Prometheus 发现机制和告警
1.服务发现
Prometheus Server的数据抓取工作于Pull模型,因而,它必需要事先知道各Target的位置,然后才能从相应的Exporter或Instrumentation中抓取数据。在不同的场景下,需要结合不同的机制来实现对应的数据抓取目的。
对于小型的系统环境来说,通过static_configs指定各Target便能解决问题,这也是最简单的配置方法,我们只需要在配置文件中,将每个Targets用一个网络端点(ip:port)进行标识;
因此,Prometheus为此专门设计了一组服务发现机制,以便于能够基于服务注册中心自动发现、检测、分类可被监控的各Target,以及更新发生了变动的Target各个节点会主动注册相关属性信息到服务注册中心,即使属性发生变动,注册中心的属性也会随之更改。
一旦节点过期了,或者失效了,服务注册中心,会周期性的方式自动将这些信息清理出去。服务发现机制对于prometheus的服务发现机制,这里面提供了二十多种服务发现机制,常见的几种机制如下:
| 方法 | 解析 |
|---|---|
| 基于文件的服务发现 | 简单来说,将各target记录到文件中,prometheus启动后,周期性刷新这个文件,从而获取最新的target |
| 基于DNS的服务发现 | 针对一组DNS域名进行定期查询,以发现待监控的目标,并持续监视相关资源的变动 |
| 基于API的服务发现 | 支持将API Server中Node、Service、Endpoint、Pod和Ingress等资源类型下相应的各资源对象视作target,并持续监视相关资源的变动 |
| 基于HTTP的服务发现 | 基于 HTTP 的服务发现提供了一种更通用的方式来配置静态目标,并用作插入自定义 |
| 服务发现机制的接口。它从包含零个或多个 |
1.1 文件服务
1.1.1 文件发现服务说明
基于文件的服务发现是仅仅略优于静态配置的服务发现方式,它不依赖于任何平台或第三方服务,因而也是最为简单和通用的实现方式
文件发现原理
- Prometheus Server定期从文件中加载Target信息
文件可使用YAML和JSON格式,它含有定义的Target列表,以及可选的标签信息
YAML 适合于运维场景, JSON 更适合于开发场景
- 这些文件可由另一个系统生成,例如Ansible或Saltstack等配置管理系统,也可能是由脚本基于CMDB定期查询生成
#1.准备主机节点列表文件,可以支持yaml格式和json格式
cat targets/prometheus*.yaml
- targets:
- master1:9100
labels:
app: prometheus
#2.配置文件自动加载实现自动发现
cat prometheus.yml
......
- job_name: 'prometheus'
file_sd_configs:
- files: # 指定要加载的文件列表;
- targets/prometheus*.yaml # 文件加载支持glob通配符,支持yaml和json两种格
式
refresh_interval: 2m # 每隔2分钟重新加载一次文件中定义的Targets,默
认为5m
#注意:文件格式都是yaml格式
1.1.2 文件发现实验
恢复最初的配置yaml
#创建发现的目录
root@promethues(192.168.1.20)/data/prometheus/prometheus_cfg>mkdir targets
root@promethues(192.168.1.20)/data/prometheus/prometheus_cfg>ls
prometheus.yml targets
root@promethues(192.168.1.20)/data/prometheus/prometheus_cfg>
#创建目标主机
root@promethues(192.168.1.20)/data/prometheus/prometheus_cfg/targets>ls
prometheues-node.yml prometheues-server.yml
root@promethues(192.168.1.20)/data/prometheus/prometheus_cfg/targets>cat prometheues-node.yml
- targets:
- 192.168.1.20:9100
labels:
app: prometheus
job: prometheus
- targets:
- 192.168.1.10:9100
- 192.168.1.11:9100
labels:
app: node-exporter
job: node
root@promethues(192.168.1.20)/data/prometheus/prometheus_cfg/targets>cat prometheues-server.yml
- targets:
- 192.168.1.20:9090
labels:
app: prometheus-server
job: prometheus-server
root@promethues(192.168.1.20)/data/prometheus/prometheus_cfg/targets>
#配置prometheus的配置文件,让它自动加载文件中的节点信息
