pytorch文本分类(三)模型框架(DNN&textCNN)
pytorch文本分类(三)模型框架(DNN&textCNN)
原任务链接
目录
- pytorch文本分类(三)模型框架(DNN&textCNN)
-
- 1. 背景知识
-
- 深度学习
- 2. DNN
-
- 2.1 从感知器到神经网络
- 2.2 DNN的基本结构
-
- 2.2.1 前向传播算法
-
- 激活函数
- 2.2.2 反向传播算法
-
- 损失函数
- 梯度下降
- 优化器
- 3.CNN
-
- 3.1CM
-
- 卷积层
- 池化层
- 全连接层(输出层)
- 3.2 TextCNN
- 4. 作业
1. 背景知识
该训练营主要讲解深度学习的自然语言处理,在讲解模型框架之前,先补充一下深度学习的背景知识。
深度学习
深度学习是机器学习的一个分支。许多传统机器学习算法学习能力有限,数据量的增加并不能持续增加学到的知识总量,而深度学习系统可以通过访问更多数据来提升性能,即“更多经验”的机器代名词。机器通过深度学习获得足够经验后,即可用于特定的任务,如驾驶汽车、识别田地作物间的杂草、确诊疾病、检测机器故障等。
深度结构有着强大的非线性拟合能力,可以任意精度逼近任何非线性连续函数,来进行高纬度数据处理,同时配合着强大的特征提取能力,可以通过自动学习出数据中的“合理规则”。同时缺点在于模型过于黑盒,隐藏了许多可解释性,并且计算量高,需要高性能硬件,寻找的一般是数据间的相关性,模型无法检测出数据对背后的因果逻辑,因此对新鲜数据的适应性差。
2. DNN
深度神经网络(Deep Neural Networks, 以下简称DNN)是深度学习的基础。需要理解DNN,必需要知道DNN背后的模型。
2.1 从感知器到神经网络
抽象模拟脑电波在脑神经间的传递过程,以获得机器学习中最简单的神经网络——感知器。感知器的模型是有若干输入和一个输出的模型,然后探究输出和输入之间学习到一个线性关系,y = Σwx + b。因为脑神经中有个机制是抑制和激活状态,在线性关系之后可以加入一个激活参数,决定感知器的激活状态,使输出在 -1~1之间。单个感知器只能处理二元分类问题,而神经网络会在感知器上进行拓展,以完成更加复杂的任务。
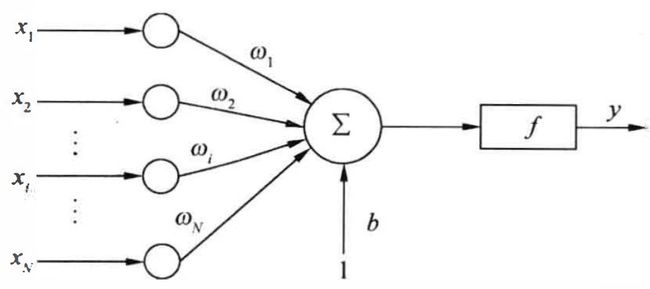 如上图所示,x为输入,y为输出,w、b为线性参数,f为激活函数。
如上图所示,x为输入,y为输出,w、b为线性参数,f为激活函数。
神经网络在横向和纵向维度对感知器进行拓展,比如添加隐藏层以纵向拓展其深度,增加输出结果以横向拓展宽度,丰富激活函数的种类以加强其非线性变换能力,增强神经网络的表达能力。在下面的图中,每一个圆圈表示一个感知器,有输入有输出也有激活函数,颜色深浅表示激活程度。
