深入理解网络 I/O:FileOutputStream、BufferFileOutputStream、ByteBuffer

嗨,您好 我是 vnjohn,在互联网企业担任 Java 开发,CSDN 优质创作者
推荐专栏:Spring、MySQL、Nacos、Java,后续其他专栏会持续优化更新迭代
文章所在专栏:网络 I/O
我当前正在学习微服务领域、云原生领域、消息中间件等架构、原理知识
向我询问任何您想要的东西,ID:vnjohn
觉得博主文章写的还 OK,能够帮助到您的,感谢三连支持博客
代词: vnjohn
⚡ 有趣的事实:音乐、跑步、电影、游戏
目录
- 前言
- FileOutputStream
-
- 代码
- strace
- BufferFileOutputStream
-
- 源码
- 代码
- strace
- FileOutput VS BufferFileOutput
- ByteBuffer
-
- 介绍
- 使用
- 如何使用 ByteBuffer 操作文件
- 代码
- strace
- 总结
前言
在 Java API 中,应用 I/O 有不同的方式,本文会从三种不同方向的 I/O 来介绍写的操作,分别是:FileOutputStream、BufferFileOutputStream、RandomAccessFile
FileOutputStream:普通 I/O 写
BufferFileOutputStream:以一个 Buffer 缓冲的方式写
RandomAccessFile:以指针的方式向前推进读或写,该类的实例支持对随机访问文件的读写
同时会以 strace 追踪日志内容的方式,来分析它们在内核是如何操作的,有无进行用户态内核态切换或者何时进行这个切换动作的
FileOutputStream
FileOutputStream 对应的是文件输出流,FileInputStream 是文件输入流
文件输出流是将数据写入 File 或 FileDescriptor-FD 文件描述符的输出流中,FileOutputStream 通过字节流的方式进行写入,对于字符流的写入,可以使用 FileWriter
文件输入流是从文件系统中的文件中获取输入的字节,可用的文件取决于主机的环境,FileInputStream 用于读取原始字节流,如:图像数据,对于字符流的读取,可以使用 FileReader
代码
下面通过一段简单的代码来使用 FileOutputStream
import java.io.File;
import java.io.FileOutputStream;
/**
* 普通文件 IO 写
*
* @author vnjohn
* @since 2023/12/18
*/
public class NormalFileIO {
static byte[] DATA = "1234567890\n".getBytes();
static String PATH = "/opt/io/normal/out.txt";
public static void main(String[] args) throws Exception {
File file = new File(PATH);
FileOutputStream out = new FileOutputStream(file);
while (true) {
// 模拟业务代码,让文件慢点写数据
Thread.sleep(10);
out.write(DATA);
}
}
}
指定一个要写入字节流的文件输出流:/opt/io/normal/out.txt,开启一个循环不断的往这个文件里写入数据,再循环中使用 Thread#sleep 方法来模拟业务代码的执行
strace
将源文件放入到 Linux 虚拟机节点进行编译执行
1、javac NormalFileIO.java
2、创建目录:/opt/io/normal
3、strace 追踪:strace -ff -o normal_out java NormalFileIO
让它运行一段时间以后,通过:jps 命令查看有哪些 java 进程在运行,通过它的 pid 号+1 就能知道 normal_out 文件前缀的后缀是什么了.
通过 tail -f /opt/io/normal_out.pid 一直观察窗口是否滚动

可以看到通过 FIleOutputStream 输出流是每调用一次 write 方法都会触发一次系统调用函数:write,也就是每调用一次就触发了一次用户态和内核态的切换,这种方式会极其的影响用户程序的资源和性能。
BufferFileOutputStream
BufferFileOutputStream:该类实现了一个缓冲的输出流,通过设置这样的输出流,应用程序可以将字节写入输出流中,而不必每个写入的字节或每一段写入的字节调用系统函数
它是以一个 buffer 大小进行写入的,当字节总数大于或等于这个 buffer 设置的字节数,那么它就会触发一次系统调用,将它写入到文件中.
源码
BufferFileOutputStream 它提供了两个构造函数,当我们传入一个 FileOutputStream 输出流对象时,在其内部会对其做一层处理,观察如下的方法实现:
// 存储数据的缓冲区
protected byte buf[];
// 计数器:缓冲区的有效字节数,0-buf.length 范围
protected int count;
// 创建一个 8KB 缓冲输出流
public BufferedOutputStream(OutputStream out) {
this(out, 8192);
}
// 创建一个自定义字节大小的缓冲输出流,比如:1024、2048、4096
public BufferedOutputStream(OutputStream out, int size) {
super(out);
if (size <= 0) {
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size];
}
/**
* 将指定字节写入缓冲输出流中.
