大数据技术11:Hadoop 原理与运行机制
前言:HDFS (Hadoop Distributed File System)是 Hadoop 下的分布式文件系统,具有高容错、高吞吐量等特性,可以部署在低成本的硬件上。
一、Hadoop简介
1.1、Hadoop定义
Hadoop 作为一个开源分布式系统基础框架,主要包含两大核心组件:HDFS 分布式文件系统和 MapReduce 分布式并行计算框架,这两大核心组件是 Hadoop 进行大数据处理的基础和基石,此外,Hadoop 的重要组件还包括:Hadoop Common 和 YARN 框架。目前,Hadoop 主要由 Apache 软件基金会进行开发和维护。
其实,我们在使用 Hadoop 的过程中,不需要了解分布式系统底层的细节,在开发 Hadoop 分布式程序的时候,只需要简单地编写 map() 函数和 reduce() 函数即可完成 Hadoop 程序的开发,并且能够充分利用 Hadoop 集群的大规模存储和高并行计算来完成复杂的大数据处理业务。
同时,Hadoop 分布式文件系统的高度容错性和高可扩展性等优点使得 Hadoop 可以部署在廉价的服务器集群上,它能够大大节约海量数据的存储成本。MapReduce 的高度容错性,有效保证了系统计算结果的准确性,并从整体上解决了大数据的可靠性存储和处理。
实际上,Hadoop 核心(或重要)组件主要包括:Hadoop Common、HDFS 分布式文件系统、MapReduce 分布式计算框架、YARN 资源调度框架,接下来,我们来简单了解 HDFS、MapReduce 和 YARN 的运行流程。
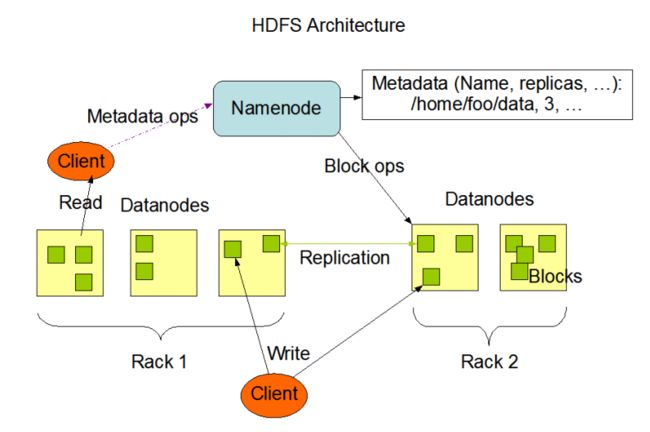
(1)HDFS 架构
HDFS 遵循主/从架构,由单个 NameNode(NN) 和多个 DataNode(DN) 组成:
NameNode : 负责执行有关 文件系统命名空间 的操作,例如打开,关闭、重命名文件和目录等。
它同时还负责集群元数据的存储,记录着文件中各个数据块的位置信息。
DataNode:负责提供来自文件系统客户端的读写请求,执行块的创建,删除等操作。
(2)文件系统命名空间
HDFS 的 文件系统命名空间 的层次结构与大多数文件系统类似 (如 Linux), 支持目录和文件的创建、移 动、删除和重命名等操作,支持配置用户和访问权限,但不支持硬链接和软连接。 NameNode 负责维护 文件系统名称空间,记录对名称空间或其属性的任何更改。
1.2、HDFS 分布式文件系统
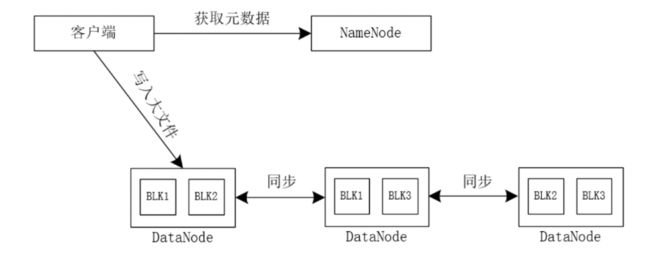
首先,Hadoop 会将一个大文件切分成 N 个小文件数据块,分别存储到不同的 DataNode 上,具体如图1所示。
(图1)
当我们向 Hadoop 写入一个大文件时,客户端首先会向 NameNode 服务器获取元数据信息,得到元数据信息后向相应的 DataNode 写入文件,Hadoop 框架会比较文件的大小与数据块的大小,如果文件的大小小于数据块的大小,则文件不再切分,直接保存到相应的数据块中;如果文件的大小大于数据块的大小, Hadoop 框架则会将原来的大文件进行切分,形成若干数据块文件,并将这些数据块文件存储到相应的数据块中,同时,默认每个数据块保存3个副本存储到不同的 DataNode 中。
由于 Hadoop 中 NameNode 节点保存着整个数据集群的元数据信息,并负责整个集群的数据管理工作,所以,它在读/写数据上与其他传统分布式文件系统有些许不同之处。
Hadoop 读数据的简易流程如下图所示。

(图2)
-
客户端发出读数据请求,请求 NameNode 节点的元数据。
-
NameNode 节点将元数据信息返回给客户端。