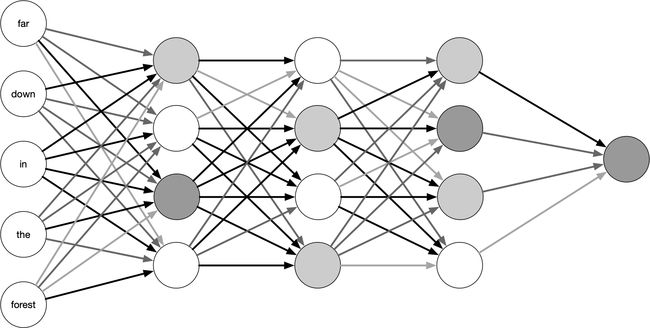
2.2 DNN的基本结构
神经网络层可以分为三类,输入层,隐藏层和输出层,如上图示例。一般来说第一层是输入层,最后一层是输出层,而中间的层数都是隐藏层(注意输入层是没有w参数的)。
2.2.1 前向传播算法
假设选择的激活函数是Sigmoid函数,隐藏层和输出层的输出值为a ,则对于下图的三层DNN,利用和感知机一样的思路,我们可以利用上一层的输出计算下一层的输出,也就是所谓的DNN前向传播算法。使用代数法一个个的表示输出比较复杂,而如果使用矩阵法则比较的简洁。比如输入层有m个输入,后面接着的隐藏层有n个输出,使用一个w的矩阵[m×n],即可把m个输入转化为n个输出。然后利用若干个权重系数矩阵W,偏倚向量b来和输入值向量x进行一系列线性运算和激活运算,从输入层开始,一层层的向后计算,一直到运算到输出层,得到输出结果为值。
激活函数
激活函数是非线性函数,通过加入激活函数,使得感知器可以处理一些最基本的异或问题,甚至是更复杂的非线性问题。
常见的激活函数
sigmoid函数:

其缺点如下:
- 当输入很大或很小,饱和的神经元会带来梯度消失(Gradient Vanishing);
- 函数的输出不是以0为对称的(zero-centered);
- 使用指数函数,计算代价有点高。
tanh函数

与sigmoid函数相比,其解决了zero-centered的问题。但是,梯度消失与指数函数计算代价高的问题,仍然存在。
relu函数

优点:
- 在输入空间的一半都不存在饱和问题;
- 收敛速度快;
缺点: - 输出不是以0为中心;
- Dead Relu Problem,指的是某些神经元可能永远不会被激活,导致相应的参数永远不会被更新(参数初始化问题或者参数更新太大);
- 在输入空间的另一半会存在梯度消失的问题。
2.2.2 反向传播算法
如果我们采用DNN的模型,即输入层m个神经元,输出层有n个神经元。再加上一些含有若干神经元的隐藏层。此时需要找到合适的所有隐藏层和输出层对应的线性系数矩阵W,偏倚向量b,让所有的训练样本输入计算出的输出尽可能的等于或很接近样本输出。怎么找到合适的参数呢?
可以用一个合适的损失函数来度量训练样本的输出损失,接着对这个损失函数进行优化求最小化的极值,对应的一系列线性系数矩阵W,偏倚向量b即为我们的最终结果。在DNN中,损失函数优化极值求解的过程最常见的一般是通过梯度下降法来一步步迭代完成的。
损失函数
损失函数用来评价模型的预测值和真实值的残差,损失函数越好,通常模型的性能越好。不同的模型用的损失函数一般也不一样。这里将常用的损失函数分为了两大类:回归和分类问题。然后又分别对这两类进行了细分和讲解,其中回归中包含了一种不太常见的损失函数:平均偏差误差,可以用来确定模型中存在正偏差还是负偏差。
