RocketMQ 简单原理
早期的消息中间件是通过 队列 这一模型来实现的,可能是历史原因,我们都习惯把消息中间件成为消息队列。
但是,如今例如 RocketMQ 、 Kafka 这些优秀的消息中间件不仅仅是通过一个 队列 来实现消息存储的。
队列模型
就像我们理解队列一样,消息中间件的队列模型就真的只是一个队列 (类似blockQueue?)

对于单个消费者是没什么问题, 但是如果我们需要将一个消息发送给多个消费者, 单个队列好像有点不够用了. [并发问题 , 性能问题]
主题模型
在主题模型中,消息的生产者称为 发布者(Publisher) ,消息的消费者称为 订阅者(Subscriber) ,存放消息的容器称为 主题(Topic) 。
其中,发布者将消息发送到指定主题中,订阅者需要 提前订阅主题 才能接受特定主题的消息。
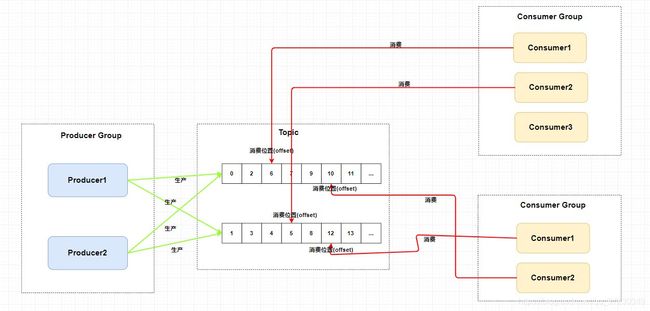
-
Producer Group 生产者组: 代表某一类的生产者,这多个合在一起就是一个 Producer Group 生产者组,它们一般生产相同的消息。
-
Consumer Group 消费者组: 代表某一类的消费者,这多个合在一起就是一个 Consumer Group 消费者组,它们一般消费相同的消息。
-
Topic 主题: 代表一类消息
总的来说 :
提高并发的能力 , 高并发下多个队列分担 增加和消费 , 分而治之 .
rocketmq 是通过一个 topic , 中配置多个队列, 每个队列维护了一个消费者的消费位置 , 实现发布订阅.


NameServer
核心三功能 :
1、路由注册
RocketMQ路由注册是通过 NameServer <===> Broker 的 心跳功能实现 , Broker 在启动时 , 向nameServer集群每隔30S 发送心跳包 . NameServer 收到Broker 心跳包后会更新 活着Broker last Update时间.
NameServer会启动一个线程, 每10S扫描一次, 超过120S没心跳的Broker会被踢出路由.
路由的维护 使用了读写锁 , 路由获取多 、 路由修改少的场景.
同一时刻 NameServer 只处理一个 Broker 心跳包,多个心跳 包请求串行执行
2、路由删除
Broker 每30S向NameServer 发送一个心跳包包含: BrokerId 、Broker 地址、Broker名称、集群名等 .
两种方式让Nameserver 路由删除 :
1、如果Broker宕机 , nameServer 120S 没有收到 Broker的心跳 就认为Broker失效 , 移除该Broker, 更新所有路由表.
2、Broker 正常关机 . 向nameserver发送 unrgisterBroker 指令
3、路由发现
Rocketmq 的路由发现是非实时的 , 当topic路由发生变化时 , NameServer不主动推送给客户端 , 是由客户端定时拉取最新路由 .
1、NameServer 之间是互相独立的机器, 彼此没有通信关系 , 单台nameServer挂了, 不影响其他nameServer.
2、Broker会向所有已知的NameServer发送心跳, 每30秒发送一次, 并携带自己Broker的一些信息, 在NameServer上进行注册 , NameServer 每隔10秒 扫描所有还存活的broker连接,如果某个连接的最后更新时间与当前时间差值超过2分钟,则断开此连接。此外,NameServer也会断开此broker下所有与slave的连接。 同时更新topic与队列的对应关系,但不会通知生产者和消费者 。 [每个broker 都和所有的nameServer 进行心跳 ]
总结: nameServer更轻量 , 互相独立不通信 性能更好, 保存着broker的相关信息, 生产者和消费者从nameServer获取信息进行后续操作.
Producer发送端
问题 : 120S 才能去掉 死了的Broker ?? producer 发送消息失败了 不是丢消息了吗 ?
