使用NEON单元将MIPI的Raw图像转换YUV和16位数组的方法
几个指令参考的网页
NEON非常好的实例讲解运算的网页
NEON数据转换
NEON指令描述
Raw 转 YUB 8BIT的目的
嵌入式芯片的视频压缩硬件加速对输入的原始图像一般都有要求,多为支持RGB或YUV格式。对于灰度图输入的MIPI图像在没回应ISP 转换模块的情况下需要使用软件进行Raw的转换。
编译参数
GCC 参数说明
需要使用硬件浮点 -mfloat-abi=hard -ftree-vectorize参数
armclang 编译器参数 --target=arm-arm-none-eabi -mcpu=cortex-a7 -mfpu=neon-vfpv4 -mfloat-abi=hard -marm -O0 -g
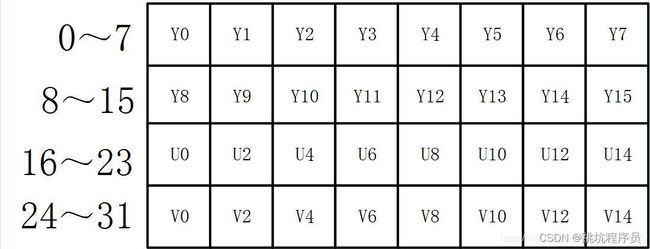
YUV planar格式介绍
关于yuv 格式:planar,semiplana,Interleaved格式区别
YUV介绍
planar 格式,Y U V 分3个数组拼接
semiplana:
Semi 是“半”的意思,个人理解这个是半平面模式,这个格式的数据量跟YUV422 Planar的一样,但是U、V是交叉存放的。
Interleaved (packed):
Y U V 在一个数组间隔排列:

YUV比例格式介绍
https://zhuanlan.zhihu.com/p/564449553
YUV 4:4:4 采样
YUV 4:4:4 采样,意味着 Y、U、V 三个分量的采样比例相同,因此在生成的图像里,每个像素的三个分量信息完整,都是 8 bit,也就是一个字节。
YUV 4:2:2 采样
YUV 4:2:2 采样,意味着 UV 分量是 Y 分量采样的一半,Y 分量和 UV 分量按照 2 : 1 的比例采样。如果水平方向有 10 个像素点,那么采样了 10 个 Y 分量,而只采样了 5 个 UV 分量。
YUV 4:2:0 采样
YUV 4:2:0 采样,并不是指只采样 U 分量而不采样 V 分量。而是指,在每一行扫描时,只扫描一种色度分量(U 或者 V),和 Y 分量按照 2 : 1 的方式采样。比如,第一行扫描时,YU 按照 2 : 1 的方式采样,那么第二行扫描时,YV 分量按照 2:1 的方式采样。对于每个色度分量来说,它的水平方向和竖直方向的采样和 Y 分量相比都是 2:1 。
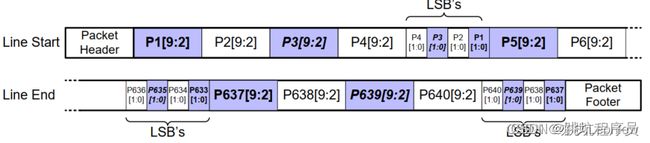
MIPI RAW 介绍
我理解为多个BIT 凑整数给BYTE为一组,高位放到后面的BYTE拼接为一组。
MIPI RAW 介绍
8位RAW灰度

