler)
//
package org.apache.ibatis.cache;
import java.util.concurrent.locks.ReadWriteLock;
public interface Cache {
// 获取缓存对象标识
String getId();
// 往缓存中放数据
void putObject(Object var1, Object var2);
// 获取缓存数据
Object getObject(Object var1);
// 删除缓存数据
Object removeObject(Object var1);
// 清空缓存数据
void clear();
// 获取缓存数据的数量
int getSize();
default ReadWriteLock getReadWriteLock() {
return null;
}
}我们要扩展Mybatis二级缓存,可以基于Cache接口,实现要扩展的缓存实现。
4.2 Sprig Cache 缓存扩展
4.2.1 Spring Cache简介
Spring Cache是Spring-context包中提供的基于注解方式使用的缓存组件,定义了一些标准接口,通过实现这些接口,就可以通过在方法上增加注解来实现缓存。这样就能够避免缓存代码与业务处理耦合在一起的问题。
4.2.2 扩展接口源码分析
4.2.2.1 Cache
Spring Cache提供了两个便于扩展的接口,其中一个是Cache接口,该接口定义提供缓存的具体操作,比如缓存的放入、读取、清理。
package org.springframework.cache;
public interface Cache {
// cacheName,缓存的名字,默认实现中一般是CacheManager创建Cache的bean时传入cacheName
String getName();
// 得到底层使用的缓存,如Ehcache
Object getNativeCache();
// 通过key获取缓存值,注意返回的是ValueWrapper,为了兼容存储空值的情况,将返回值包装了一层,通过get方法获取实际值
@Nullable
Cache.ValueWrapper get(Object key);
// 通过key获取缓存值,返回的是实际值,即方法的返回值类型
@Nullable
T get(Object key, @Nullable Class type);
// 通过key获取缓存值,可以使用valueLoader.call()来调使用@Cacheable注解的方法。当@Cacheable注解的sync属性配置为true时使用此方法。
// 因此方法内需要保证回源到数据库的同步性。避免在缓存失效时大量请求回源到数据库
@Nullable
T get(Object key, Callable valueLoader);
// 将@Cacheable注解方法返回的数据放入缓存中
void put(Object key, @Nullable Object value);
// 当缓存中不存在key时才放入缓存。返回值是当key存在时原有的数据
@Nullable
default Cache.ValueWrapper putIfAbsent(Object key, @Nullable Object value) {
Cache.ValueWrapper existingValue = this.get(key);
if (existingValue == null) {
this.put(key, value);
}
return existingValue;
}
// 删除缓存
void evict(Object key);
default boolean evictIfPresent(Object key) {
this.evict(key);
return false;
}
// 清空缓存
void clear();
default boolean invalidate() {
this.clear();
return false;
}
public static class ValueRetrievalException extends RuntimeException {
@Nullable
private final Object key;
public ValueRetrievalException(@Nullable Object key, Callable loader, Throwable ex) {
super(String.format("Value for key '%s' could not be loaded using '%s'", key, loader), ex);
this.key = key;
}
@Nullable
public Object getKey() {
return this.key;
}
}
// 缓存返回值的包装
@FunctionalInterface
public interface ValueWrapper {
@Nullable
Object get();
} 4.2.2.2 CacheManager
主要提供Cache实现bean的创建,每个应用里可以通过cacheName来对Cache进行隔离,每个cacheName对应一个Cache实现。
package org.springframework.cache;
import java.util.Collection;
import org.springframework.lang.Nullable;
public interface CacheManager {
// 通过cacheName创建Cache的实现bean,具体实现中需要存储已创建的Cache实现bean,避免重复创建,也避免内存缓存
@Nullable
Cache getCache(String name);
// 返回所有的cacheName
Collection getCacheNames();
} 
总结:想要扩展替换Spring Cache的缓存实现,只需要实现Cache 和 CacheManager两个接口即可。
4.2.3 常用注解说明
4.2.3.1 @Cacheable
主要应用到查询数据的方法上。
package org.springframework.cache.annotation;
import java.lang.annotation.Documented;
import java.lang.annotation.ElementType;
import java.lang.annotation.Inherited;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
import org.springframework.core.annotation.AliasFor;
@Target({ElementType.TYPE, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Documented
public @interface Cacheable {
// cacheNames,CacheManager就是通过这个名称创建对应的Cache实现bean