回归问题处理的则是连续值的预测问题,例如给定房屋面积、房间数量以及房间大小,预测房屋价格。在分类任务中,我们要从类别值有限的数据集中预测输出,比如给定一个手写数字图像的大数据集,将其分为 0~9 中的一个。
在本次训练营中,我们关注的是文本分类问题,分类问题常用的损失函数是交叉熵(cross-entropy)。
在二分类场景下,模型最后需要预测的结果只有两种情况,对于每个类别我们的预测得到的概率为p和1-p,此时表达式为(log 的底数是 e):

其中:
yi 表示样本 i 的label,正类为 1 ,负类为 0
pi 表示样本 i 预测为正类的概率
多分类的情况实际上就是对二分类的扩展:
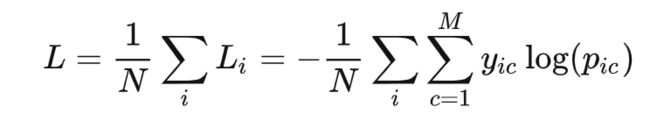
M类别的数量
yic 符号函数( 0 或 1 ),如果样本 i 的真实类别等于 c 取 1 ,否则取 0
pic 观测样本 i 属于类别 c 的预测概率
例子:我们希望根据文本的特征,来预测情感的类别,有三种可预测类别:高兴、悲伤、愤怒。假设我们当前有一个模型,是通过softmax的方式得到对于每个预测结果的概率:
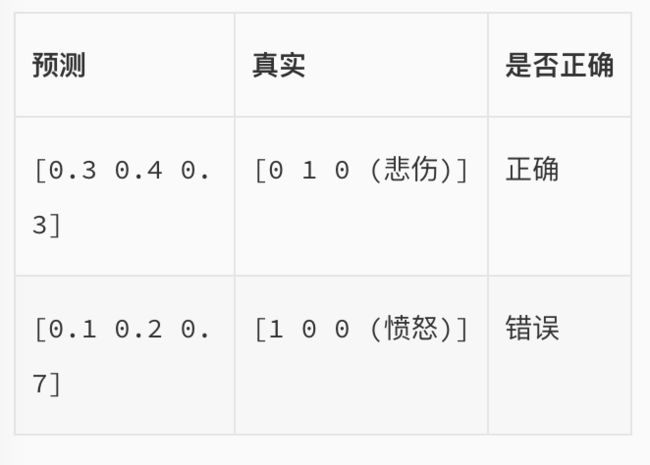
通过刚刚的多分类计算公式得到loss值:

梯度下降
在机器学习算法中,在最小化损失函数时,可以通过梯度下降法来一步步的迭代求解,得到最小化的损失函数,和模型参数值。
梯度下降法的思路很简单,想象在山顶放了一个球,一松手它就会顺着山坡最陡峭的地方滚落到谷底:

从上面的解释可以看出,梯度下降不一定能够找到全局的最优解,有可能是一个局部最优解。当然,如果损失函数是凸函数,梯度下降法得到的解就一定是全局最优解。
而用数学公式来解释,首先要了解步长和导数对梯度下降的作用。拿一个凸函数f(x) = xˆ2举例,在这里斜率就是对损失函数的 x0 求的导数,具体的x0 的纵坐标是目前模型的loss值,步长是横坐标变化量。
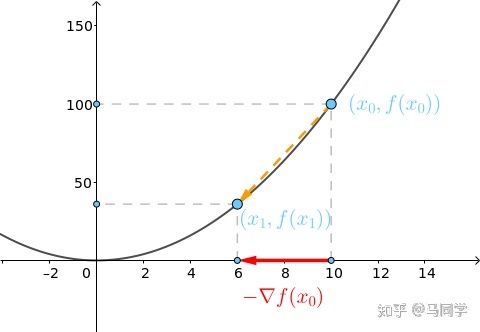
在凸函数上,随着一步步的迭代,斜率不断减小并趋近于0,因此被称为梯度下降法,并且当斜率趋近为0是,得到的loss值也是最小值。
优化器
优化器就是在深度学习反向传播过程中,指引损失函数(目标函数)的各个参数往正确的方向更新合适的大小,使得更新后的各个参数让损失函数(目标函数)值不断逼近全局最小。
常见的优化器有随机梯度下降法(Stochastic Gradient Descent,SGD)、Adam(自适应学习率算法)等。
随机梯度下降算法每次从训练集中随机选择一个样本来进行学习
