python轻量规则引擎rule-engine入门与应用实践
rule-engine是一种轻量级、可选类型的表达式语言,具有用于匹配任意 Python 对象的自定义语法,使用python语言开发。
规则引擎表达式用自己的语言编写,在 Python 中定义为字符串。其语法与 Python 最相似,但也受到 Ruby 的一些启发。这种语言的一些特性包括:
- 可选类型提示
- 用正则表达式匹配字符串
- 日期时间数据类型
- 复合数据类型(相当于 Python 字典、列表和集合类型)
- 数据属性
- 线程安全
参考文档可在 https://zeroSteiner.github.io/rule-engine/ 获取。
规则语法
创建规则的语法基于计算为 True(匹配)或 False(不匹配)的逻辑表达式。规则支持一小组数据类型,这些数据类型可以定义为文字或使用应用规则的 Python 对象进行解析。有关受支持类型的完整列表,请参阅数据类型表。
并非所有受支持的操作都适用于下表所示的所有数据类型。规则遵循标准的操作顺序。
语法
表达式语法支持多种操作,包括数值数据的基本算术和字符串的正则表达式。操作是类型感知的,并且在使用不兼容的类型时会引发异常。
支持的操作
下表概述了可在规则引擎表达式中使用的所有运算符。
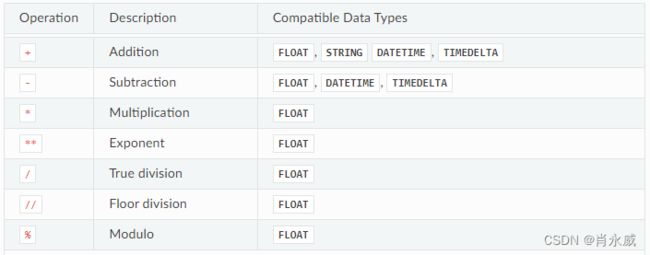
算术运算符
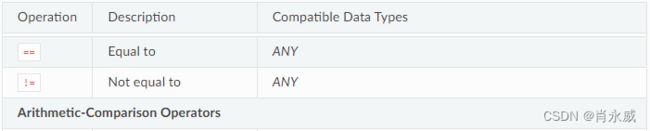
比较运算符
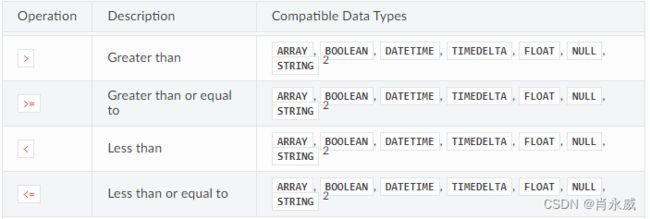
算术比较运算符
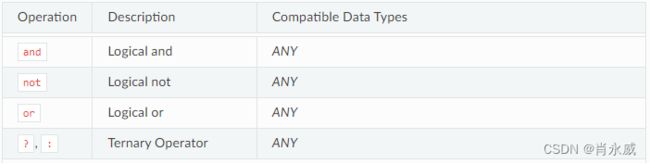
逻辑运算符
-
按位运算支持浮点值,但如果该值不是自然数,则会引发EvaluationError。
-
算术比较运算符支持多种数据类型,但左值的数据类型必须与右值的数据类型相同。例如,一个 STRING 可以与另一个 STRING 进行比较,但不能与 FLOAT 进行比较。该技术与 Python 使用的基于字典顺序的序列比较技术相同。
-
使用正则表达式操作时,左侧的表达式是要比较的字符串,右侧的表达式是用于匹配或搜索操作的正则表达式。
关于时间 DATETIME 值
DATETIME 文字必须以 ISO-8601 格式指定。底层解析逻辑由 dateutil.parser.isoparse() 提供。未指定时间的 DATETIME 值(例如 d"2019-09-23")将计算为指定日期的午夜整点的 DATETIME。
显示等效文字表达式的示例规则:
d"2019-09-23" == d"2019-09-23 00:00:00" (日期默认为午夜,除非指定时间)
安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple rule-engine
示例代码
示例1,官方示例
import rule_engine
# match a literal first name and applying a regex to the email
rule = rule_engine.Rule(
'first_name == "Luke" and email =~ ".*@rebels.org$"'
) # => 示例2,自定义

rule = rule_engine.Rule(
'num >= 20000 and num<=30000'
)
rule.matches({
'num': 2500
}) # True
rule = rule_engine.Rule(
'(num >= 2000 and num<=3000) or type=="cars"'
)
rule.matches({
'num': 1500,'type':'bus'
}) # False
示例3,过滤
改造此方法,可以实现示例2中,按条件获取得分值。
import datetime
comics = [
{
'title': 'Batman',
'publisher': 'DC',
'issue': 89,
'released': datetime.date(2020, 4, 28)
},
{
'title': 'Flash',
'publisher': 'DC',
'issue': 753,
'released': datetime.date(2020, 5, 5)
},
{
'title': 'Captain Marvel',
'publisher': 'Marvel',
'issue': 18,
'released': datetime.date(2020, 5, 6)
}
]
rule = rule_engine.Rule(
# match books published by DC
'publisher == "DC"'
)
for v in rule.filter(comics):
print(v)
print(v['title'])
{'title': 'Batman', 'publisher': 'DC', 'issue': 89, 'released': datetime.date(2020, 4, 28)}
Batman
{'title': 'Flash', 'publisher': 'DC', 'issue': 753, 'released': datetime.date(2020, 5, 5)}
Flash
示例4,另外一种方案
conditon=[['num >= 30000',40],
['num >= 20000 and num<30000',30],
['num >= 10000 and num<20000',20],
['num <10000',10]]
num = 13003
for v in conditon:
rule=rule_engine.Rule(v[0])
if rule.matches({'num':num}):
print(v[1])
break
总结
rule-engine做为一种轻量级规则引擎,在数据分析中做为条件规则使用,基本够用了。
参考:
Considerations for building a rules engine in Python. 2021.09
https://zerosteiner.github.io/rule-engine/index.html