-
客户端根据 NameNode 节点返回的元数据信息,到对应的 DataNode 节点上读取块数据,如果读取的文件比较大,则会被 Hadoop 切分成多个数据块,保存到不同的 DataNode 上。
-
读取完3的数据块后,如果数据未读取完,则接着读取数据。
-
读取完4的数据块后,如果数据未读取完,则接着读取数据。
-
读完所有的数据之后,通知 NameNode 关闭数据流。
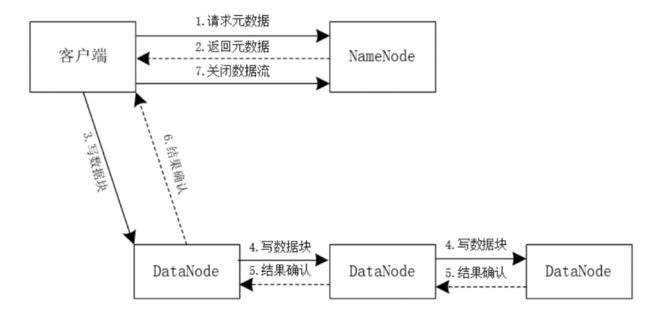
Hadoop 写数据的简易流程如下图所示。
(图3)
-
客户端向 NameNode 节点发起元数据请求,指定文件上传的路径,此时,NameNode 节点内部会进行一系列的操作,比如:验证客户端指定的路径是否合法,客户端是否具有写权限等。验证通过后,NameNode 节点会为文件分配块存储信息。
-
NameNode 节点向客户端返回元数据信息,并给客户端返回一个输出流。
-
客户端获取到元数据和输出流之后,开始向第一个 DataNode 节点写数据块。
-
第一个 DataNode 节点将数据块发送给第二个 DataNode 节点,第二个 DataNode 节点将数据块发送给第三个 DataNode 节点,以此类推,写完所有的数据块。
-
每个 DataNode 节点会向上游的 DataNode 节点发送结果确认信息,以保证写入数据的完整性。
-
DataNode 节点向客户端发送结果确认信息,保证数据写入成功。
-
当所有的数据块都写完,并且客户端接收到写入成功的确认信息后,客户端会向 NameNode 节点发送关闭数据流请求,NameNode 节点会将之前创建的输出流关闭。
1.3、MapReduce 分布式计算框架
值得一提的是,Hadoop 的 MapReduce 分布式计算框架会将一个大的、复杂的计算任务,分解为一个个小的简单的计算任务,这些分解后的计算任务会在 MapReduce 框架中并行执行,然后将计算的中间结果根据键进行排序、聚合等操作,最后输出最终的计算结果。
我们可以将这一整个 MapReduce 过程分为:数据输入阶段、map 阶段、中间结果处理阶段(包括 combiner 阶段和 shuffle 阶段)、reduce 阶段以及数据输出阶段。
-
数据输入阶段:将待处理的数据输入 MapReduce 系统。
-
map 阶段:map() 函数中的参数会以键值对的形式进行输入,经过 map() 函数的一系列并行处理后,将产生的中间结果输出到本地磁盘。
-
中间结果处理阶段:这个阶段又包含 combiner 阶段和 shuffle 阶段,对 map() 函数输出的中间结果按照键进行排序和聚合等一系列操作,并将键相同的数据输入相同的 reduce() 函数中进行处理(用户自身也可以根据实际情况指定数据的分发规则)。
-
reduce 阶段:reduce 函数的输入参数是以键和对应的值的集合形式输入的,经过 reduce 函数的处理后,产生一系列键值对形式的最终结果数据输出到 HDFS 分布式文件系统中。
-
数据输出阶段:数据从 MapReduce 系统中输出到 HDFS 分布式文件系统。
上述简要执行过程如图4所示。

(图4)
原始数据以“(k, 原始数据行data)”的形式输入到 map 阶段,经过 map 阶段的 map() 函数一系列并行处理后,将中间结果数据以“{(k1, v1), (k1, v2)}”的形式输出到本地,然后经过 MapReduce 框架的中间结果处理阶段的处理,此中间结果处理阶段会根据键对数据进行排序和聚合处理,将键相同的数据发送到同一个 reduce 函数处理。