#DNN样例代码
import torch.nn as nn
import torch
max_fid = 123
class Net(torch.nn.Module):
def __init__(self, n_embed, n_feature, n_hidden, n_output):
super(Net, self).__init__()
self.embedding = nn.Embedding(max_fid + 1, n_feature)
self.hidden = torch.nn.Linear(n_feature, n_hidden) # hidden layer
self.out = torch.nn.Linear(n_hidden, n_output) # output layer
def forward(self, fea_ids, fea_weights):
embeds = self.embedding(fea_ids)
embeds = emb_sum(embeds, fea_weights)
embeds = nn.functional.tanh(embeds)
hidden = self.hidden(embeds)
output = self.out(hidden)
return output
net = Net(n_embed = 32, n_feature= 32, n_hidden=10, n_output=2) # define the network
print(net)
optimizer = torch.optim.SGD(net.parameters(), lr=0.02)
loss_func = nn.CrossEntropyLoss() # the target label is NOT an one-hotted
Net(
(embedding): Embedding(124, 32)
(hidden): Linear(in_features=32, out_features=10, bias=True)
(out): Linear(in_features=10, out_features=2, bias=True)
)
C:\Users\chengyuanting\.conda\envs\pytorch_cpu\lib\site-packages\tqdm\auto.py:22: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
3.CNN
卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习的代表算法之一。CNN有很强的表征学习能力,去学习结构化特征,一般应用于图像处理。想要了解卷积神经在计算机视觉中的应用请点击CNN教程进行进一步了解。
