BEVFormerV2 论文阅读
论文链接
BEVFormer v2: Adapting Modern Image Backbones to Bird’s-Eye-View Recognition via Perspective Supervision
0. Abstract
- 提出了一种新颖的 BEV 检测器,具有透视监督,收敛速度更快,更适合现代图像基础架构
- 优先考虑通过引入透视视图监督来简化BEV检测器的优化
- 提出了一个两阶段的BEV检测器,其中来自透视头的建议被送入鸟瞰视图头进行最终预测
1. Intro
- 典型的BEV模型基于图像主干构建,随后通过视角转换模块将透视图像特征提取到BEV特征中,然后通过BEV特征编码器和一些特定任务的头部进一步处理
- 在适应现代图像骨干网络时面临以下问题:
- 自然图像与自动驾驶场景之间的领域差距。在通用的2D识别任务上预训练的骨干网络无法准确感知三维场景,尤其是估计深度。
- 当前BEV检测器的复杂结构。以 BEVFormer 为例。三维边界框和物体类别标签的监督信号经过视图编码器和物体解码器分离于图像骨干网络,而每个编码器和解码器都由多层Transformer组成。将通用的2D图像骨干网络进行自动驾驶任务的适应时,渐变流动会受到堆叠Transformer层的干扰
- 为了解决上述在将现代图像主干应用于BEV识别中的困难,将透视监督引入BEVFormer中,即从透视视图任务中获得额外的监督信号,并直接应用于主干
- 在主干上构建了一个透视式3D检测头,它以图像特征作为输入,并直接预测目标物体的3D边界框和类别标签。这个透视头的损失,称为透视损失,作为辅助检测损失被添加到由BEV头产生的原始损失(BEV损失)中
本文贡献
- 透视监督是将通用的2D图像主干适应到BEV模型的关键。通过透视视图中的检测损失明确添加这种监督
- 提出了一种新颖的两阶段BEV检测器,BEVFormer v2。它由透视3D和BEV检测头组成,前者的建议与后者的对象查询相结合
- 通过将本文的方法与最新开发的图像主干相结合,并在nuScenes数据集上取得了显著的改进,突显其有效性
2. Related Works
2.1 BEV 3D 目标检测器
- 早期工作包括:OFT , Pseduo LiDAR , 和 VPN。它们揭示了如何将透视特征转化为BEV特征,但只针对单个相机或较少知名的任务
- OFT 率先采用了从 2D 图像特征到单目 3D 物体检测的 3D BEV 特征的转换
- Pseudo LiDAR 根据单目深度估计和相机内参创建了伪点云,并随后在 BEV 空间中进行处理
- VPN 是第一个将多视角相机输入融合到一个自顶向下视图的特征图中进行语义分割的方法
- 现代方法受益于整合来自2D-3D视图转换提供的不同视角传感器特征的便利
- LSS 通过在 BEV 柱特征汇聚时引入潜在深度分布来扩展 OFT
- PETR 设计了一种不需要显式构建 BEV 特征的方法。透视特征图逐元素与 3D 位置嵌入特征映射融合,并应用后续 DET 落式解码器进行目标检测
- BEVFormer 利用空间交叉注意力进行视图转换,利用时间自注意力进行时间特征融合
2.2 相机三维目标检测中的辅助损失
- 在单目3D目标检测中,辅助损失是普遍存在的,因为大多数方法都是基于2D检测器
- Mono Con 利用多达5种不同的2D监督,充分利用了2D辅助
- 对于BEV检测器,BEVDepth 利用Li - DAR点云对其中间深度网络进行监督