接下来我们就进入到 reduce 阶段,reduce 阶段接收到的数据都是以“{k1,[v1, v2]…}”形式存在的数据,这些数据经过 reduce 阶段的处理之后,最终得出“{(k1,v3)}”样式的键值对结果数据,并将最终结果数据输出到 HDFS 分布式文件系统中。
1.4、YARN 资源调度系统
YARN 框架主要负责 Hadoop 的资源分配和调度工作,其工作流程可以简化为图5所示。

(图5)
-
客户端向 ResourceManager 发出运行应用程序的请求。
-
ResourceManager 接收到客户端发出的运行应用程序的请求后,为应用程序分配资源。
-
ResourceManager 到 NodeManager 上启动 ApplicationMaster。
-
ApplicationMaster 向 ResourceManager 注册,使得 ResourceManager 能够时刻获得运行任务的进程状态信息;同时,ResourceManager 会为 ApplicationMaster 分配资源,并将分配资源的信息发送给 ApplicationMaster。
-
ApplicationMaster 获得分配的资源信息后,启动相应节点上的 Container,执行具体的 Task 任务。
-
Container 时刻与 ApplicationMaster 进行通信,向 ApplicationMaster 汇报任务执行的情况。
-
当所有的任务运行完成之后,ApplicationMaster 向 ResourceManager 发出请求,注销自己。
1.5、HDFS 的特点
(1)高容错
由于 HDFS 采用数据的多副本方案,所以部分硬件的损坏不会导致全部数据的丢失。
(2)高吞吐量
HDFS 设计的重点是支持高吞吐量的数据访问,而不是低延迟的数据访问。
(3)大文件支持
https://github.com/heibaiyingHDFS 适合于大文件的存储,文档的大小应该是是 GB 到 TB 级别的。
(4) 简单一致性模型
HDFS 更适合于一次写入多次读取 (write-once-read-many) 的访问模型。支持将内容追加到文件末尾,
但不支持数据的随机访问,不能从文件任意位置新增数据。
(5)跨平台移植性
HDFS 具有良好的跨平台移植性,这使得其他大数据计算框架都将其作为数据持久化存储的首选方案。
二、搭建 Hadoop 单机环境
为了演示简单,这里我们搭建一套 Hadoop 单机环境为大家进行演示,并且默认大家已经安装好 CentOS7 操作系统并搭建好 JDK 环境。具体的环境信息如下所示。
-
操作系统:CentOS7
-
主机名:binghe102
-
IP 地址:192.168.184.102
-
JDK 版本:1.8
-
Hadoop 版本:Apache Hadoop 3.2.0
注意:此部分操作是以 Hadoop 用户登录 CentOS7 服务器进行的。
2.1、 配置操作系统基础环境
我们主要是 Hadoop 用户来安装并启动 Hadoop,所以,我们需要先在服务器中添加 Hadoop 用户。
(1)添加 Hadoop 用户组和用户
首先,我们需要登录 root 账户,执行如下命令添加 Hadoop 用户组和用户。
groupadd hadoop
useradd -r -g hadoop hadoop(2)赋予 Hadoop 用户目录权限
为了方便安装 Hadoop 环境,我们需要将服务器的 /usr/local 目录权限赋予 Hadoop 用户,具体命令如下所示。
mkdir -p /home/hadoop
chown -R hadoop.hadoop /usr/local/
chown -R hadoop.hadoop /tmp/
chown -R hadoop.hadoop /home/(3)赋予 Hadoop 用户 sudo 权限