1、同步发送 (sync)
producer 向Broker 发送消息 , 同步等待直到Broker返回结果
retryTimesWhenSendFailed :同 步方式发送消息重试次数, 默认为 2 ,总共执行 3 次。
2、异步发送 (async)
指定消息发送成功后的回调函数 , producer 向Broker 发送消息 , 立即返回结果 , 消息发送成功或失败时调用回调函数 .
retryTimesWhensyndAsyncFailed :异步方式发送消息重试次数, 默认为 2。
3、单向发送 (oneWay)
producer 只管发送, 不管结果.
Producer初始化
前提 : 整个JVM 只有一个 MQClientManager , 维护一个 MQClientInstance 的缓存表
ConcurrentMap



Step 1:检查 productGroup 是否符合要求;
Step 2: 根据 客户端 IP+instanceName , 生成clientID , 根据clientID 获取 或 创建MQClientInstance 实例
同一个 jvm 中 的不同消费者和不同生产者在启动时获取到的相同ClientID的 MQClientInstance
优点: 不用创建重复的连接 .
Step3 : 将 producer 或 consumer 注册到 MQClientInstance 中 , 方便后续网络请求心跳等.
step4 : 如果没启动, 就启动MQclientInstance
注意:
复用一个MQClientInstance会有怎么样的问题呢?这种情况会出现在你在一个JVM里启动了多个Producer时,且没有设置instanceName和unitName,那么这两个Producer会公用一个MQClientInstance,发送的消息会路由到同一个集群。例如,你起了两个Producer,并且配置的NameServer地址不一样,本意是让这两个Producer往不同集群上分配消息,但是由于共用了一个MQClientInstance,这个MQClientInstance是基于先来的Producer配置构建的,第二个Producer和他公用后被认为是同一instance,配置是相同的,消息的路由就是相同的,就没有达到想要的效果。
Producer 发送消息
1、获取此主题的 队列路由
topic 是一个逻辑结构, 到底要存到哪个Broker上? 哪个队列上呢? 去nameServer 获取路由撒
相当于 topicA 总共有8个队列! 分布在了2台broker上 .
前提 : Nameserver 检测到broker宕机时 , 是不会推给 producer变化的 , 只有producer 30S 更新路由的请求到达时, 才会更新topic路由.
发送失败策略:
-
失败隔离:即发送消息到某个broker失败之后,将其进行隔离,优先从其他正常的broker中进行选择
-
延迟隔离:优先发送消息到延迟比较小的broker
消息存储+文件+刷盘
从主流的几种MQ消息队列采用的存储方式来看,主要会有三种
1、: 分布式KV 存储 比如ActiveMQ中采用的levelDB、Redis, 这种存储方式对于消息读写能力要求不高的情况下可以使用
2、: 文件系统刷盘存储. 常见的比如kafka、RocketMQ、RabbitMQ都是采用消息刷盘到所部署的机器上的 文件系统来做持久化,这种方案适合对于有高吞吐量要求的消息中间件,因为消息刷盘是一种高效 率,高可靠、高性能的持久化方式,除非磁盘出现故障,否则一般是不会出现无法持久化的问题.
3、: 关系型数据库存储 . 比如ActiveMQ可以采用mysql作为消息存储,关系型数据库在单表数据量达到千 万级的情况下IO性能会出现瓶颈,所以ActiveMQ并不适合于高吞吐量的消息队列场景。
RocketMQ 的所有[Topic+队列]消息信息 都放在一个 commitLog中
保证了插入的磁盘顺序写.
队列中的消息还要回查commitLog 会存在随机读 ! 由 pageCache 去解决
RocketMQ消息的存储结构
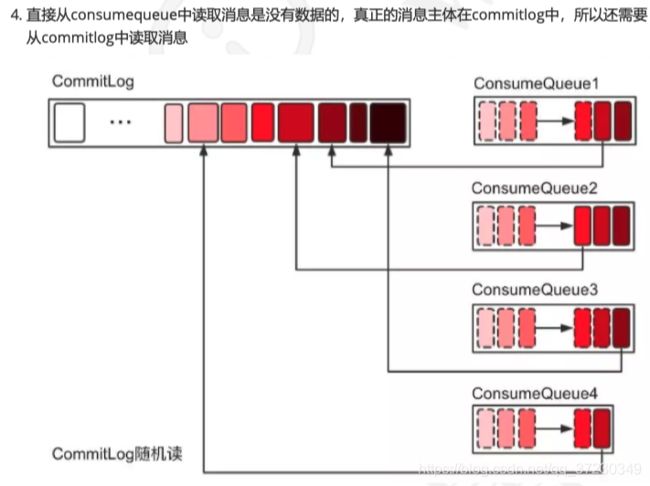
消息插入commitLog , 再由dispatcher 转发到不同的consumeQueue中
消息的存储由ConsumeQueue 和 CommitLog 配合完成 .