- MV-FCOS3D + + 引入了透视监督来训练其图像主干,但检测器本身只受BEV损失的监督
2.3 两级3D目标检测器
- 尽管两级检测器在基于LiDAR的三维目标检测中很常见,但它们在基于相机的三维检测中的应用却知之甚少
- 在两个阶段中使用来自透视主干的相同特征并没有为第二阶段头部提供信息增益
- 本文的两级检测器同时利用了视角和BEV视角的特征,因此可以同时获得图像和BEV空间的信息
3. BEVFormer V2
- 采用现代2D图像骨架进行BEV识别,无需繁琐的深度预训练,可以为下游自动驾驶任务解锁许多可能性
- 提出了BEVformer v2,一个两阶段的BEV检测器,它将BEV和透视监督结合在一起,以便在BEV检测中无扰地采用图像骨干
3.1 总体架构

Fig.1 BEVFormer v2 的整体架构。图像主干生成多视图图像的特征。透视 3D 头进行透视预测,然后将其编码为对象查询。BEV头为编码器-解码器结构。空间编码器通过聚合多视图图像特征来生成 BEV 特征,然后由时间编码器收集历史 BEV 特征。解码器将混合对象查询作为输入,并根据 BEV 特征进行最终的 BEV 预测。整个模型使用两个检测头 L p e r s L_{pers} Lpers 和 L b e v L_{bev} Lbev 的两个损失项进行训练。
-
BEVFormer v2主要由五个部分组成:图像骨干、透视3D检测头、空间编码器、改进的时间编码器和BEV检测头
- 与原来的 BEVFormer 相比,除空间编码器外的所有组件都进行了更改
- BEVFormer v2 中使用的所有图像骨架都没有使用任何自动驾驶数据集或深度估计数据集进行预训练
- 引入透视3D检测头,方便2D图像主干的适配,为BEV检测头生成目标建议
- 采用一种新的时态BEV编码器,以更好地整合长期时态信息
- BEV 检测头现在接受一组混合对象查询作为输入
-
将第一阶段的提议和学习到的对象查询结合起来,形成第二阶段的新混合对象查询
3.2 透视监督
首先分析鸟瞰模型的问题,以解释为什么需要额外的监督
-
典型的 BEV 模型维护附加到 BEV 平面的网格状特征,其中每个网格聚合来自多视图图像的相应 2D 像素处的特征的 3D 信息。它根据 BEV 特征预测目标对象的 3D 边界框,将这种对 BEV 特征施加的监督称为 BEV 监督
-
3D 到 2D 视图转换和 DETR 头引入的 BEV 监督的两个根本问题
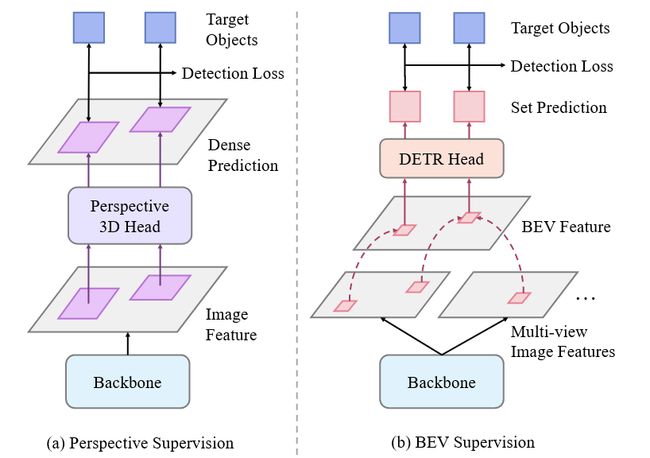
Fig.2 透视监督(a)和BEV监督(B)的比较。透视检测器的监督信号密集且直接针对图像特征,而 BEV 检测器的监督信号稀疏且间接
- 监督对于图像特征来说是隐式的。该损失直接应用于 BEV 特征,而在 3D 到 2D 投影和对图像特征的仔细采样之后,其作用变为间接
- 监督对于图像特征来说是稀疏的。只有少数参与对象查询的 BEV 网格会造成损失。因此,只有这些网格的 2D 参考点周围的稀疏像素才能获得监控信号
-
因此,在训练过程中会出现不一致的情况:BEV 检测头依赖于图像特征中包含的 3D 信息,但它为骨干网络如何编码这些信息提供的指导不足
与 BEV 头相比,透视 3D 头对图像特征进行逐像素预测,为适应 2D 图像主干提供更丰富的监督信号,将这种对图像特征施加的监督定义为透视监督
- 与BEV监督不同,透视检测损失直接且密集地应用于图像特征
3.3 透视损失
透视监督是优化 BEV 模型的关键
-