root@promethues(192.168.1.20)/data/prometheus/prometheus_cfg>cat prometheus.yml
global:
scrape_interval: 15s
external_labels:
monitor: 'codelab-monitor'
scrape_configs:
- job_name: 'prometheus'
file_sd_configs:
- files:
- targets/prometheues-server.yml
refresh_interval: 2m
- job_name: 'node_exporter'
file_sd_configs:
- files:
- targets/prometheues-node.yml
refresh_interval: 2m

#后续可以自由的编辑文件,无需重启prometheus服务,就可以做到自动发现的效果
#添加linux主机目标
root@promethues(192.168.1.20)/data/prometheus/prometheus_cfg/targets>cat prometheues-node.yml
- targets:
- 192.168.1.20:9100
labels:
app: prometheus
job: prometheus
- targets:
- 192.168.1.11:9100
- 192.168.1.10:9100
- 192.168.1.12:9100
labels:
app: node-exporter
job: node
#文件保存后,稍等几秒钟,最慢1分钟,他会自动加载当前的配置文件里面的信息,查看一下浏览器
#结果显示:节点的自动服务发现成功了。以后,对所有节点批量管理的时候,借助于ansible等工具,就可以非常轻松的搞定所有了

报红是因为我的12机器没有启动
2. 告警
2.1 告警组件
告警能力在Prometheus的架构中被划分成两个独立的部分。
通过在Prometheus中定义AlertRule(告警规则),Prometheus会周期性的对告警规则进行计算,如果满足告警触发条件就会向Alertmanager发送告警信息。
然后,Alertmanager管理这些告警,包括进行重复数据删除,分组和路由,以及告警的静默和抑制。当Alertmanager接收到 Prometheus 端发送过来的 Alerts 时,Alertmanager 会对Alerts 进行去复,分组,按标签内容发送不同报警组,包括:邮件,微信,Webhook。AlertManager还提供了静默和告警抑制机制来对告警通知行为进行优化。

说白了就是在Prometheus中配置告警规则role,当触发这个规则的时候,alertmanager去通知报警。
2.2 告警特性
- 去重
将多个相同的告警,去掉重复的告警,只保留不同的告警
- 分组
分组机制可以将详细的告警信息合并成一个通知。在某些情况下,比如由于系统宕机导致大量的告警被同时触发,在这种情况下分组机制可以将这些被触发的告警合并为一个告警通知,避免一次性接受大量的告警通知,而无法对问题进行快速定位。
告警分组,告警时间,以及告警的接受方式可以通过Alertmanager的配置文件进行配置。
- 路由
将不同的告警定制策略路由发送至不同的目标
- 抑制
抑制可以避免当某种问题告警产生之后用户接收到大量由此问题导致的一系列的其它告警通知同样通过Alertmanager的配置文件进行设置。
- 静默
静默提供了一个简单的机制可以快速根据标签对告警进行静默处理。如果接收到的告警符合静默的配置,Alertmanager则不会发送告警通知。静默设置需要在Alertmanager的Web页面上进行设置。
2.3 报警部署Alertmanager
2.3.1 软件安装配置
root@promethues(192.168.1.20)~>tar xf alertmanager-0.25.0.linux-amd64.tar.gz -C /usr/local/
root@promethues(192.168.1.20)~>ln -s /usr/local/alertmanager-0.25.0.linux-amd64 /usr/local/alertmanager
root@promethues(192.168.1.20)~>cd /usr/local/alertmanager
root@promethues(192.168.1.20)/usr/local/alertmanager>ls
alertmanager* alertmanager.yml amtool* LICENSE NOTICE
root@promethues(192.168.1.20)/usr/local/alertmanager>mkdir {bin,conf,data}
root@promethues(192.168.1.20)/usr/local/alertmanager>mv alertmanager amtool bin
root@promethues(192.168.1.20)/usr/local/alertmanager>mv alertmanager.yml conf
root@promethues(192.168.1.20)/usr/local/alertmanager>
2.3.2 邮箱报警配置文件修改
cat /usr/local/alertmanager/conf/alertmanager.yml
