hive企业级调优策略之如何用Explain查看执行计划
Explain执行计划概述
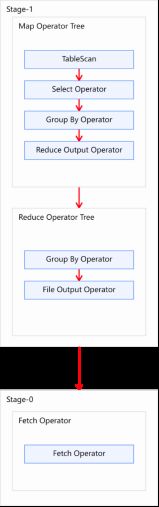
Explain呈现的执行计划,由一系列Stage组成,这一系列Stage具有依赖关系,每个Stage对应一个MapReduce Job,或者一个文件系统操作等。
若某个Stage对应的一个MapReduce Job,其Map端和Reduce端的计算逻辑分别由Map Operator Tree和Reduce Operator Tree进行描述,Operator Tree由一系列的Operator组成,一个Operator代表在Map或Reduce阶段的一个单一的逻辑操作,例如TableScan Operator,Select Operator,Join Operator等。
下图是由一个执行计划绘制而成:
常见的Operator及其作用如下:
TableScan:表扫描操作,通常map端第一个操作肯定是表扫描操作
Select Operator:选取操作
Group By Operator:分组聚合操作
Reduce Output Operator:输出到 reduce 操作
Filter Operator:过滤操作
Join Operator:join 操作
File Output Operator:文件输出操作
Fetch Operator 客户端获取数据操作
基本语法
EXPLAIN [FORMATTED | EXTENDED | DEPENDENCY] query-sql
注:FORMATTED、EXTENDED、DEPENDENCY关键字为可选项,各自作用如下。
FORMATTED:将执行计划以JSON字符串的形式输出
EXTENDED:输出执行计划中的额外信息,通常是读写的文件名等信息
DEPENDENCY:输出执行计划读取的表及分区
案例实操
查看下面这条语句的执行计划
explain FORMATTED
select
user_id,
count(*)
from order_detail
group by user_id;
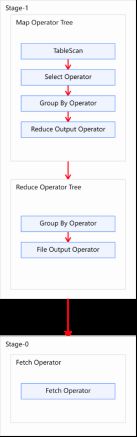
{"STAGE DEPENDENCIES":{"Stage-1":{"ROOT STAGE":"TRUE"},"Stage-0":{"DEPENDENT STAGES":"Stage-1"}},"STAGE PLANS":{"Stage-1":{"Map Reduce":{"Map Operator Tree:":[{"TableScan":{"alias:":"order_detail","columns:":["user_id"],"database:":"demodata","Statistics:":"Num rows: 13066777 Data size: 11760099340 Basic stats: COMPLETE Column stats: NONE","table:":"order_detail","isTempTable:":"false","OperatorId:":"TS_0","children":{"Select Operator":{"expressions:":"user_id (type: string)","columnExprMap:":{"BLOCK__OFFSET__INSIDE__FILE":"BLOCK__OFFSET__INSIDE__FILE","INPUT__FILE__NAME":"INPUT__FILE__NAME","ROW__ID":"ROW__ID","create_time":"create_time","dt":"dt","id":"id","product_id":"product_id","product_num":"product_num","province_id":"province_id","total_amount":"total_amount","user_id":"user_id"},"outputColumnNames:":["user_id"],"Statistics:":"Num rows: 13066777 Data size: 11760099340 Basic stats: COMPLETE Column stats: NONE","OperatorId:":"SEL_7","children":{"Group By Operator":{"aggregations:":["count()"],"columnExprMap:":{"_col0":"user_id"},"keys:":"user_id (type: string)","mode:":"hash","outputColumnNames:":["_col0","_col1"],"Statistics:":"Num rows: 13066777 Data size: 11760099340 Basic stats: COMPLETE Column stats: NONE","OperatorId:":"GBY_8","children":{"Reduce Output Operator":{"columnExprMap:":{"KEY._col0":"_col0","VALUE._col0":"_col1"},"key expressions:":"_col0 (type: string)","sort order:":"+","Map-reduce partition columns:":"_col0 (type: string)","Statistics:":"Num rows: 13066777 Data size: 11760099340 Basic stats: COMPLETE Column stats: NONE","value expressions:":"_col1 (type: bigint)","OperatorId:":"RS_9"}}}}}}}}],"Execution mode:":"vectorized","Reduce Operator Tree:":{"Group By Operator":{"aggregations:":["count(VALUE._col0)"],"columnExprMap:":{"_col0":"KEY._col0"},"keys:":"KEY._col0 (type: string)","mode:":"mergepartial","outputColumnNames:":["_col0","_col1"],"Statistics:":"Num rows: 6533388 Data size: 5880049219 Basic stats: COMPLETE Column stats: NONE","OperatorId:":"GBY_4","children":{"File Output Operator":{"compressed:":"false","Statistics:":"Num rows: 6533388 Data size: 5880049219 Basic stats: COMPLETE Column stats: NONE","table:":{"input format:":"org.apache.hadoop.mapred.SequenceFileInputFormat","output format:":"org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat","serde:":"org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe"},"OperatorId:":"FS_6"}}}}}},"Stage-0":{"Fetch Operator":{"limit:":"-1","Processor Tree:":{"ListSink":{"OperatorId:":"LIST_SINK_10"}}}}}}
执行计划如下图