在 BEVformer v2 中,通过辅助透视损失引入透视监督
- 在主干上构建透视3D检测头来检测透视图中的目标物体
- 采用类似 FCOS3D 的检测头,它可以预测 3D 边界框的中心位置、大小、方向和投影中心度
- 该头的检测损失,表示为透视损失 L p e r s \mathcal{L}_{pers} Lpers,作为BEV损失 L b e v \mathcal{L}_{bev} Lbev 的补充,促进骨干网的优化
L t o t a l = λ b e v L b e v + λ p e r s L p e r s (1) \mathcal{L}_{total} = λ_{bev}\mathcal{L}_{bev} + λ_{pers}\mathcal{L}_{pers} \tag{1} Ltotal=λbevLbev+λpersLpers(1)
3.4 改进的时间编码器
- BEVFormer 使用循环时间自注意力来合并历史 BEV 特征。但时间编码器无法利用长期时间信息,简单地将循环步骤从 4 增加到 16 不会产生额外的性能增益
- 通过使用简单的扭曲和连接策略重新设计了 BEVFormer v2 的时间编码器
- 给定不同帧 k 处的 BEV 特征 B k B_k Bk,首先根据帧 t 和帧 k 之间的参考帧变换矩阵 T k t = [ R ∣ t ] ∈ S E 3 T^t_k = [\mathbf{R}|\mathbf{t}] ∈ SE3 Tkt=[R∣t]∈SE3 将 B k B_k Bk 双线性扭曲到当前帧作为 B k t B^t_k Bkt
- 然后,沿着通道维度将先前的 BEV 特征与当前的 BEV 特征连接起来,并使用残差块来降维
- 为了保持与原始设计类似的计算复杂性,使用相同数量的历史 BEV 特征,但增加了采样间隔
- 除了受益于长期时间信息之外,新的时间编码器还解锁了在离线 3D 检测设置中利用未来 BEV 功能的可能性
3.5 两级 BEV 检测器
设计了一种新颖的结构,将两个头集成到一个两级预测管道中,即两级 BEV 检测器
- BEV 头部中的对象解码器是 DETR 解码器,使用一组学习的嵌入作为对象查询,通过训练了解目标对象可能位于的位置。然而,随机初始化的嵌入需要很长时间才能学习适当的位置
- 在推理过程中,所有图像的学习对象查询都是固定的,这可能不够准确,因为对象的空间分布可能会有所不同
解决方法
- 透视头的预测通过后处理进行过滤,然后融合到解码器的对象查询中,形成两阶段过程
- 这些混合对象查询提供了高分(概率)的候选位置,使 BEV 头部更容易在第二阶段捕获目标对象
- 应该注意的是,第一阶段的建议不一定来自透视检测器,例如来自另一个 BEV 检测器,但实验表明,只有透视的预测对第二阶段 BEV 头有帮助
3.6 具有混合对象查询的解码器
- 为了将第一阶段提案融合到第二阶段的对象查询中,BEVformer v2 中 BEV 头的解码器基于 BEVFormer 中使用的 Deformable DETR 解码器进行了修改
- 解码器由堆叠交替的自注意力层和交叉注意力层组成。交叉注意力层是一个可变形注意力模块[44],它将以下三个元素作为输入
- 内容查询:查询特征产生采样偏移量和注意力权重
- 参考点:值特征上的2D点作为每个查询的采样参考
- 价值特征:需要关注的BEV特征
在原始的 BEVFormer 中,内容查询是一组学习的嵌入,并且参考点是使用线性层从一组学习的位置嵌入中预测的。在 BEVformer v2 中,从透视头获取建议,并通过后处理选择其中的一部分
