CESI: Canonicalizing Open Knowledge Bases using Embeddings and Side Information

Tags: Knowledge Base Canonicalization
Authors: Partha Talukdar, Prince Jain, Shikhar Vashishth
Created Date: December 11, 2023 4:13 PM
Status: Reading
organization: Indian Institute of Science Bangalore, Microsoft Bangalore
publisher: WWW
year: 2018
code: https://github.com/malllabiisc/cesi
paper: http://malllabiisc.github.io/publications/papers/cesi_www18.pdf
介绍
本文的任务是开放性知识图谱标准化,旨在将开放信息抽取中的实体和关系进行标准化,将相同意义但不同描述的实体和关系归为一类。
本文指出,过去的方法需要手动定义特征,并以此进行聚类。这些方法往往非常昂贵且通常只能得到次优结果。因此作者提出了一个新的框架,通过训练嵌入的方式来进行特征提取。
整体框架
本文的整体框架主要分为三个部分
- 侧面信息获取
- 实体关系嵌入
- 聚类以及标准化
侧面信息获取
开放知识库中的实体和关系通常都存在一些相关的侧面信息,比如一些有用的额外信息。作者使用这些信息来协助特征获取。
实体侧面信息
- 实体链接(Entity Linking):给定无结构文本,实体链接会把实体映射成知识库中的概念,如果两个实体被映射到同一个概念,就可以假设这两个实体是等价的。
- PPDB 信息(PPDB Information):PPDB全称Paraphrase Database,作者首先将高置信度的词组抽取出来,然后进行聚类。若两个实体被归为一类,就可以假设这两个实体是等价的。
- 基于WordNet的词义消岐(WordNet with Word-sense Disambiguation):如果两个实体词义相近,那么可以被标记为相似。
- 逆文档频率重叠(IDF Token Overlap):同时存在不常见单词的实体可以被认为相似。
- 形态标准化(Morph Normalization):将变体单词变为统一形式,如"walked"和"walking"变成"walk"。
关系侧面信息
使用PPDB和WordNet信息,以及以下额外信息:
- AMIE信息(AMIE Information):AMIE全称Association Rule Mining under Incomplete Evidence,如果两个关系 r 和 r’ ,可以推出 ⇒ ′ 以及 ′ ⇒ 且置信度超过阈值,就可以说明两个关系等价。
- KBP信息(KBP Information):KBP全称Knowledge Base Population,可以将关系映射到知识库中,若两个关系被映射到同一个概念,就可以说明等价。
实体关系嵌入

是三元组得分,ηi![]() 是正样本,ηj
是正样本,ηj![]() 是负样本;ev
是负样本;ev![]() 和ev'
和ev'![]() 是等价信息,因此尝试拉近距离,r
是等价信息,因此尝试拉近距离,r![]() 同理;最后是正则化损失函数。
同理;最后是正则化损失函数。
评价指标
C表示预测出来的簇,E表示完全正确的簇。样例如下:

Macro

大致意思是,如果一个簇中指包含一个概念,则视为正确的簇,可以不全,但不能有其他概念,如例子中的c2![]() 和c3
和c3![]() 为正确的簇,其中c2
为正确的簇,其中c2![]() 虽然少了一个New York City,但没有其他概念。相比之下c1
虽然少了一个New York City,但没有其他概念。相比之下c1![]() 因为包含了两个概念,所以不算正确的簇。
因为包含了两个概念,所以不算正确的簇。
Micro

大致意思为,统计每个预测簇中包含的最多概念的个数并求和。比如,c1![]() 中包含两个概念e1
中包含两个概念e1![]() 和e2
和e2![]() ,但e1
,但e1![]() 数量多,因此只统计e1
数量多,因此只统计e1![]() 的个数,即2个。
的个数,即2个。
Pairwise

大致意思是,穷举每个簇中的所有概念对组合(不看顺序,顺序颠倒不算额外概念对),统计其中属于同一个概念的数量。
P的分母是按照C的结果计算总体概念对的数量(C2c![]() ),R的结果是按照标准答案计算总体概念对数量(C2e
),R的结果是按照标准答案计算总体概念对数量(C2e![]() );P和R的分子是相同的。
);P和R的分子是相同的。
对于c1![]() ,有3个元素,可以组成C23=3
,有3个元素,可以组成C23=3![]() 个组合{(America, USA), (America, New York City), (USA, New York City)},但只有(America, USA)属于同一个概念,因此计数1;同样,对于c2
个组合{(America, USA), (America, New York City), (USA, New York City)},但只有(America, USA)属于同一个概念,因此计数1;同样,对于c2![]() ,也有三种组合,且三种组合都属于同一个概念,因此计数3;对于c3
,也有三种组合,且三种组合都属于同一个概念,因此计数3;对于c3![]() ,由于簇中只有一个元素,因此没有组合。
,由于簇中只有一个元素,因此没有组合。
那么分子就是 1+3+0=4。
数据集
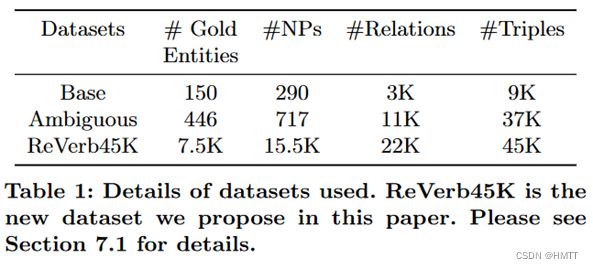
主实验