CommitLog 是完整消息真正的存储.
ConsumeQueue 是topic队列的消息存储 . 存的像是一个索引文件, 根据里面的内容去commitLog 查找真正的消息体
CommitLog:
是用来存放所有消息的物理文件 , 和kafka 不一样, 没有分成多个 segament
CommitLog 默认大小 1G , 当一个文件写满后, 会生成一个新的CommitLog, 所有topic的数据 顺序写入commitLog
文件名也代表了offset .
ConsumeQueue :
各个topic 下的 队列
里面的消息 包含了 在commitLog的offset , messageTag 和 消息大小.
每个consume队列中的文件也是有大小的 . 满了会再生成一个 .
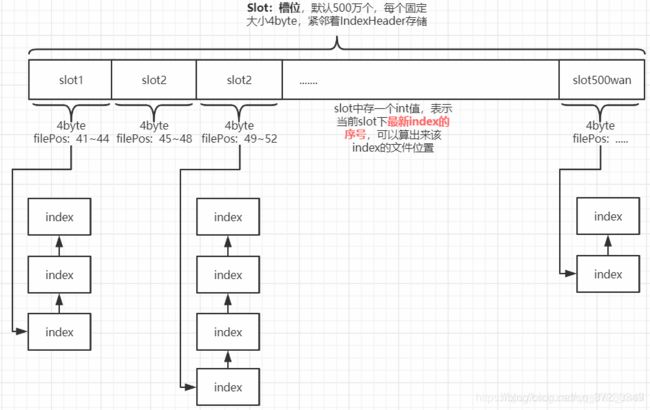
IndexFile:
index文件提供了对commitLog 进行数据检索 . 通过key 和 时间区间 来查找 commitLog 中的消息.
物理存储上以 时间戳为文件名 .
CheckPoint:
记录不同日志文件的刷盘时间点 . 当上一次broker是异常结束时,会根据StoreCheckpoint的数据进行恢复
physicMsgTimestamp: commitlog 文件刷盘时间点 。
logicsMsgTimestamp : 消息消费队列文件刷盘时间点 。
indexMsgTimestamp :索引 文件刷盘时间点 。
根据消息更新 ConsumeQueue
当commitLog 写完后就认为持久化成功, 由异步线程将commitLog的消息派发到 consumeQueueLog 中.
Step1 : 根据topic + queueId 锁定一个 consumeQueue文件
Step2 : 将消息体追加到consumeQueue的内存映射文件[mmap使用] 只追加, 不刷盘 , consumeQueue固定是异步刷盘 . 保证了commitLog的完全顺序写.
其他 : 更新 indexFile 等.
还没更新ConsumeQueue , Broker挂了?
如果消息成功存储到 Commitlog 文件中,转发任务未 成功执行,此时消息服务器 Broker 由 于某个原因宕机,导致 Commitlog 、 ConsumeQueue 、 IndexFile 文件数据不一致 [ commitLog中有, consumeQueue中没有 ]。因此在加载时 , 需要一定的校验和数据修复.
如果abort 文件存在, 说明重启后需要要进行异常文件恢复
根据checkPoint 找到上次最后一个正常commitlog的文件 , 将checkPoint 时间点后的消息重新发一遍 !! 确保消息不丢失.
CommitLog文件刷盘机制
RocketMQ 的存储与读写是基于 JDK NIO 的内存映射机制( MappedByteBuffer)
同步刷盘 : org.apache.rocketmq.store.CommitLog#submitFlushRequest
消费发送线程将消息追加到内存映射文件后,将同步任务 GroupCommitRequest 提交到 GroupCommitService 线程,然后调用阻塞等待刷盘结果,超时时间默认为 5s , 等待刷盘成功.
提交线程每10ms执行一遍请求的刷盘, 并唤醒阻塞的线程 .
细节: 实际上是 先收集一波刷盘请求, 10MS之后进行统一的刷盘, 再将这些请求的阻塞线程唤醒.
异步刷盘 : org.apache.rocketmq.store.CommitLog.FlushRealTimeService
使用一个单独线程, 设定一个频率定时进行刷盘操作. Commitlog#handleDiskFlush()
flushlntervalCommitLog: FlushRealTimeService 线程任务运行间隔 默认 刷盘频率 500ms
flushPhysicQueueLeastPages : 一次刷写任务至少包含页数, 如果待刷 写数据不足, 小于该参数配置的值,将忽略本次刷写任务,默认 4 页 。
flushPhysicQueueThoroughlnterval :两次真实刷写任务最大间隔, 默认 10s 。
什么时候清理物理文件 ?