@AliasFor("cacheNames")
String[] value() default {};
@AliasFor("value")
String[] cacheNames() default {};
// 缓存的key,支持SpEL表达式。默认是使用所有参数及其计算的hashCode包装后的对象(SimpleKey)
String key() default "";
// 缓存key生成器,默认实现是SimpleKeyGenerator
String keyGenerator() default "";
// 指定使用哪个CacheManager,如果只有一个可以不用指定
String cacheManager() default "";
// 缓存解析器
String cacheResolver() default "";
// 缓存的条件,支持SpEL表达式,当达到满足的条件时才缓存数据。在调用方法前后都会判断
String condition() default "";
// 满足条件时不更新缓存,支持SpEL表达式,只在调用方法后判断
String unless() default "";
// 回源到实际方法获取数据时,是否要保持同步,如果为false,调用的是Cache.get(key)方法;如果为true,调用的是Cache.get(key, Callable)方法
boolean sync() default false;
}
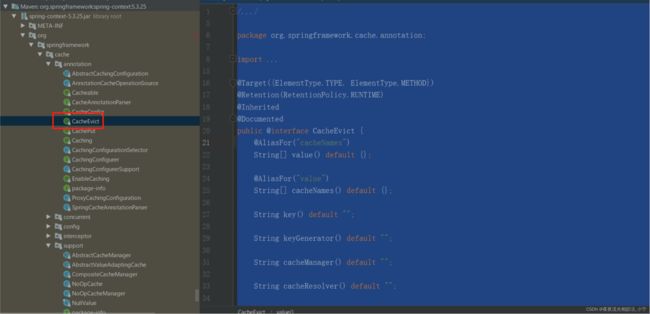
4.2.3.2 @CacheEvict
清除缓存,主要应用到删除数据的方法上。相比Cacheable多了两个属性
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by Fernflower decompiler)
//
package org.springframework.cache.annotation;
import java.lang.annotation.Documented;
import java.lang.annotation.ElementType;
import java.lang.annotation.Inherited;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
import org.springframework.core.annotation.AliasFor;
@Target({ElementType.TYPE, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Documented
public @interface CacheEvict {
@AliasFor("cacheNames")
String[] value() default {};
@AliasFor("value")
String[] cacheNames() default {};
String key() default "";
String keyGenerator() default "";
String cacheManager() default "";
String cacheResolver() default "";
String condition() default "";
// 是否要清除所有缓存的数据,为false时调用的是Cache.evict(key)方法;为true时调用的是Cache.clear()方法
boolean allEntries() default false;
// 调用方法之前或之后清除缓存
boolean beforeInvocation() default false;
}
4.2.3.3 @CachePut
放入缓存,主要用到对数据有更新的方法上。属性说明参考@Cacheable
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by Fernflower decompiler)
//
package org.springframework.cache.annotation;
import java.lang.annotation.Documented;
import java.lang.annotation.ElementType;
import java.lang.annotation.Inherited;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
import org.springframework.core.annotation.AliasFor;
@Target({ElementType.TYPE, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Documented
public @interface CachePut {
@AliasFor("cacheNames")
String[] value() default {};
@AliasFor("value")
String[] cacheNames() default {};
String key() default "";
String keyGenerator() default "";
String cacheManager() default "";
String cacheResolver() default "";
String condition() default "";
String unless() default "";
}
4.2.3.4 @Caching
用于在一个方法上配置多种注解
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by Fernflower decompiler)
//
package org.springframework.cache.annotation;
import java.lang.annotation.Documented;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
import org.springframework.context.annotation.AdviceMode;
import org.springframework.context.annotation.Import;
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Import({CachingConfigurationSelector.class})
public @interface EnableCaching {
boolean proxyTargetClass() default false;
AdviceMode mode() default AdviceMode.PROXY;
int order() default 2147483647;
}

由于篇幅原因,本问就先介绍集成技术原理和扩展相关缓存的知识,源码分享会在后续篇章介绍,好了,本次分享就到这里,如果帮助到大家,欢迎大家点赞+关注+收藏,有疑问也欢迎大家评论留言!