10位RAW灰度
12位RAW灰度

20位RAW灰度

对于RAW灰度转YUV分析
RAW转YUV灰度图来说,使用plane较为方便因为UV分量直接可以赋值0不需要考虑。
#include "arm_neon.h"
//Linux #include 对于RAW灰度转YUV 并进行缩放
#define FIT_UV_VALUE 128
#define NUMB_ONE_TIME 6 //非8bit 一次能输出的PIX 图像点数,建议使用一组比较好计数和理解
int scale(char format_index, short width, short height,unsigned char *in,unsigned char *out){
unsigned short i,j;
unsigned short out_w = width/2;
unsigned short out_h = height/2;
int size ;
uint8x8_t output;
unsigned char *out_t=out;
static unsigned char * bf_out=0;
size=out_w*out_h;
if((bf_out!=out)||(*(out+size)!=FIT_UV_VALUE)){//如果地址改变了需要对UV区域赋初值,没有判断大小变化,如果图片大小在运行中变化可能需要另外处理
bf_out=out;//保存当前变量
memset(out+out_w*out_h,FIT_UV_VALUE,out_w*out_h/2);//UV区域初值设置
}
if (format_index == 0) //raw8
{
for (i = 0; i < out_h; i++)
{
for ( j = 0; j < out_w; j+=16)//一次处理16个输出数据,间隔丢弃数据
{
uint8x16x2_t uvData = vld2q_u8(in + 2 * j);
vst1q_u8(out_t + j, uvData.val[0]);
//丢弃了奇数数的图像 vst1q_u8(v + i, uvData.val[1]);
}
in+=width*2;//2倍out_w丢弃一行
out_t+=out_w;//下一行
}
memset(out+size,FIT_UV_VALUE,16);//清除8个UV值,应为前面处理可能会超界限
}
else //raw10
{
uint8x8_t select={0,1,10,11,5,6,0xff,0xff};//跳开了低位存储的BYTE 10BIT 16个字节 4,9,14
for (i = 0; i < out_h; i++)
{
for ( j = 0; j < out_w; j+=NUMB_ONE_TIME)//一次处理6个输出数据,间隔丢弃数据
{
uint8x8x2_t uvData = vld2_u8(in +5*j/2);//输入交错分开位2组
output=vtbl2_u8(uvData, select);//取数组大于第二组N个位8+N
vst1_u8(out_t+j, output);//将4路数据拷贝到Y分量
}
in+=width/2*5;//每4个字节共享一个8位的低位BIT
out_t+=out_w;//下一行
}
memset(out+size,FIT_UV_VALUE,8);//清除8个UV值,应为前面处理可能会超界限
}
return size;
}
int scale_cpu(char format_index, short width, short height,unsigned char *in,unsigned char *out){
int i,j;
int out_w = width/2;
int out_h = height/2;
int size ;
size=out_w*out_h;
static unsigned char * bf_out=0;
if((bf_out!=out)||(*(out+size)!=FIT_UV_VALUE)){//如果地址改变了需要对UV区域赋初值,没有判断大小变化,如果图片大小在运行中变化可能需要另外处理
bf_out=out;//保存当前变量
memset(out+out_w*out_h,FIT_UV_VALUE,out_w*out_h/2);//UV区域初值设置
}
if (format_index == 0) //raw8
{
for (i = 0; i < out_h; i++)
{
for ( j = 0; j < out_w; j++)
{
out[i*out_w + j] = in[2*i*width + j*2];
}
}
}
else //raw10
{
for (i = 0; i < out_h; i++)
{
for ( j = 0; j < out_w; j++)
{
out[i*out_w + j] = in[2*i*(width*10/8) + ((j*2)/4*5 + j*2%4)];
}
}
}
return size;
}
#define IMAGE_WIDE 32
#define IMAGE_HIGH 10
uint8_t image_raw10[IMAGE_WIDE*5/4*IMAGE_HIGH]={
1,2,3,4,0X50,5,6,7,8,0XA0,9,10,11,12,0XA5,13,14,15,16,0Xff,17,18,19,20,0X50,21,22,23,24,0XA0,25,26,27,28,0XA5,29,30,31,32,0Xff,
0xf1,0x12,3,4,0X50,5,6,7,8,0XA0,9,10,11,12,0XA5,13,14,15,16,0Xff,17,18,19,20,0X50,21,22,23,24,0XA0,25,26,27,28,0XA5,29,30,31,32,0Xff,
0xe1,0x22,3,4,0X50,5,6,7,8,0XA0,9,10,11,12,0XA5,13,14,15,16,0Xff,17,18,19,20,0X50,21,22,23,24,0XA0,25,26,27,28,0XA5,29,30,31,32,0Xff,
0xd1,0x32,3,4,0X50,5,6,7,8,0XA0,9,10,11,12,0XA5,13,14,15,16,0Xff,17,18,19,20,0X50,21,22,23,24,0XA0,25,26,27,28,0XA5,29,30,31,32,0Xff,
0xc1,0x42,3,4,0X50,5,6,7,8,0XA0,9,10,11,12,0XA5,13,14,15,16,0Xff,17,18,19,20,0X50,21,22,23,24,0XA0,25,26,27,28,0XA5,29,30,31,32,0Xff,