1、消息文件过期(默认72小时),且到达清理时点(默认是凌晨4点),删除过期文件
2、消息文件过期(默认72小时),且磁盘空间达到了水位线(默认75%),删除过期文件
3、磁盘已经达到必须释放的上限(85%水位线)的时候,则开始批量清理文件(无论是否过期),直到空间充足。
4、若磁盘空间达到危险水位线(默认90%),出于保护自身的目的,broker会拒绝写入服务。
消费者
消息消费概述
消费者 以 组的模式展开 , 一个消费组内可以有N个消费者
推模式 : 消息到达Broker后, 主动推送给消费者
拉模式 : 消费者 主动向Broker 获取消息
RocketMQ 的推模式实现是基于拉模式的 , 一个拉取任务完成后立刻开始下一个拉取任务
多个消费者消费多个队列的思想: 每个消费者可以同时消费多个队列 , 但是 一个队列只能被一个消费者消费.
局部顺序消息 : 发送到同一个队列中 , 顺序的消费 .
全局顺序消息 : 只能设置topic 的队列数为1 了 .
RocketMQ 消费者初始化
Step1 : 订阅Topic
1、一种来源是我们业务subscribe方法注册的topic订阅
2、订阅一个基于GroupName的 retry topic , 用于消费重试消息.
Step2 : 初始化 MQClientlnstance 、 Rebalancelmpl (消息重新负载实现类)、OffsetStore 、消费Service 等
Step3 : 向MQClientInstance 注册消费者, 并尝试启动 . [ 同一个rocketMQ集群 , 只需要一个client ]
消息队列负载
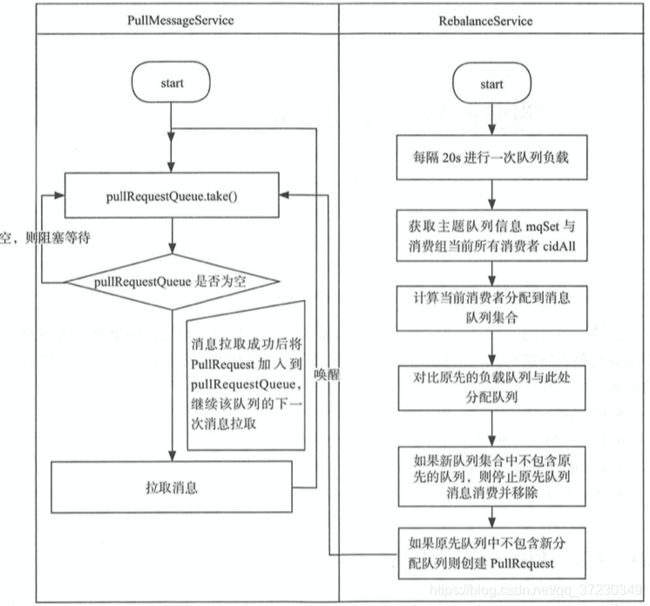
RocketMQ 队列重新分布是由 RebalanceService 线程来实现 , 每隔20S 重新分配一遍.
每隔20S , 获取 TOPIC所有的 consumeQueue , 获取所有的 消费者. 进行负载分配
(AllocateMessageQueueAveragely)平均分配算法(默认)
(AllocateMessageQueueAveragelyByCircle)环状分配消息队列
(AllocateMessageQueueByConfig)按照配置来分配队列: 根据用户指定的配置来进行负载
(AllocateMessageQueueByMachineRoom)按照指定机房来配置队列
(AllocateMachineRoomNearby)按照就近机房来配置队列
(AllocateMessageQueueConsistentHash)一致性hash,根据消费者的cid进行
对比消息队列有无发生变化 ,
比如 当前消费的队列 是 q1 , q2 , 如果新分配到的总队列是 q1,q2,q3 那么需要创建一个q3的pullRequest 去拉取任务
如果当前消费的队列 是 q1 , q2 , 如果新分配到的总队列是 q3 , 那么需要先停止q1 q2 的消费并保存进度 , 并且创建一个q3的pullRequest
其他 : 当有其他消费者上线后 , consumer 会register到Broker , Broker会通知此Topic的所有Consumer进行重新负载.
消息拉取
RocketMQ 并没有真正实现推模式,而是消费者主动向消息服务器拉取消息, RocketMQ 推模式是循环向消息服务端发送消息拉取请求
普通的拉取模式能够让消费端量力而行, 但间隔时间又较难设置 , 因此长连接轮询更好!
如果请求到达服务端, 发现没有可用的消息, 则会在服务端等待 几段时间, 每5秒尝试一次, 有数据直接返回, 尝试3次后返回客户端没找到数据.