*
* @param b 要写入的字节
* @exception IOException if an I/O error occurs.
*/
public synchronized void write(int b) throws IOException {
if (count >= buf.length) {
flushBuffer();
}
buf[count++] = (byte)b;
}
/** 将数据真正触发系统调用写入到文件中后计数器归为 0 */
private void flushBuffer() throws IOException {
if (count > 0) {
out.write(buf, 0, count);
count = 0;
}
}
在默认的情况下,缓冲输出流是以一个8KB 大小进行写入文件的,而在触发 write 方法时不是像 FileOutputStream 一样立马触发写操作的,而是先判断缓冲区字节数的大小是否超过要写入的长度,超过了立马触发系统调用 write 操作,未超过则将其存入到本地的字节数组中.
所以在使用它的时候,要计算出你本次要写入文件的大小是多少再进行构造,若小于默认的 8KB 时,你永远在文件中是看不到这些要写入的信息的,你需要手动调用 BufferFileOutputStream#flush 方法触写入操作
代码
通过以下简单的代码来使用 BufferFileOutputStream
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileOutputStream;
/**
* @author vnjohn
* @since 2023/12/18
*/
public class BufferFileIO {
static byte[] DATA = "1234567890\n".getBytes();
static String PATH = "/opt/io/buffer/out.txt";
public static void main(String[] args) throws Exception {
File file = new File(PATH);
// 将 FileOutput 包装为 BufferedOutput
BufferedOutputStream out = new BufferedOutputStream(new FileOutputStream(file));
while (true) {
// 模拟业务代码执行时间
Thread.sleep(10);
out.write(DATA);
}
}
}
以默认 8KB 字节大小的批次进行写入文件,对 FileOutputStream 进行了一层包装,底层用的是它,但是在操作时使用的是 BufferedOutputStream
strace
通过在 Linux 虚拟机节点中编译以上的源码来观察内核源码的执行情况
1、javac BufferFileIO.java
2、mkdir /opt/io/buffer
3、strace 追踪:strace -ff -o buffer_out java BufferFileIO
运行以下命令后,通过 tail -f buffer_out.pid 文件,来查看它的运行轨迹,运行结果如下图:
可以观察到等待了很多(直到 8KB 写满)才触发系统函数:write 调用,将其写入到文件中,对比普通 I/O 写 Buffer I/O 方式在性能上以及资源的利用上减少了很多
FileOutput VS BufferFileOutput
在 Buffer 方式下写它的效率一定是会比普通 File 方式写要快很多的
因为通过以上的例子来看,它们两者的区别在用户态与内核态之间的切换次数不同:buffer < 普通 file
Buffer 在 JVM 中是先以 8KB 字节数组存储起来满了以后再调用内核写入到内存的,但是普通 File 它是每一次 write 写入都会触发一次用户态与内核态的切换
普通 File 写
write(4, "1234567890\n", 11) = 11
Buffer 写
write(5, "1234567890\n1234567890\n1234567890"..., 8184) = 8184
ByteBuffer
ByteBuffer 是 Java NIO 中用于操作字节数据的缓冲区类之一,它提供了一种方便的方式来处理字节数据,支持读取、写入、操作和管理字节数据.