0xb1,0x52,3,4,0X50,5,6,7,8,0XA0,9,10,11,12,0XA5,13,14,15,16,0Xff,17,18,19,20,0X50,21,22,23,24,0XA0,25,26,27,28,0XA5,29,30,31,32,0Xff,
0xa1,0x62,3,4,0X50,5,6,7,8,0XA0,9,10,11,12,0XA5,13,14,15,16,0Xff,17,18,19,20,0X50,21,22,23,24,0XA0,25,26,27,28,0XA5,29,30,31,32,0Xff,
0x91,0x72,3,4,0X50,5,6,7,8,0XA0,9,10,11,12,0XA5,13,14,15,16,0Xff,17,18,19,20,0X50,21,22,23,24,0XA0,25,26,27,28,0XA5,29,30,31,32,0Xff,
0x81,0x82,3,4,0X50,5,6,7,8,0XA0,9,10,11,12,0XA5,13,14,15,16,0Xff,17,18,19,20,0X50,21,22,23,24,0XA0,25,26,27,28,0XA5,29,30,31,32,0Xff,
0x71,0x92,3,4,0X50,5,6,7,8,0XA0,9,10,11,12,0XA5,13,14,15,16,0Xff,17,18,19,20,0X50,21,22,23,24,0XA0,25,26,27,28,0XA5,29,30,31,32,0Xff,
};
uint8_t image_raw8[IMAGE_WIDE*IMAGE_HIGH]={
1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,32,33,24,25,26,27,28,29,30,31,32,
0xf1,0x12,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,32,33,24,25,26,27,28,29,30,31,32,
0xe1,0x22,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,32,33,24,25,26,27,28,29,30,31,32,
0xd1,0x32,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,32,33,24,25,26,27,28,29,30,31,32,
0xc1,0x42,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,32,33,24,25,26,27,28,29,30,31,32,
0xb1,0x52,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,32,33,24,25,26,27,28,29,30,31,32,
0xa1,0x62,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,32,33,24,25,26,27,28,29,30,31,32,
0x91,0x72,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,32,33,24,25,26,27,28,29,30,31,32,
0x81,0x82,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,32,33,24,25,26,27,28,29,30,31,32,
0x71,0x92,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,32,33,24,25,26,27,28,29,30,31,32,
};
uint8_t image_yuv[IMAGE_WIDE*IMAGE_HIGH*3/4];
uint8_t image_yuv_bf[IMAGE_WIDE*IMAGE_HIGH*3/4];
uint16_t image16[IMAGE_WIDE*IMAGE_HIGH];
void test(void){
memset(image_yuv,0,sizeof(image_yuv));//测试时清空方便看改变
row10_yuv420_p(image_raw10,image_yuv,IMAGE_WIDE*IMAGE_HIGH);
row10_uint16(image_raw10,image16,IMAGE_WIDE*IMAGE_HIGH);
scale(0,IMAGE_WIDE,IMAGE_HIGH,image_raw8,image_yuv);
memset(image_yuv,FIT_UV_VALUE,sizeof(image_yuv));//测试时清空方便看改变
scale(0,IMAGE_WIDE,IMAGE_HIGH,image_raw8,image_yuv);
scale_cpu(0,IMAGE_WIDE,IMAGE_HIGH,image_raw8,image_yuv_bf);
memset(image_yuv_bf+(IMAGE_WIDE/2*IMAGE_HIGH/2), 128, (IMAGE_WIDE*IMAGE_HIGH/2)); //raw8 to yuv
if(memcmp(image_yuv_bf,image_yuv,IMAGE_WIDE)==0){
printf("same\n");
}
else{
printf("not same\n");
}
memset(image_yuv,FIT_UV_VALUE,sizeof(image_yuv));//测试时清空方便看改变
scale(1,IMAGE_WIDE,IMAGE_HIGH,image_raw10,image_yuv);
scale_cpu(1,IMAGE_WIDE,IMAGE_HIGH,image_raw10,image_yuv_bf);
memset(image_yuv_bf+(IMAGE_WIDE/2*IMAGE_HIGH/2), 128, (IMAGE_WIDE*IMAGE_HIGH/2)); //raw8 to yuv
if(memcmp(image_yuv_bf,image_yuv,sizeof(image_yuv))==0){
printf("same\n");
}
else{
printf("not same\n");
}
}
输出内存结果

使用NEON 401 条指令完成ROW8转换运算
使用cpu 1,889 条指令完成运算 ROW8转换运算
使用NEON 986条指令完成ROW10转换运算
使用cpu 2,528 条指令完成运算 ROW10转换运算
NEON ROW8 转 开始时状态:

CPU ROW8转 开始时状态:

转换结束 开始时状态: