大数据--- 14.MapReduce的本地操作和集群计算与打包到hadoop运行
MapReduce的本地操作和集群计算与打包到hadoop运行
通过MapReduce处理本地手机销量
1.通过MapReduce来操作我们上面文件的统计;其实就是使用框架来做计算;他的优点就是吧之前我们处理数据和;合并数据的部分分别通过类来帮我们实现;只需要我们传递参数:
具体代码:
package mapreduce;
import org.apache.commons.io.FileUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.File;
import java.io.IOException;
public class WordCount02 {
//LongWritable, Text map输入端 永远不变 writable 实现了序列化
//Text, IntWritable 根据具体需求定义
//map端 静态的内部类 (hadoop,1)
public static class MapTask extends Mapper{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取数据 一行一行
String[] words = value.toString().split(",");
//拿到每一个单词 拼接写出去 context: 专门用来往出写数据
for (String word : words) { //(hadoop,1)
context.write(new Text(word),new IntWritable(1));
}
}
}
//reduce端 静态内部类 (hadoop,34566)
public static class ReduceTask extends Reducer{
@Override // hadoop (1,1,1,1,1,1,1....)
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int count=0;
for (IntWritable value : values) {
count ++;
}
//写出去
context.write(key,new IntWritable(count));
}
}
//main方法测试
public static void main(String[] args) throws Exception {
//我们需要一盒hadoop的对象去提交这俩个内部类 Job 本地运行
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//提交那俩个内部类
job.setMapperClass(MapTask.class);
job.setReducerClass(ReduceTask.class);
job.setJarByClass(WordCount02.class);
//设置四个输出参数的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//如果输出文件 存在 就删除
String output="e:/BigData";
File file = new File(output);
if(file.exists()){
FileUtils.deleteDirectory(file);
}
//设置输入 输出路径
FileInputFormat.addInputPath(job,new Path("e:/hfc001.txt"));
FileOutputFormat.setOutputPath(job,new Path(output));
//温馨提示
boolean b = job.waitForCompletion(true);
System.out.println(b?"老铁,没毛病!!!":"哥们,出BUG了,赶快去调一下!!!");
}
}
这个地方就是直接通过了框架对我们这里的数据进行了统计:
但是运行代码的时候会报错:
Exception in thread “main“ java.io.IOException: (null) entry in command string: null

解决方法:
添加 hadoop.dll文件 到系统的system32文件夹中:
hadoop.dll 文件
链接: https://pan.baidu.com/s/1V6aA4J7T2N-1ivp_wkqgZw 提取码: ncva

然后运行代码:会在我们的bigdata文件中生成:
直接使用记事本打开:


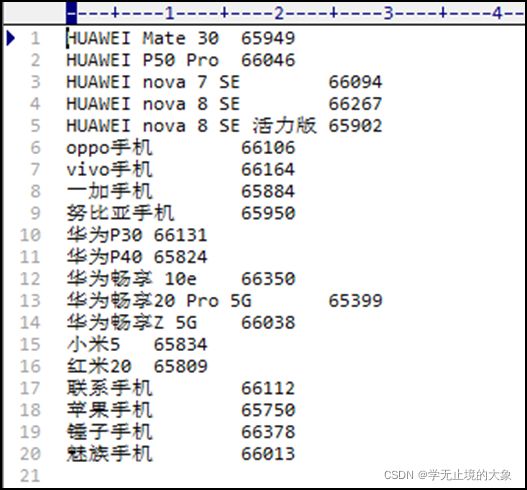
如果有问题:配置下hadoop的windows的环境变量;
我们一般都是要把我们的日志要打印上: 就是要创建一个文件log4j.propertis
这个文件中的内容:
#log4j.rootLogger日志输出类别和级别:只输出不低于该级别的日志信息DEBUG < INFO < WARN < ERROR < FATAL
#A1是一个“形参”代表输出位置,具体的值在下面
log4j.rootLogger=DEBUG, A1
配置A1输出到控制台
log4j.appender.A1=org.apache.log4j.ConsoleAppender
配置A1设置为自定义布局模式
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
配置日志的输出格式 %r耗费毫秒数 %p日志的优先级 %t线程名 %C所属类名通常为全类名 %x线程相关联的NDC %m日志 %n换行
log4j.appender.A1.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
你把idea直接重启;或者把他clear一下;
在集群中使用 MapReduce来进行计算;
-
启动你的集群: start-all.sh
注意: 1.防火墙必须关闭;2.同步时间;3.免密登录; -
启动集群:(保证我们集群能够正常的启动 ;nameNode; dataNode)

-
使用命令行方式对你的文件夹进行操作;
最简单的方式使用:Java代码: 使用下面的方法来进行创建文件夹和上传文件
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.*;
import java.net.URI;
public class HadoopHdfsTest {
/这个是我们创建出来的一个对象; 就是文件操作的对象/
private FileSystem fileSystem=null;
/*这个就是我们的单元测试中的一个注解;在所有方法前执行*/
@Before
public void before()throws Exception{ //在他里边进行你的fileSystem 的初始化
fileSystem=FileSystem.get(new URI("hdfs://192.168.64.120:9000"),
new Configuration(), "root");
System.out.println("当前的这个对象已经初始化完毕:"+fileSystem);
}
/*关闭资源的方法*/
@After
public void after()throws Exception{ // 这个方法是在你所有的方法执行完毕之后执行
if (fileSystem!=null){ //判断的是你的当前这个对象为不为空
fileSystem.close();
}
}
/*1.具体的操作---在你的hdfs中进行创建文件夹的操作*/
@Test
public void mkdir() throws Exception{
boolean flag = fileSystem.mkdirs(new Path("/bigdata/input"));
System.out.println("你的文件夹已经创建成功!!!!");
}
// 删除目录
@Test
public void delDir() {
try {
boolean result = fileSystem.delete(new Path("/bigdata/inputhfc001.txt"), true);
System.out.println("删除文件夹成功!!!");
} catch (IOException e) {
System.out.println("删除文件夹失败!!!");
}
}
// 遍历所有文件
@Test
public void filelist() {
try {
final FileStatus[] fileStatuses = fileSystem.listStatus(new Path("/hfc/"));
for (FileStatus file:fileStatuses) {
System.out.println(file.getPath().getName()+"\t"+file.getBlockSize()+"\t"+file.isFile());
System.out.println("------------------------------------------------");
}
} catch (IOException e) {
e.printStackTrace();
}
}
// 文件上传
@Test
public void upfile() {
String filename = "hfc001.txt";
InputStream inputStream = null;
OutputStream outputStream = null;
try {
inputStream = new FileInputStream("e:/" + filename);
outputStream = fileSystem.create(new Path("/bigdata/input/" + filename));
IOUtils.copyBytes(inputStream, outputStream, 4096, true);
System.out.println("上传文件成功!!!!");
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
System.out.println("上传文件失败!!!!");
e.printStackTrace();
} finally {
if (inputStream != null) {
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (outputStream != null) {
try {
outputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
// 文件下载
@Test
public void dowmfile() {
String hdfsFileName = "hfc.txt";
String downFileName = "hfc001.txt";
InputStream inputStream = null;
OutputStream outputStream = null;
try {
inputStream = fileSystem.open(new Path("/zhangjiajie/"+hdfsFileName));
outputStream = new FileOutputStream("c:/" + downFileName);
IOUtils.copyBytes(inputStream, outputStream, 4096);
System.out.println("下载文件成功!");
} catch (IOException e) {
System.out.println("现在文件成功!!!");
e.printStackTrace();
} finally {
if (inputStream != null) {
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (outputStream != null) {
try {
outputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}

4.修改我们的这个代码(mapreduce代码:)
package mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCount003 {
//map
public static class MapTask extends Mapper
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] words = value.toString().split(“,”);
//拿到每一个单词 拼接写出去 context: 专门用来往出写数据
for (String word : words) { //(hadoop,1)
context.write(new Text(word),new IntWritable(1));
}
}
}
//reduce
public static class ReduceTask extends Reducer{
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int count=0;
for (IntWritable value : values) {
count ++;
}
//写出去
context.write(key,new IntWritable(count));
}
}
//main
public static void main(String[] args) throws Exception {
//我们需要一盒hadoop的对象去提交这俩个内部类 Job 本地运行
System.setProperty("HADOOP_USER_NAME","root");
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.64.120:9000");
Job job = Job.getInstance(conf);
//提交那俩个内部类
job.setMapperClass(MapTask.class);
job.setReducerClass(ReduceTask.class);
job.setJarByClass(WordCount003.class);
//设置四个输出参数的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//如果输出文件 存在 就删除
String output="/bigdata/output/wordcount3";
// String output=args[1];
FileSystem fileSystem = FileSystem.get(conf);
if(fileSystem.exists(new Path(output))){
fileSystem.delete(new Path(output),true);
}
//设置输入 输出路径
FileInputFormat.addInputPath(job,new Path("/bigdata/input/hfc001.txt"));
// FileInputFormat.addInputPath(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(output));
//温馨提示
boolean b = job.waitForCompletion(true);
System.out.println(b?"老铁,没毛病!!!":"哥们,出BUG了,赶快去修改一下!!!");
}
}
只要他运行起来就成功;

你可以直接下载这个文件看看里边的统计信息;
2. 使用命令来查看:hadoop fs -cat /bigdata/output/wordcount3/par*

在你的集群上是好的了