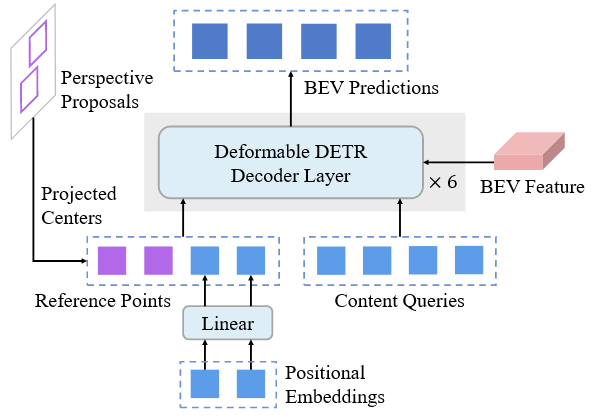
Fig.3 BEVFromer v2 中 BEV 头的解码器。第一阶段建议的投影中心用作每个图像的参考点(紫色的),并将它们与每个数据集学习的内容查询和位置嵌入(蓝色的)结合起来作为混合对象查询
- 所选提案的 BEV 平面上的投影框中心用作每个图像的参考点,并与位置嵌入生成的每个数据集的参考点相结合
- 每个图像的参考点直接指示物体在 BEV 平面上的可能位置,使解码器更容易检测目标物体
4. Experiments
4.1 数据集与指标
- 数据集:nuScenes
- 指标:五个真阳性指标,即 ATE、ASE、AOE、AVE 和 AAE,用于测量平移、缩放、分别是方向、速度和属性误差。此外,它还通过将检测精度 (mAP) 与五个真阳性指标相结合来定义 nuScenes 检测分数 (NDS)
4.2 实验设置
-
使用多种类型的主干网进行实验:ResNet、DLA、VoVNet 和 InternImage
-
所有主干网均使用在 COCO 数据集的 2D 检测任务上预先训练的检查点进行初始化
-
透视损失和 BEV 损失的损失权重设置为 λ b e v = λ p e r s = 1 λ_{bev} = λ_{pers} = 1 λbev=λpers=1。我们使用 AdamW 优化器,并将基础学习率设置为 4e-4
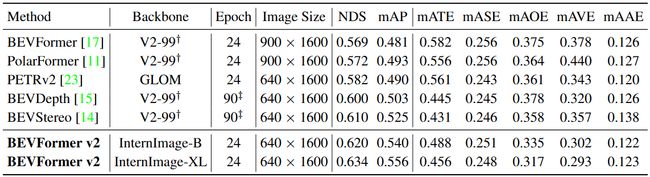
Tab.1 BEVFormer v2 和其他 SoTA 方法的 nuScenes 测试集上的 3D 检测结果。† 表明 V2-99 [13] 使用额外数据 [27] 在深度估计任务上进行了预训练。 ‡ 表示使用 CBGS 的方法,该方法会将 1 epoch 延长为 4.5 epoch。我们选择仅训练 BEVFormer v2 24 个时期,以便与以前的方法进行公平比较
4.3 基准测试结果
- 将提出的 BEVFormer v2 与现有最先进的 BEV 探测器进行比较,包括 BEVFormer 、PolarFormer、PETRv2、BEVDepth 和 BEVStereo
- 由表1可以看出:
- 具有 InternImage-B 主干的 BEVFormer v2 优于所有现有方法,这表明通过透视监督,不再需要在单目 3D 任务上预训练主干
- 采用 InternImage-XL 的 BEVFormer v2 以 63.4% NDS 和 55.6% mAP 的成绩超越了 nuScenes 相机 3D 异议排行榜上的所有条目,以 2.4% NDS 和 3.1% mAP 超过第二名的方法 BEVStereo。示了释放现代图像骨干力量用于 BEV 识别的巨大好处
4.4 消融和分析
4.4.1 透视监督的有效性
为了确认透视监督的有效性,将 3D 检测器与表中不同视图监督组合进行了比较
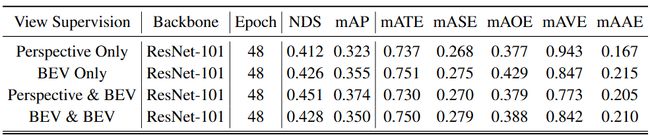
Tab.2 nuScenes val 集上具有不同视图监督组合的 3D 检测器的检测结果。所有模型均在没有时间信息的情况下进行训练
- 与 Perspective Only 检测器相比,BEV Only 检测器利用多视图图像实现了更好的 NDS 和 mAP,但其 mATE 和 mAOE 更高,表明了 BEV 监督的根本问题
- 透视和 BEV 检测器实现了最佳性能,并且优于仅 BEV 检测器