# 全局配置
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.163.com:25'
smtp_from: '[email protected]'
smtp_auth_username: '[email protected]'
smtp_auth_password: 'xxxxxx'
smtp_hello: '163.com'
smtp_require_tls: false
# 路由配置
route:
group_by: ['alertname', 'cluster']
group_wait: 10s
group_interval: 10s
repeat_interval: 10s #此值不要过低
receiver: 'email'
# 收信人员
receivers:
- name: 'email'
email_configs:
- to: '[email protected]'
send_resolved: true #问题解决后也会发送告警
# 抑制规则,如果不想用可以去掉
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
#属性解析:repeat_inerval配置项,用于降低告警收敛,减少报警,发送关键报警,对于email来说,此
项不可以设置过低,否则将会由于邮件发送太多频繁,被smtp服务器拒绝
2.3.3 启动服务文件
cat /usr/lib/systemd/system/alertmanager.service
[Unit]
Description=alertmanager project
After=network.target
[Service]
Type=simple
ExecStart=/usr/local/alertmanager/bin/alertmanager --config.file=/usr/local/alertmanager/conf/alertmanager.yml --storage.path=/usr/local/alertmanager/data --web.listen-address=0.0.0.0:9093
Restart=on-failure
[Install]
WantedBy=multi-user.target
#属性解析:最好配置 --web.listen-address ,因为默认的配置是:9093,有可能在启动时候报错
#启动服务
systemctl daemon-reload
systemctl enable --now alertmanager.service
systemctl status alertmanager.service
root@promethues(192.168.1.20)/usr/local/alertmanager>netstat -tnulp | egrep 'Pro|ale'
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp6 0 0 :::9093 :::* LISTEN 20774/alertmanager
tcp6 0 0 :::9094 :::* LISTEN 20774/alertmanager
udp6 0 0 :::9094 :::* 20774/alertmanager
root@promethues(192.168.1.20)/usr/local/alertmanager>
两个端口9093(与prometheus交互端口)和9094(Alertmanager集群HAmode使用)

2.3.4 在Prometheus中配置alertmanager
#修改配置文件,加载alertmanager配置属性
root@promethues(192.168.1.20)/usr/local/alertmanager>vim /data/prometheus/prometheus_cfg/prometheus.yml
global:
scrape_interval: 15s
external_labels:
monitor: 'codelab-monitor'
alerting:
alertmanagers:
- static_configs:
- targets: ["192.168.1.20:9093"]
scrape_configs:
- job_name: 'prometheus'
file_sd_configs:
- files:
- targets/prometheues-server.yml
refresh_interval: 2m
- job_name: 'node_exporter'
file_sd_configs:
- files:
- targets/prometheues-node.yml
refresh_interval: 2m
#注意:alertmanager服务启动时候的监控开放主机地址必须保证正确,否则服务启动不起来
#检查语法
/etc/prometheus $ promtool check config prometheus.yml
Checking prometheus.yml
SUCCESS: prometheus.yml is valid prometheus config file syntax


2.4 告警规则
2.4.1 告警规则说明
警报规则可以实现基于Prometheus表达式语言定义警报条件,并将有关触发警报的通知发送到外部服务。 只要警报表达式在给定的时间点生成一个或多个动作元素,警报就被视为这些元素的标签集处于活动状态。
