JVM---垃圾回收器CMS 和G1解析
CMS 和G1解析
- CMS 和G1解析
- 基本概念
-
- CardTable
- CSet
- RSet(G1)
- CMS
-
- 清理过程
-
- 1. 初始标记(CMS-initial-mark)
- 2. 并发标记(CMS-concurrent-mark)
- 3. 重新标记(CMS-remark)
- 4.并发清理(CMS-concurrent-sweep)
- 线程角度理解
- G1
-
- 介绍
- G1特点
- 新老年代比例
- GC何时触发
- MixedGC
-
- MixedGC的过程
- 初始标记
- 并发标记
- 最终标记
- 筛选回收
- 相关问题
- 标记算法
-
- 三色标记算法
- 漏标
- 产生漏标
- 打破漏标
- RSet与赋值的效率
CMS 和G1解析
基本概念
JDK10之前都是串行的FullGC,所以调优的目标应该是尽量避免FullGC
CardTable
由于做YGC时,需要扫描整个OLD区,效率非常低,所以JVM设计了CardTable, 如果一个OLD区CardTable中有对象指向Y区,就将它设为Dirty,下次扫描时,只需要扫描Dirty Card
在结构上,Card Table用BitMap来实现
详细介绍
Java虚拟机用了一个叫做CardTable(卡表)的数据结构来标记老年代的某一块内存区域中的对象是否持有新生代对象的引用,卡表的数量取决于老年代的大小和每张卡对应的内存大小,每张卡在卡表中对应一个比特位,当老年代中的某个对象持有了新生代对象的引用时,JVM就把这个对象对应的Card所在的位置标记为dirty(bit位设置为1),这样在Minor GC时就不用扫描整个老年代,而是扫描Card为Dirty对应的那些内存区域。
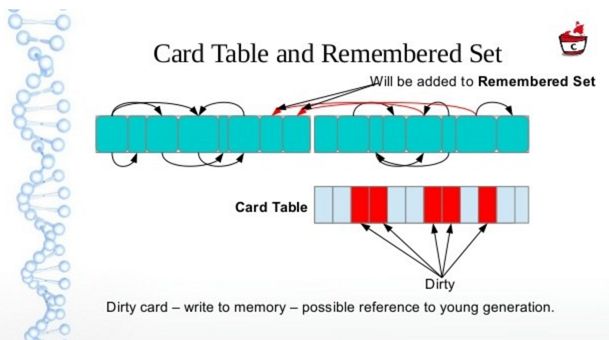
这样子可以提高效率减少MinorGC的停顿时间。
在JVM中,一个Card的大小是512字节,在多个线程并行收集时,JVM通过ParGCCardsPerStrideChunk参数设置每个线程每次扫描的Card数量,默认是256,相当于是把老年代分成许多strides,每个线程每次扫描一个stride,每个stride大小为512*256 = 128K,如果你的老年代大小为4G,那总共有4G/128K=32K个Strides。多线程在扫描这么多的strides时就涉及到调度和分配的问题,stride数量太多就会导致线程在stride之间切换的开销增加,进而导致GC暂停时间增长。因此JVM提供了ParGCCardsPerStrideChunk这个参数来配置每个stride对应的card数量,这个数量要根据实际的业务场景进行调优,网上一般流传3个魔术数字:32768、4K和8K。
-XX:+UnlockDiagnosticVMOptions
-XX:ParGCCardsPerStrideChunk=4096
这个值不能设置的太大,因为GC线程需要扫描这个stride中老年代对象持有的新生代对象的引用,如果只有少量引用新生代的对象那就导致浪费了很多时间在根本不需要扫描的对象上。
CSet

G1中的CSet, 需要被回收的对象会撞到一个表格里, 这个表就叫CSet
RSet(G1)
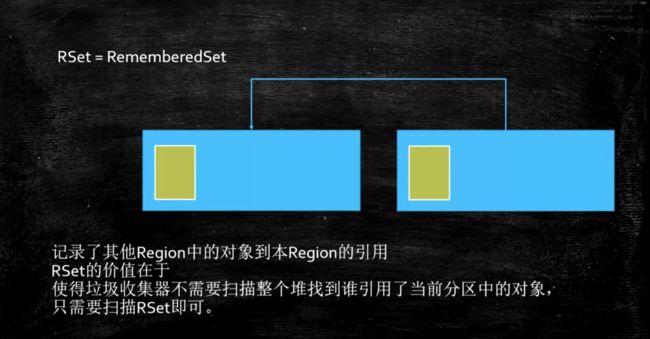
G1: 每一个Region里都有一个表格,本质上是个hashTable,记录了其他Region中的对象对本Region的引用。这是后面三色标记算法实现的关键。
CMS
CMS大的阶段可分为以下四个
- 初始标记(CMS-initial-mark) ,会导致stw;
- 并发标记(CMS-concurrent-mark),与用户线程同时运行;
- 重新标记(CMS-remark) ,会导致swt;
- 并发清理(CMS-concurrent-sweep),与用户线程同时运行