CNN和DNN的差别在于CNN的隐藏层还包括了卷积层和池化层,以及输出层改成了全连接FC层,在卷积层中使用局部感受野和权值共享的技术,这些技术都可以帮助降低模型复杂度,减少参数数量。
3.1CM
卷积层
卷积层对输入图像进行转换,以从中提取特征。 在这种转换中,图像与卷积核(或过滤器)卷积。
卷积计算
卷积核是一个小的矩阵,其高度和宽度小于要卷积的图像。 它也被称为卷积矩阵或卷积掩码。 该核在图像输入的高度和宽度上滑动,并且卷积核的点积和图像在每个空间位置处进行计算。 卷积核滑动的长度称为步幅长度。 在下面的图像中,输入图像的大小为5X5,卷积核的大小为3X3,步幅为1。输出图像也称为卷积特征。在下图中绿色部分为图像,黄色部分为卷积核,粉色部分为卷积特征。
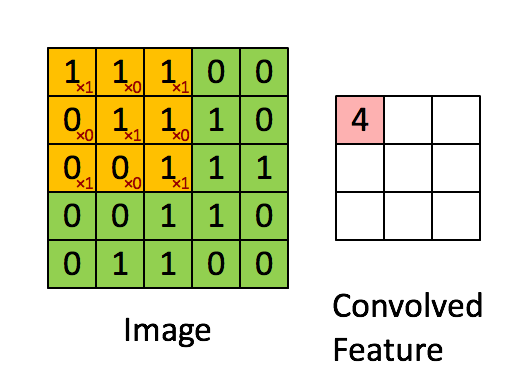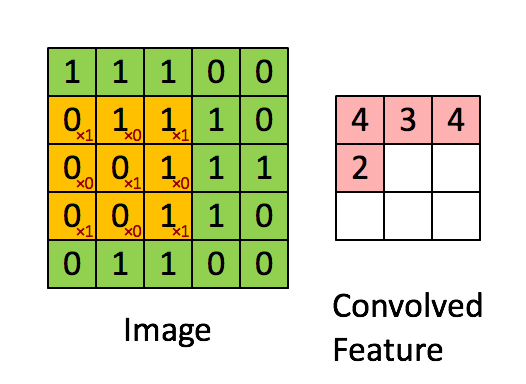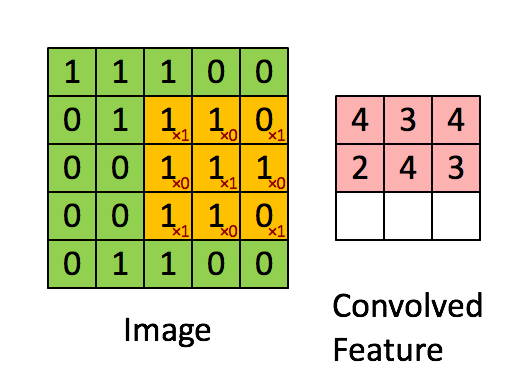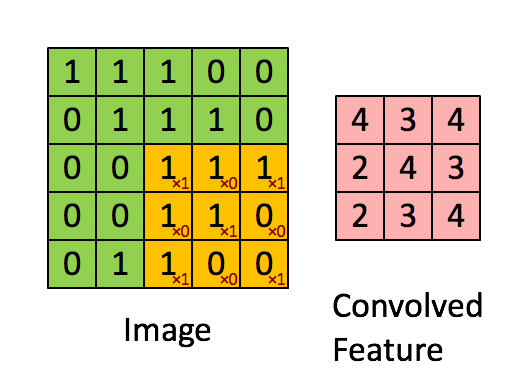
当我们想使用卷积从一个图像中提取多个特征时,我们可以使用多个卷积核而不是仅使用一个。 在这种情况下,所有卷积核的大小必须相同。 输入图像和输出图像的卷积特征一个接一个地堆叠在一起以创建输出,因此通道数等于使用的滤镜数。在下图中,通道数为3个。
激活层是卷积层的最后一个组成部分,可增加输出中的非线性。 通常,在卷积层中将ReLu函数或Tanh函数用作激活函数(在本次训练营,建议使用Tanh函数,因为Tanh函数在文本和音频处理有比较好的效果。)。 这是一个简单卷积层的图像,其中将6X6X3输入图像与大小为4X4X3的两个卷积核卷积以得到大小为3X3X2的卷积特征,对其应用激活函数以获取输出,这也称为特征地图。

专有名词解释
针对CNN有一些专有名词,比如通道,卷积核大小,步长,填充和输入输出通道数进行解释。
通道,对于图像数据来说,一张彩色图片有R,G,B红绿蓝三通道,那么这里就可以说输入图像的通道数为3,假设这张图片为黑白照片,则通道数为2。
卷积核大小,在网络中代表感受野的大小,二维卷积核最常见的就是 3X3 的卷积核,也可以根据网络设计5X5或者7X7,甚至1X1等不同size的卷积核,来提取不同尺度的特征。在卷积神经网络中,一般情况下,卷积核越大,感受野(receptive field)越大,看到的图片信息越多,所获得的全局特征越好。虽说如此,但是大的卷积核会导致计算量的暴增,不利于模型深度的增加,计算性能也会降低。如上图中卷积核的size为3X3.