介绍
主要的特点和功能
- ByteBuffer 有固定的容量(capacity — 可容纳的字节总数)同时它还有一个位置(position — 下一个要读取或写入的位置)
- ByteBuffer 可以在读取模式和写入模式之间切换,在读取模式下,可以从缓冲区中读取数据;在写入模式下,它可以将数据写入缓冲区
- ByteBuffer 提供了许多方法用于读取和写入数据,如:get、put 等,这些方法允许你读取或写入单个字节、字符、整数、长整数、浮点数等各种数据类型
- ByteBuffer 支持不同的字节顺序,可以通过 order 方法来设置字节顺序,包括大端序、小端序
- ByteBuffer 与通道(Channel)配合使用,例如:FileChannel、SocketChannel 用于文件和网络 I/O 操作
- 通过 FileChannel 可以内存映射文件写入,通过 MappedByteBuffer 将文件内容映射到内存中,以便在内存中进行读写操作
ByteBuffer 类主要的方法及其简要说明,如下:
- allocate(int capacity):创建一个新的字节缓冲区,其容量为指定大小的字节数,分配的是应用程序 JVM 堆空间,例如:ByteBuffer buffer = new ByteBuffer.allocate(1024);
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
return new HeapByteBuffer(capacity, capacity);
}
- allocateDirect(int capacity):创建一个新的直接字节缓冲区,其容量为指定大小的字节数,直接缓冲区将在本地内存(Native Memory)中进行分配,适用于需要高性能的场景
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}
- put(byte b):将指定的字节写入缓冲区的当前位置,例如:buffer.put((byte)65);
public final ByteBuffer put(byte[] src) {
return put(src, 0, src.length);
}
// 会将 position 向右移动 1 字节
public ByteBuffer put(byte[] src, int offset, int length) {
checkBounds(offset, length, src.length);
if (length > remaining())
throw new BufferOverflowException();
int end = offset + length;
for (int i = offset; i < end; i++)
this.put(src[i]);
return this;
}
- putInt(int value):将指定的整数按照当前的字节顺序写入到缓冲区,例如:buffer.putInt(123);
public ByteBuffer putInt(int x) {
// position 会向右移动 4 位
Bits.putInt(this, ix(nextPutIndex(4)), x, bigEndian);
return this;
}
- get():读取缓冲区当前位置的字节,然后将 position 向前/右移动一个字节,例如:byte b = buffer.get();
public byte get() {
// position = p + 1;
return hb[ix(nextGetIndex())];
}
- getInt():从缓冲区的当前 position 读取四个,并根据当前字节顺序返回一个整数,例如:int value = buffer.getInt();
public int getInt() {
return Bits.getInt(this, ix(nextGetIndex(4)), bigEndian);
}
- flip():将缓冲区从写入模式切换为读取模式,该方法会将 limit 设置为当前 position,然后将 position 重置为 0
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
- compact():调用该方法后,缓冲区的位置 position 会被设置为未读取数据的末尾,限制 limit 会被设置为容量 capacity,以便进行后续的写入操作
public ByteBuffer compact() {
System.arraycopy(hb, ix(position()), hb, ix(0), remaining());
position(remaining());
limit(capacity());
discardMark();
return this;
}
- clear():清空缓冲区,将 position 设置为 0,limit 设置为 capacity,准备重新写入缓冲区
public final Buffer clear() {
position = 0;
limit = capacity;
mark = -1;
return this;
}
- rewind():将 position 设置为 0,不改变 limit,这样可以重新读取缓冲区中的数据
public final Buffer rewind() {
position = 0;
mark = -1;
return this;
}
使用
import java.nio.ByteBuffer;
/**
* @author vnjohn
* @since 2023/12/20
*/
public class StudyByteBuffer {
public static void main(String[] args) {
whatByteBuffer();
}
public static void whatByteBuffer() {
// JVM 堆内分配
// ByteBuffer buffer = ByteBuffer.allocate(1024);
// Java 进程堆内分配、JVM 堆外分配 > 直接内存-与操作系统内存交互的
ByteBuffer buffer = ByteBuffer.allocateDirect(1024);
System.out.println("position: " + buffer.position());
System.out.println("limit: " + buffer.limit());
System.out.println("capacity: " + buffer.capacity());
System.out.println("mark: " + buffer);