清理过程
1. 初始标记(CMS-initial-mark)
首先找到gc roots ,即找到根对象, 这一阶段是stw的, 由于这一级的对象比较少, 所以stw时间非常短
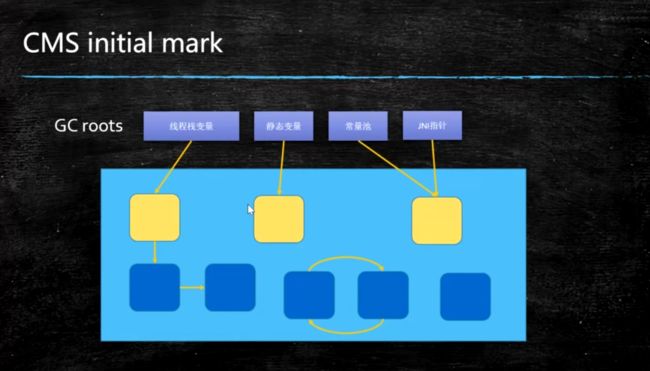
2. 并发标记(CMS-concurrent-mark)
初始标记完之后, 开始进行并发标记,这一阶段也是最耗时的阶段, 所以是和程序中其他线程并行执行的, 不会导致STW,
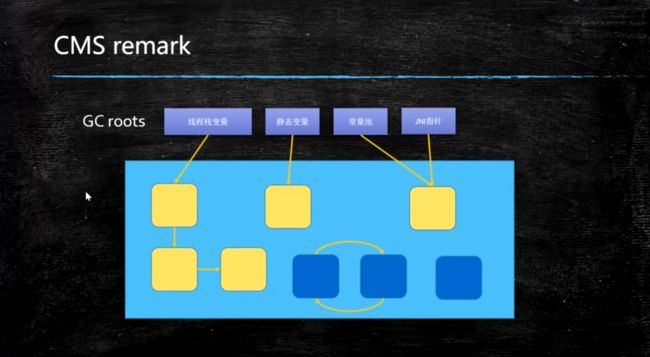
3. 重新标记(CMS-remark)
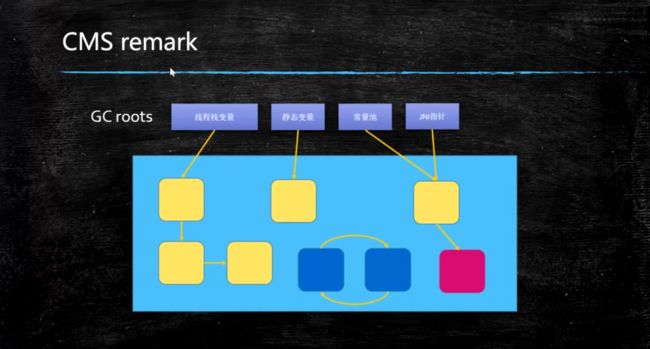
在并发标记阶段, 如果有对象被重新引用,会对其进行重新标记,就比如右下角的这个对象, 被gc roots 引用, 所以被标记。
4.并发清理(CMS-concurrent-sweep)
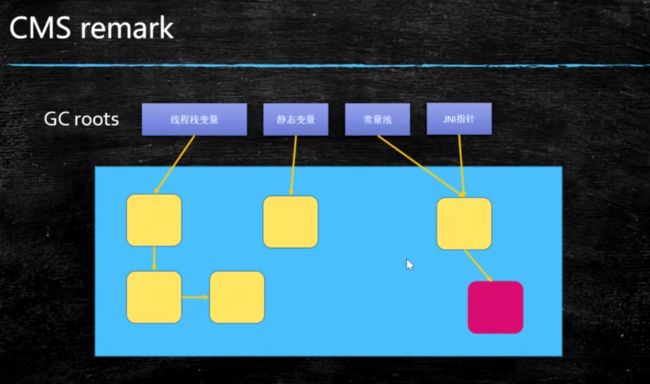
并发标记完成后,对没有标记到的对象进行清理。
线程角度理解
最开始,在工作线程在工作,不断产生垃圾,内存使用到一定程度后,会触发初始标记,初始标记阶段是STW的, 但是由于根对象比较少, 所以这里STW的时间非常短。
接下来从根对象往下找引用, 这个阶段是最消耗时间的, 所以这里使用到并发标记, 和工作线程可一起进行,
这这个阶段,有些对象可能被标记完之后, 没有了引用指向它,就变成了垃圾,有些垃圾,有了新的引用指向了它,不再是垃圾,所以,在并发标记完成之后,找到这些漏标的,进行一次重新标记。在重新标记阶段,由于改动不是很多, 所以,虽然这个阶段是STW的, 但是它的耗时不是很长。
最后,进行并发清理, 在清理过程中,也会产生垃圾, 这些垃圾就叫浮动垃圾, 这些垃圾会在下一下的清理过程中被清理掉。
G1
介绍
官方文档: https://www.oracle.com/technical-resources/articles/java/g1gc.html