步长,即为卷积核每次计算时移动的距离。步长小,提取的特征更全面,不会遗漏太多信息,但计算量大,容易产生过拟合问题;步长大,计算量下降,但可能错失一些有用特征。
填充,卷积核与图像尺寸不匹配,往往填充图像缺失区域,如果原始图片尺寸为5X5,卷积核的大小为3X3,如果不进行填充,步长为1的话,当卷积核沿着图片滑动后只能滑动出一个3X3的图片出来,这就造成了卷积后的图片和卷积前的图片尺寸不一致,这显然不是我们想要的结果,所以为了避免这种情况,需要先对原始图片做边界填充处理。
输入和输出通道数(Input & Output Channels):卷积核的输入通道数(in depth)由输入矩阵的通道数所决定;输出矩阵的通道数(out depth)由卷积核的输出通道数所决定。每一层卷积有多少channel数,以及一共有多少层卷积,这些暂时没有理论支撑,一般都是靠感觉去设置几组候选值,然后通过实验挑选出其中的最佳值。这也是现在深度卷积神经网络虽然效果拔群,但是一直为人诟病的原因之一。
池化层
池化层也称为下采样,主要用于特征降维,压缩数据和参数数量,减小过拟合,提升模型容错率。 在卷积神经网络中,通常在卷积层,激活层之后是池化层。 通常添加池层以加快计算速度,并使某些检测到的功能更健壮。
池操作也使用卷积核和跨步。 在下面的示例图像中,使用2X2过滤器合并大小为4,跨度为2的4X4输入图像。
有不同类型的池。 最大池和平均池是卷积神经网络中最常用的池方法。
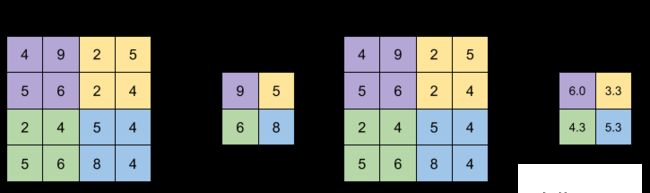
最大池化:在最大池化中,从要素图的每个面片中选择最大值以创建缩小图,最大池化效果更好一点。
平均池化:在平均池化中,从要素图的每个面片中选择平均值以创建缩小图。
全连接层(输出层)
完全连接的层位于卷积神经网络的末端。 由较早层产生的特征图将展平为矢量。 然后,此向量被馈送到完全连接的层,以便它捕获高级要素之间的复杂关系。 该层的外面是一维特征向量,经由softmax函数得到最终的输出,整个模型训练完毕。
3.2 TextCNN
Yoon Kim在论文(2014 EMNLP) Convolutional Neural Networks for Sentence Classification提出TextCNN。将卷积神经网络CNN应用到文本分类任务,利用多个不同size的kernel来提取句子中的关键信息(类似于多窗口大小的n-gram),从而能够更好地捕捉局部相关性。
在下图的输入层“I like this movie very much ! ”的feature map长是7个单词(包括符号),宽是embedding的维度d=5,如果有两张feature map,可以理解为有两句话,也就是batch_size = 2。
然后通过长宽不等的卷积核,宽分别为[2, 3, 4]的卷积核映射不同size的卷积特征(见下图第二列),通过激活(第二列到第三列),池化(第三列到第四列)和全连接操作,最后进行分类预测。
由于每个单词的embedding dim(词向量长度)是固定的,每个卷积核的宽度也必须和单词的embedding dim 保持一致,只能改变卷积核的高度,卷积核的通道可以理解为用不同的词向量表示。
输入句子的长度不一样,但是卷积核的个数一样,由于每个卷积核抽取单词的个数不一样,卷积核高度低的形成的feature maps 长度就长,卷积核高度高的形成的feature maps长度就短。
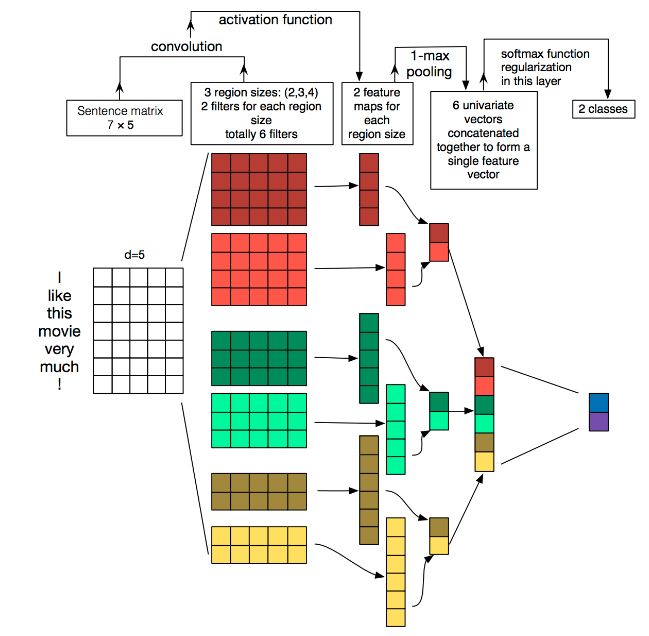
#TextCNN的样例代码 将上图模型用pytorch表示出来
import torch
import torch.nn as nn
import torch.nn.functional as F
class textCNN(nn.Module):
def __init__(self,Vocab, class_num,kernel_sizes):
super(textCNN, self).__init__()
Dim = 5 #每个词向量长度
Cla = class_num #类别数
Ci = 1 #输入的channel数
Ks = kernel_sizes # 卷积核list,形如[2,3,4]
self.embed = nn.Embedding(Vocab,Dim) # 词向量,这里直接随机
self.convs = nn.ModuleList([nn.Conv2d(Ci,100,(K,Dim)) for K in Ks]) # 卷积层
self.dropout = nn.Dropout(p=0.5)
self.fc = nn.Linear(len(Ks)*100,Cla) #全连接层
def forward(self,x):
x = torch.tensor(x).to(torch.int64)
x = self.embed(x) #(N,W,D)
x = x.unsqueeze(1) #(N,Ci,W,D)
x = [F.relu(conv(x)).squeeze(3) for conv in self.convs] # len(Ks)*(N,Knum,W)
x = [F.max_pool1d(line,line.size(2)).squeeze(2) for line in x] # len(Ks)*(N,Knum)