System.out.println("------------- put:123 -------------");
buffer.put("123".getBytes());
System.out.println("------------- putInt:123 -------------");
buffer.putInt(123);
System.out.println("mark: " + buffer);
// 读写交替:读取之前先要 flip
System.out.println("------------- flip -------------");
buffer.flip();
System.out.println("mark: " + buffer);
// 取一个字节:position 位置向右移
buffer.get();
System.out.println("------------- get -------------");
buffer.getInt();
System.out.println("------------- getInt -------------");
System.out.println("mark: " + buffer);
System.out.println("------------- rewind -------------");
buffer.rewind();
System.out.println("mark: " + buffer);
// 写操作:从未读取的位置开始重新写入
System.out.println("------------- compact -------------");
buffer.compact();
System.out.println("mark: " + buffer);
System.out.println("------------- clear -------------");
buffer.clear();
System.out.println("mark: " + buffer);
}
}
运行 main 方法,控制台输出如下:
position: 0
limit: 1024
capacity: 1024
mark: java.nio.DirectByteBuffer[pos=0 lim=1024 cap=1024]
------------- put:123 -------------
------------- putInt:123 -------------
mark: java.nio.DirectByteBuffer[pos=7 lim=1024 cap=1024]
------------- flip -------------
mark: java.nio.DirectByteBuffer[pos=0 lim=7 cap=1024]
------------- get -------------
------------- getInt -------------
mark: java.nio.DirectByteBuffer[pos=5 lim=7 cap=1024]
------------- rewind -------------
mark: java.nio.DirectByteBuffer[pos=0 lim=7 cap=1024]
------------- compact -------------
mark: java.nio.DirectByteBuffer[pos=7 lim=1024 cap=1024]
------------- clear -------------
mark: java.nio.DirectByteBuffer[pos=0 lim=1024 cap=1024]
如何使用 ByteBuffer 操作文件
在说明使用 ByteBuffer 如何读、写、映射文件系统中的文件时,先介绍除了 ByteBuffer 之外的核心类
- RandomAccessFile:Java I/O 中的类,用于随机访问文件的内容,它允许在文件中读取和写入数据,支持对文件的随机访问,可以定位到读写的位置
RandomAccessFile 可以以读取和写入的模式打开文件,并允许以任意位置读取或写入数据,因此适用于需要随机访问文件内容的场景
通过 RandomAccessFile#getChannel 方法可以获取对应的 FileChannel 对象
核心方法:
1、read()、write():从文件读取数据到缓冲区、将数据写入文件
2、seek(long position):定位文件指针到指定位置,以进行随机访问
3、getFilePointer:获取当前文件指针的位置
4、length():获取文件的长度
5、close():关闭文件流
- FileChannel:Java NIO(java.nio.channels)中的类,提供了对文件的读写操作,但是它是在 FileChannel 上进行操作而不是直接读写文件,它是与底层操作系统的文件 I/O 操作进行交互的通道
FileChannel 支持顺序读写、随机读写、文件锁定等操作,提供了更高效的文件 I/O 操作,并可以与 MappedByteBuffer 配合使用进行数据的交互
核心方法:
1、read(ByteBuffer dst):从通道读取数据到缓冲区
2、write(ByteBuffer src):将缓冲区的数据写入通道
3、position(long newPosition):设置通道为当前位置
4、size():获取通道对应文件的大小
5、map(FileChannel.MapMode mode, long position, long size):将文件区域映射到内存中后返回 MappedByteBuffer 对象
6、lock()、tryLock():对文件区域进行加锁
7、close():关闭通道
- MappedByteBuffer:MappedByteBuffer 是 ByteBuffer 中的一种特殊实现,通过 FileChannel#map 方法进行创建,它是直接在内存中映射文件的一部分或全部内容,允许直接在内存中对文件进行读写操作
它将文件内容映射到内存中,并且允许对映射区域进行修改,同时修改会同步更新到文件中
1、get()、put():从缓冲区读取数据、将数据写入缓冲区
2、load()、force():将文件内容加载到内存、将修改内容强制写入到文件中
3、isLoaded():检查缓冲区是否已加载到内存
4、isDirect():检查缓冲区是否是直接缓冲区
RandomAccessFile 提供了对文件的基本读写能力,FileChannel 提供了更高效的文件操作方式,而 MappedByteBuffer 允许直接在内存中对文件内容进行操作.