The Garbage First Garbage Collector (G1 GC) is the low-pause, server-style generational garbage collector for Java HotSpot VM. The G1 GC uses concurrent and parallel phases to achieve its target pause time and to maintain good throughput. When G1 GC determines that a garbage collection is necessary, it collects the regions with the least live data first (garbage first).
翻译:该垃圾首先垃圾收集器(GC G1)是Java HotSpot虚拟机的低暂停,服务器风格的分代垃圾收集器。G1 GC 使用并发和并行阶段来实现其目标暂停时间并保持良好的吞吐量。当 G1 GC 确定需要进行垃圾回收时,它会先收集活动数据最少的区域(垃圾优先)。
G1是一种服务端应用使用的垃圾收集器, 目标是用在多核,大内存的机器上,他在大多数情况下可以实现指定的GC暂停时间,同时还能保持较高的吞吐量。
在G1之前,堆内存所使用的垃圾收集器都是逻辑和物理都分代的,而G1是逻辑分代, 但是物理不分代的垃圾收集器。
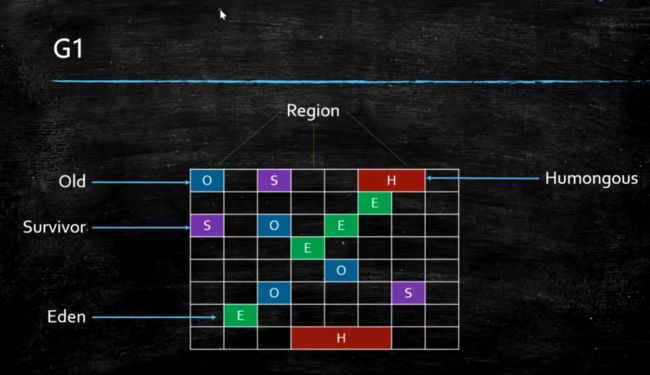
Old:存放老年代对象
Survivor:存放经过垃圾回收之后依然存活的对象
Eden:新创建的对象
Humongous:存放大对象,有可能会占用多个连续的Region
由此可见,G1的内存模型已经和之前的分代模型完完全全不一样了。
G1特点
G1和CMS的并发收集算法很相似, 都是三色标记, 但是到了JDK11的ZGC就不一样了, 他用的是颜色指针(color pointer)
颜色指针扩展:待补充
G1的内存区域不是固定的Eden区或者Old区