x = torch.cat(x,1) #(N,Knum*len(Ks))
x = self.dropout(x)
logit = self.fc(x)
return logit
net = textCNN(Vocab = 1000, class_num = 2, kernel_sizes =[2,3,4])
print(net)
textCNN(
(embed): Embedding(1000, 5)
(convs): ModuleList(
(0): Conv2d(1, 100, kernel_size=(2, 5), stride=(1, 1))
(1): Conv2d(1, 100, kernel_size=(3, 5), stride=(1, 1))
(2): Conv2d(1, 100, kernel_size=(4, 5), stride=(1, 1))
)
(dropout): Dropout(p=0.5, inplace=False)
(fc): Linear(in_features=300, out_features=2, bias=True)
)
!pip install torchinfo
import torchinfo
torchinfo.__version__
Defaulting to user installation because normal site-packages is not writeable
Requirement already satisfied: torchinfo in c:\users\chengyuanting\appdata\roaming\python\python39\site-packages (1.8.0)
'1.8.0'
from torchinfo import summary
batch_size = 64
summary(net, input_size=(batch_size, 1000))
C:\Users\chengyuanting\AppData\Local\Temp\ipykernel_17196\1359358780.py:22: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
x = torch.tensor(x).to(torch.int64)
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
textCNN [64, 2] --
├─Embedding: 1-1 [64, 1000, 5] 5,000
├─ModuleList: 1-2 -- --
│ └─Conv2d: 2-1 [64, 100, 999, 1] 1,100
│ └─Conv2d: 2-2 [64, 100, 998, 1] 1,600
│ └─Conv2d: 2-3 [64, 100, 997, 1] 2,100
├─Dropout: 1-3 [64, 300] --
├─Linear: 1-4 [64, 2] 602
==========================================================================================
Total params: 10,402
Trainable params: 10,402
Non-trainable params: 0
Total mult-adds (M): 306.88
==========================================================================================
Input size (MB): 0.26
Forward/backward pass size (MB): 155.85
Params size (MB): 0.04
Estimated Total Size (MB): 156.15
==========================================================================================
4. 作业
- 在DNN样例代码中,激活函数,优化器和损失函数分别是什么?(不需要加括号)
answer_1 = 'tanh' #激活函数放入引号内
answer_2 = 'SGD' #优化器放入引号内
answer_3 = 'CrossEntropyLoss' #损失函数放入引号内
- 使用textCNN的样例代码,输入数据维度为[batch_size = 64, token_size=2228],问Conv2d(1, 100, kernel_size=(3, 5), stride=(1, 1))的输出数据维度?(需要以数组表示方式呈现,例如[w, x, y, z])
提示:因为答案是用string进行匹配,需要使用英文逗号进行分隔,并且中间无空格
answer_4 = '[64,100,2226,1]' #答案放入引号内
可以利用提供的代码来确定Conv2d(1, 100, kernel_size=(3, 5), stride=(1, 1))输出的维度。