- 显着的改进主要来自以下两个方面
- 在正常视觉任务上预训练的主干网无法捕获3D场景中对象的一些属性,包括深度、方向和速度,而透视监督引导的主干网能够提取信息关于此类属性
- 与一组固定的对象查询相比,我们的混合对象查询包含第一阶段预测作为参考点,帮助 BEV 头部定位目标对象
4.4.2 透视监督的概括
所提出的透视监督预计将使不同架构和规模的骨干网受益
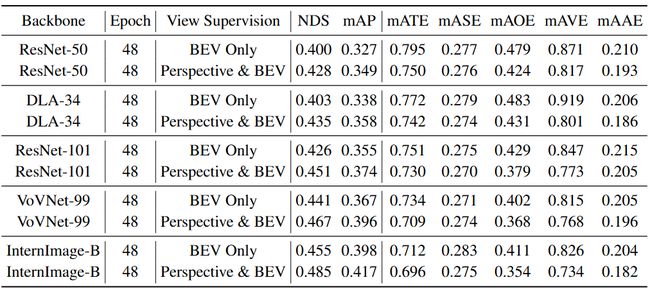
Tab.3 nuScenes val 集上不同 2D 图像主干的透视监督结果。 ‘BEV Only’和‘Perspective & BEV’与 Tab.2 相同. 所有骨干网均使用 COCO [20] 预训练权重进行初始化,并且所有模型均在没有时间信息的情况下进行训练
BEVForemr v2(BEV 和视角)将所有主干网的 NDS 提高了约 3%,mAP 提高了约 2%,这表明它可以推广到不同的架构和模型大小
4.4.3 训练选项
我们针对不同时期训练 BEV Only 模型和 BEVFormer v2(BEV 和 Perspective)
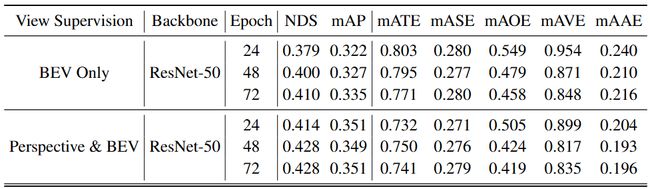
Tab.4 比较不同训练时期下仅使用 BEV 监督的模型以及同时使用 Perspective 和 BEV 监督的模型。这些模型在 nuScenes val 集上进行评估。所有模型都是在没有时间信息的情况下进行训练的
- BEV & Perspective 模型比 BEV Only 模型收敛得更快,证实辅助透视损失有助于优化
- 表明仅靠 BEV 监督无法很好地适应图像主干
4.4.4 检测头选项
BEVFormer v2 中可以使用各种类型的透视和 BEV 检测头
-
对于透视头,候选者是 DD3D 和 DETR3D ;对于 BEV 头,候选者是 Deformable DETR 和 Group DETR

Tab.5 BEVFormer v2 中透视头和 BEV 头不同选择的比较。这些模型在 nuScenes val 集上进行评估。所有模型都是在没有时间信息的情况下进行训练的
-
对于透视头,DD3D 比 DETR3D 更好
-
Group DETR head 是 Deformable DETR head 的扩展,它利用分组对象查询和每个组内的自注意力。 Group DETR 为 BEV 头实现了更好的性能,但需要更多的计算量
4.4.5 附加功能的消融
消除了 BEVFormer v2 中使用的附加功能,以确认它们对最终结果的贡献
- 图像级数据增强 (IDA),图像随机水平翻转
- 较长的时间间隔
- 双向时间编码器
- 透视监督

Tab.6 在 nuScenes val 集上对 BEVFormer v2 的附加功能进行消融研究。所有模型均使用 ResNet-50 主干网络和时间信息进行训练。 “Pers”、“IDA”、“Long”和“Bi”分别表示透视监督、图像级数据增强、长时间间隔和双向时间编码器
5. 总结
- 将通用 2D 图像主干网适应 BEV 检测器的优化问题。为了解决这个问题,我们通过从额外的视角 3D 检测头添加辅助损失,将视角监督引入到 BEV 模型中
- 将两个检测头集成为两级检测器,即BEVFormer v2。成熟的透视头提供第一阶段的对象建议,这些建议被编码到 BEV 头的对象查询中以进行第二阶段的预测
局限性
- 由于计算和时间限制,目前没有在更大规模的图像主干上测试本文的方法