警报规则在Prometheus中的基本配置方式与记录规则基本一致。
规则文件示例
groups:
- name: example
rules:
- alert: HighRequestLatency
expr: job:request_latency_seconds:mean5m{job="myjob"} > 0.5
for: 10m
labels:
severity: warning
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been
down for more than 1 minutes."
#属性解析:
alert 定制告警的动作名称
for expr #条件表达式被触发后,一直持续满足该条件长达此处的时间后才会告警
labels.severity 定义告警级别
annotations 自定义注释信息,注释信息中的变量需要从模板中或者系统中读取
在Prometheus中一条告警规则主要由以下几部分组成:
- 告警名称:用户需要为告警规则命名,当然对于命名而言,需要能够直接表达出该告警的主要内容
- 告警规则:告警规则实际上主要由PromQL进行定义,其实际意义是当表达式(PromQL)查询结果持续多长时间(During)后出发告警
在Prometheus中,还可以通过Group(告警组)对一组相关的告警进行统一定义。当然这些定义都是通过YAML文件来统一管理的。
2.4.2 配置告警规则
编写一个检查自定义metrics的接口的告警规则,在prometheus中我们可以借助于up指标来获取对应的状态效果,查询语句如下:
up{instance="192.168.1.11:9100",job="node"}
#注意:如果结果是1表示服务正常,否则表示该接口的服务出现了问题。
 2.4.2.1 编写告警规则
2.4.2.1 编写告警规则
配置rule_files
global:
scrape_interval: 15s
external_labels:
monitor: 'codelab-monitor'
alerting:
alertmanagers:
- static_configs:
- targets: ["192.168.1.20:9093"]
rule_files:
- "../rules/*.yml"
scrape_configs:
- job_name: 'prometheus'
file_sd_configs:
- files:
- targets/prometheues-server.yml
refresh_interval: 2m
- job_name: 'node_exporter'
file_sd_configs:
- files:
- targets/prometheues-node.yml
refresh_interval: 2m
编写告警规则
root@promethues(192.168.1.20)/data/prometheus/prometheus_cfg>mkdir rules
root@promethues(192.168.1.20)/data/prometheus/prometheus_cfg>cd rules/
root@promethues(192.168.1.20)/data/prometheus/prometheus_cfg/rules>cat prometheus_rules.yml
groups:
- name: test_web
rules:
- alert: InstanceDown
expr: up{job="node"} == 0
for: 1m
labels:
severity: 1
annotations:
summary: "Instance {{ $labels.instance }} 停止工作"
description: "{{ $labels.instance }} job {{ $labels.job }} 已经停止1分钟以上"
#属性解析:
{{ $labels.<labelname> }} 要插入触发元素的标签值
{{ $value }} 要插入触发元素的数值表达式值
这里的$name 都是来源于模板文件中的定制内容,如果不需要定制的变动信息,可以直接写普通的字符串
重启docker prometheus
告警状态
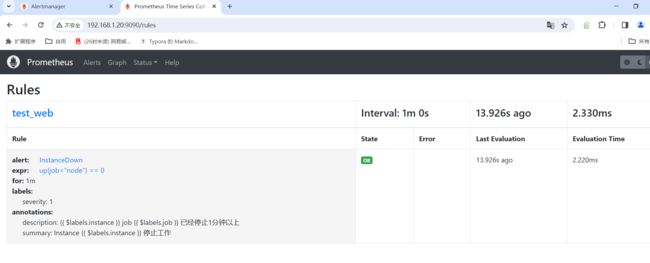
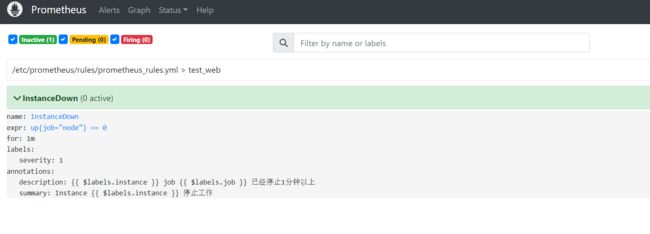
- Inactive:正常效果
- Pending:已触发阈值,但未满足告警持续时间(即rule中的for字段)
- Firing:已触发阈值且满足告警持续时间。
2.4.3 验证结果
因为监测的是端口是否存活 只需要把11机器的9100端口关闭
查看prometheus

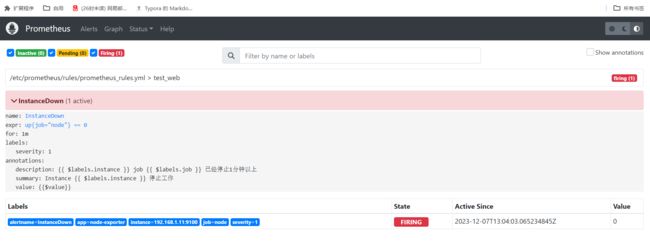
等待时间超过for持续的标准后,就会改变告警的状态,效果如下
 查看alertmanager的web效果
查看alertmanager的web效果
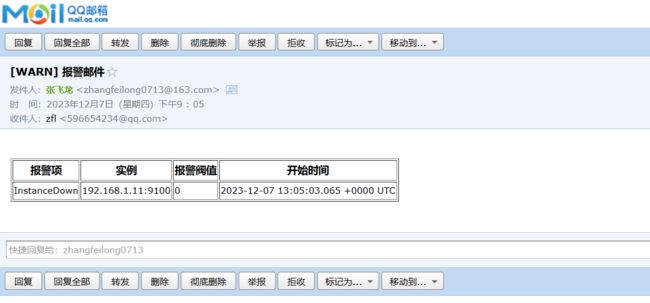
邮件告警效果
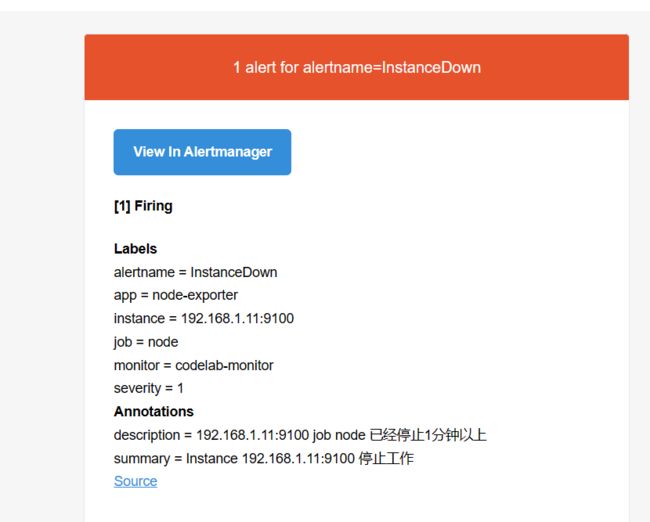
3. 告警模板
3.1 告警模板说明
默认的告警信息界面有些简单,可以借助于告警的模板信息,对告警信息进行丰富。需要借助于alertmanager的模板功能来实现