新老年代比例
-
5%-60%
一般不需要手工指定
也不要手工指定,因为这是G1预测停顿时间的基准
GC何时触发

MixedGC
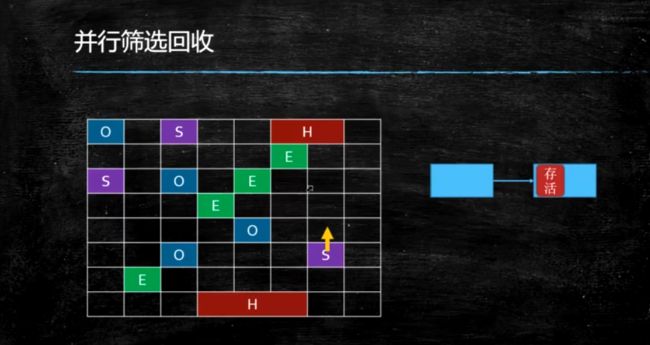
当堆内存占用超过一定比例, 默认是45%(这个比例可调),就会触发MixedGC,MixedGC的过程类似CMS的垃圾回收过程,
MixedGC的过程

初始标记
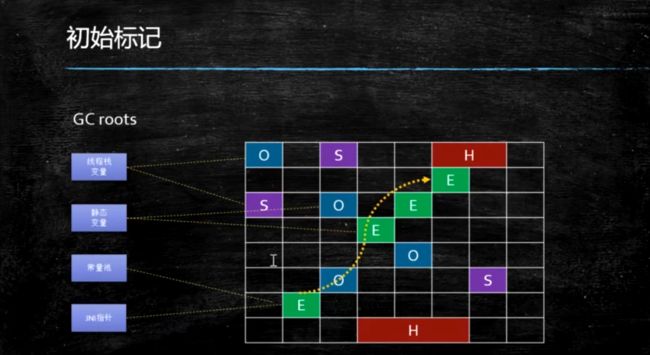
并发标记
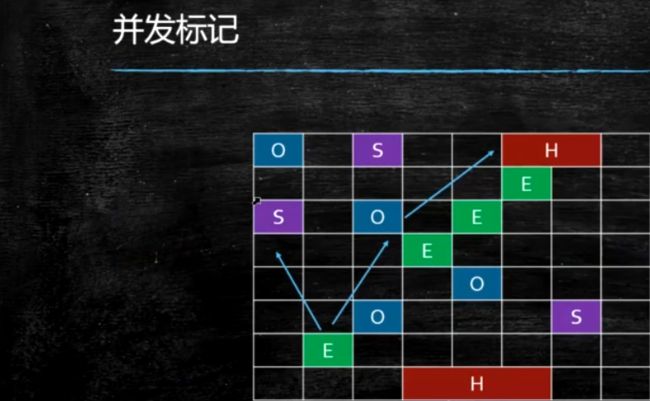
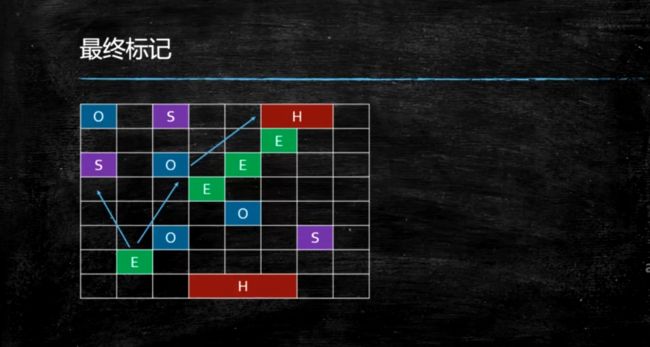
最终标记
筛选回收
相关问题
如果G1产生FGC,你应该做什么?
- 扩内存
- 提高CPU性能(回收的快,业务逻辑产生对象的速度固定,垃圾回收越快,内存空间越大)
- 降低MixedGC触发的阈值,让MixedGC提早发生(默认是45%)
标记算法
三色标记算法
在CMS和G1中用的标记算法都是三色标记算法

漏标
含义: 漏标是指,本来是live object, 但是由于没有遍历到,被当成garbage回收掉了。
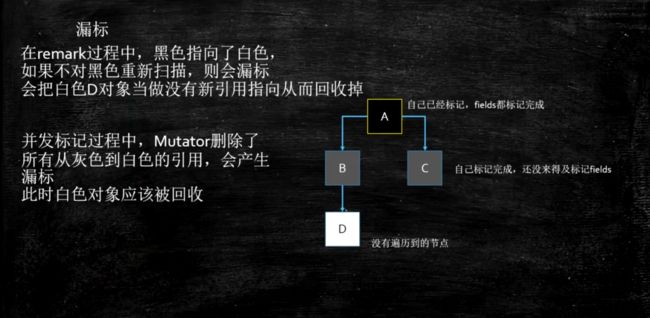
漏标: 黑色指向了白色, 与此同时, 白色的原来的引用没了。
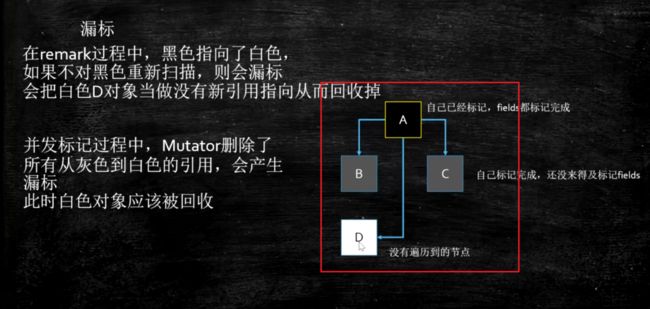
产生漏标
- 标记进行时增加了一个黑到白的引用,如果不重新对黑色进行处理, 则会漏标
- 标记进行时删除了一个灰对白的引用,那么这个白对象有可能被漏标
打破漏标
- 跟踪A指向D的增加
- 跟踪B指向D的消失
打破漏标的算法

- incremental update – 增量更新,关注引用的增加,把黑色重新标记为灰色,下次重新扫描属性(CMS使用)
- SATB snapshot at the beginning - 关注引用的删除,当B->D消失时,要把这个引用推到GC的堆栈,保证D还能被GC扫描到。(G1使用)
为什么G1使用STAB?
灰色->白色引用消失时,如果没有黑色执行白色,引用会被push到堆栈
下次扫描时拿到这个引用,由于有RSet的存在,不需要扫描整个堆去查找指向白色的引用,效率比较高,SATB配合RSet,浑然天成。
RSet与赋值的效率
由于RSet的存在,那么每次给对象赋引用的时候,就得做一些额外的操作,指的是在RSet中做一些额外的记录(在GC中被称为写屏障)
注意: 这个写屏障不等于内存屏障