三者结合,天衣无缝,先打开文件->用高效的 I/O 读写方式->再以缓冲区的方式进行写
各自应用到了它们的优势
代码
import java.io.RandomAccessFile;
import java.nio.ByteBuffer;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
/**
* @author vnjohn
* @since 2023/12/18
*/
public class MMapFileNIO {
static String PATH = "/opt/io/mmap/out.txt";
public static void main(String[] args) throws Exception {
RandomAccessFile randomAccessFile = new RandomAccessFile(PATH, "rw");
System.out.println("-------- write --------");
randomAccessFile.write("hello \n".getBytes());
randomAccessFile.write("study every day\n".getBytes());
// 偏移到指定的位置{5}后追加内容
System.out.println("-------- seek ---------");
randomAccessFile.seek(5);
randomAccessFile.write("vnjohn".getBytes());
// FileChannel 依赖于 RandomAccessFile
FileChannel fileChannel = randomAccessFile.getChannel();
// mmap:调用 FileChannel#map 方法映射出一块用户态->内核态之间的共享区域,分配 4KB 大小
MappedByteBuffer map = fileChannel.map(FileChannel.MapMode.READ_WRITE, 0, 4096);
map.put("@".getBytes());
// mmap 内存映射,仍然受内核的 page cache 体系所约束的
System.out.println("-------- mmap#put --------");
// 强制将对该缓冲区内容所做的任何更改写入
// map.force();
randomAccessFile.seek(0);
ByteBuffer buffer = ByteBuffer.allocate(8192);
// 随机写入完毕的文件再读入到一个给定的字节缓冲区中
System.out.println("ByteBuffer#read:" + buffer);
fileChannel.read(buffer);
// 在开始读取内容时,需要调用 flip 方法归位
buffer.flip();
System.out.println("ByteBuffer#flip:" + buffer);
// 读取字节缓冲区,从 0-buffer.size 这个区间的内容
for (int i = 0; i < buffer.limit(); i++) {
Thread.sleep(200);
System.out.print(((char) buffer.get(i)));
}
}
}
strace
通过在 Linux 虚拟机节点中编译以上的源码来观察内核源码的执行情况
1、javac MMapFileNIO.java
2、mkdir /opt/io/mmap
3、strace 追踪:strace -ff -o mmap_out java MMapFileNIO
运行以下命令后,通过 tail -f mmap_out.pid 文件,来查看它的运行轨迹,运行结果如下图(只关注 mmap):
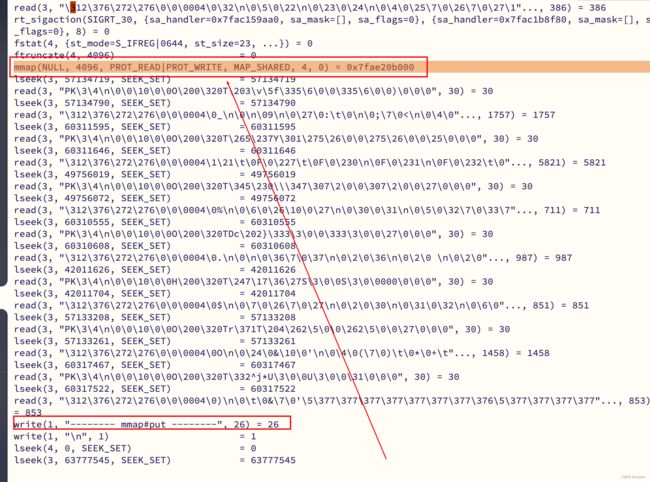
发现 FileChannel#map 方法映射出一块用户态与内核态之间共享的内存区域,底层调用的就是 mmap 函数.
总结
该篇博文主要介绍了 FileOutputStream、BufferFileOutputStream、ByteBuffer 类的特征,简要介绍了如何使用它们进行文件与内存之间的操作,FileOutStream 每次写都会触发系统调用,BufferFileOutStream 以一个批次的方式触发系统调用,而 ByteBuffer 下有很多种实现,HeapByteBuffer 是属于 JVM 堆内的一块内存区域,DirectByteBuffer 是属于 Java 进程堆内也就是 JVM 堆外的一块内存区域,MappedByteBuffer 它是直接操作用户空间与内核空间的一块共享区域,以上的实现它们都是基于操作系统的页缓存进行操作文件及网络 I/O 的,它们在极端的情况下都会丢失数据
MappedByteBuffer 运用了 mmap 系统函数调用,实现了零拷贝次数(减少了用户态与内核态之间的切换同时也减少了上下文切换的次数)
下篇文章会具体介绍 mmap、sendfile、Direct I/O 特征以及它们在 Java 中如何进行操作
希望您能够喜欢该篇博文提供的知识点篇章,感谢三连支持❤️
愿你我都能够在寒冬中相互取暖,互相成长,只有不断积累、沉淀自己,后面有机会自然能破冰而行!
博文放在 网络 I/O 专栏里,欢迎订阅,会持续更新!
如果觉得博文不错,关注我 vnjohn,后续会有更多实战、源码、架构干货分享!
推荐专栏:Spring、MySQL,订阅一波不再迷路
大家的「关注❤️ + 点赞 + 收藏⭐」就是我创作的最大动力!谢谢大家的支持,我们下文见!