使用流程:
- 分析关键信息
- 定制模板内容
- alertmanager 加载模板文件
- 告警信息使用模板内容属性
3.2 定制模板
模板文件使用标准的Go语法,并暴露一些包含时间标签和值的变量
标签引用: {{ $label.<label_name> }}
指标样本值引用: {{ $value }}
3.2.1 建立邮件模板
root@promethues(192.168.1.20)/data/prometheus/prometheus_cfg/targets>cd /usr/local/alertmanager
root@promethues(192.168.1.20)/usr/local/alertmanager>ls
bin/ conf/ data/ LICENSE NOTICE
root@promethues(192.168.1.20)/usr/local/alertmanager>mkdir tmpl
root@promethues(192.168.1.20)/usr/local/alertmanager>cd tmpl/
root@promethues(192.168.1.20)/usr/local/alertmanager/tmpl>ls
root@promethues(192.168.1.20)/usr/local/alertmanager/tmpl>
root@promethues(192.168.1.20)/usr/local/alertmanager/tmpl>cat email.tmpl
{{ define "test.html" }}
<table border="1">
<tr>
<th>报警项</th>
<th>实例</th>
<th>报警阀值</th>
<th>开始时间</th>
</tr>
{{ range $i, $alert := .Alerts }}
<tr>
<td>{{ index $alert.Labels "alertname" }}</td>
<td>{{ index $alert.Labels "instance" }}</td>
<td>{{ index $alert.Annotations "value" }}</td>
<td>{{ $alert.StartsAt }}</td>
</tr>
{{ end }}
</table>
{{ end }}
#属性解析
{{ define "test.html" }} 表示定义了一个 test.html 模板文件,通过该名称在配置文件中应用
上边模板文件就是使用了大量的jinja2模板语言。
$alert.xxx 其实是从默认的告警信息中提取出来的重要信
3.2.2 将告警模板应用起来
在alertmanager应用
# 全局配置
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.163.com:25'
smtp_from: '[email protected]'
smtp_auth_username: '[email protected]'
smtp_auth_password: 'OAQCKHLQGOUTHHGN'
smtp_hello: '163.com'
smtp_require_tls: false
templates: #新增模板目录
- '../tmpl/*.tmpl'
# 路由配置
route:
group_by: ['alertname', 'cluster']
group_wait: 10s
group_interval: 10s
repeat_interval: 10s
receiver: 'email'
# 收信人员
receivers:
- name: 'email'
email_configs:
- to: '[email protected]'
send_resolved: true
headers: { Subject: "[WARN] 报警邮件"} #添加此行,定制邮件标题
html: '{{ template "test.html" . }}' #添加此行,调用模板显示邮件正文
# 抑制规则,如果不想用可以去掉
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
{{}} 属性用于加载其它信息,所以应该使用单引号括住
{} 不需要使用单引号,否则服务启动不成功
3.2.3 修改rule规则
root@promethues(192.168.1.20)/data/prometheus/prometheus_cfg/rules>cat prometheus_rules.yml
groups:
- name: test_web
rules:
- alert: InstanceDown
expr: up{job="node"} == 0
for: 1m
labels:
severity: 1
annotations:
summary: "Instance {{ $labels.instance }} 停止工作"
description: "{{ $labels.instance }} job {{ $labels.job }} 已经停止1分钟以上"
value: "{{$value}}"
#属性解析:这里在注释部分增加了一个value的属性信息,会从prometheus的默认信息中获取阈值
#annotations这部分内容不再显示邮件中,而按模板形式显示
进行测试
关闭11机器的9100端口