这段代码定义了一个文本分类的卷积神经网络模型,它使用了嵌入层将输入的文本词汇转换为固定长度的词向量,然后通过一系列的卷积层来提取文本特征,并最终通过一个全连接层进行分类。
这里的关键部分是卷积层:
self.convs = nn.ModuleList([nn.Conv2d(Ci,100,(K,Dim)) for K in Ks])
这表示网络将使用多个卷积核大小,但每个核大小的卷积层都将有100个输出通道,并且每个卷积核都将覆盖Dim个词嵌入维度。由于词嵌入的维度是5,所以卷积核的大小将是(K, 5)。
接下来,我们看一下前向传播函数:
x = self.embed(x) # (N,W,D)
x = x.unsqueeze(1) # (N,Ci,W,D)
x = [F.relu(conv(x)).squeeze(3) for conv in self.convs] # len(Ks)*(N,Knum,W)
这里,输入x首先被转换成了词嵌入,维度是(N, W, D),其中:
N是batch_sizeW是token_size,即句子长度D是每个词向量的长度,这里是5
卷积操作应用于扩展了一个维度的x,也就是(N, Ci, W, D)。在这个情况下,Ci是输入通道数,这里是1。每个卷积层的输出是(N, Knum, W, 1),其中Knum是输出通道数,这里是100。
根据卷积操作的定义,输出宽度(即句子长度维度)是通过以下公式计算的:
KaTeX parse error: Expected 'EOF', got '_' at position 14: [\text{output_̲width} = \frac{…
在我们的例子中,input_width是token_size(句子长度),kernel_width是卷积核的高度(我们的例子中是3),stride_width是1。因此:
KaTeX parse error: Expected 'EOF', got '_' at position 14: [\text{output_̲width} = \frac{…
所以,对于每个卷积层,输出的维度将是(N, 100, 2226, 1)。然后我们应用1-max pooling,这将会减少每个卷积层的输出到(N, 100)。因为我们有len(Ks)组这样的输出,每组输出都是(N, 100),最后这些输出会被拼接起来,所以全连接层的输入维度将是(N, 100 * len(Ks))。
请注意,这里的输出宽度计算假设了句子长度(token_size)是连续的词嵌入维度,这在实际中可能不是这样。在实际应用中,token_size应该是句子长度(即单词数量),而不是单词数量乘以词嵌入维度。如果句子长度和词嵌入维度在实际应用中是分开的,那么上述维度计算需要相应调整。
# Define the parameters as provided in the problem statement and the code
batch_size = 64 # given batch size
token_size = 2228 # total number of tokens
embedding_dim = 5 # embedding dimension from the code
kernel_size = (3, embedding_dim) # kernel size as per the Conv2d definition in the code
stride = (1, 1) # stride for the convolution
# Calculate the output dimensions after the convolution layer
# Note that the input width is considered to be the 'token_size' here, which might need clarification.
# However, for the purpose of this calculation, we assume 'token_size' is the effective width after embedding.
# Output width calculation for convolution
output_width = ((token_size - kernel_size[0]) // stride[0]) + 1
output_height = 1 # Since the embedding dimension is completely covered by the kernel, the output height is 1
# The number of output channels is given as 100
output_channels = 100
# Output dimension after convolution
output_dimension = [batch_size, output_channels, output_width, output_height]
output_dimension
[64, 100, 2226, 1]
- 在textCNN的样例代码中,从输入层到输出层,一共有几层?
answer_5 = '6' #答案放入引号内