在这里,我们主要通过 vim 编辑器编辑 /etc/sudoers 文件来赋予 Hadoop 用户 sudo 权限,具体操作如下:
vim /etc/sudoers然后找到如下代码。
root ALL=(ALL) ALL接着,在此行代码后添加如下代码。
hadoop ALL=(ALL) ALL注意:由于“/etc/sudoers”是只读文件,所以保存并退出“/etc/sudoers”文件使用的是“wq!”。
(4)赋予 Hadoop 用户密码
我们采用如下方式赋予 Hadoop 用户密码。
[root@binghe102 ~]# clear
[root@binghe102 ~]# passwd hadoop
Changing password for user hadoop.
New password: 输入密码
BAD PASSWORD: The password is shorter than 8 characters
Retype new password: 再次输入密码
passwd: all authentication tokens updated successfully.(5)关闭防火墙
并在命令行输入如下命令,关闭 CentOS7 防火墙。
(6)配置 Hadoop 用户免密码登录
最后,以 Hadoop 用户登录服务器,分别输入如下命令来配置 Hadoop 用户免密码登录。
ssh-keygen -t rsa
cat /home/hadoop/.ssh/id_rsa.pub >> /home/hadoop/.ssh/authorized_keys
chmod 700 /home/hadoop/
chmod 700 /home/hadoop/.ssh
chmod 644 /home/hadoop/.ssh/authorized_keys
chmod 600 /home/hadoop/.ssh/id_rsa
ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub 主机名(IP地址)2.2 、搭建 Hadoop 本地模式
其实,Hadoop 本地安装模式是三种安装模式中最简单的一种,我们只需要在 Hadoop 的 hadoop-env.sh 文件中配置 JAVA_HOME 即可。
(1)下载 Hadoop 安装包
首先,我们需要在 CentOS7 命令行输入如下命令下载 Hadoop 安装包。
wget https://archive.apache.org/dist/hadoop/common/hadoop-3.2.0/hadoop-3.2.0.tar.gz(2)解压 Hadoop 安装包
然后,在 CentOS7 命令行输入如下命令解压 Hadoop 安装包。
tar -zxvf hadoop-3.2.0.tar.gz (3)配置 Hadoop 环境变量
接着,在 /etc/profile 文件中追加如下内容。
HADOOP_HOME=/usr/local/hadoop-3.2.0
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export PATH HADOOP_HOME然后输入如下命令使环境变量生效。
source /etc/profile(4)验证 Hadoop 的安装状态
在 CentOS7 命令行输入 hadoop version 命令验证 Hadoop 环境是否搭建成功,如下所示。
-bash-4.2$ hadoop version
Hadoop 3.2.0
Source code repository https://github.com/apache/hadoop.git -r e97acb3bd8f3befd27418996fa5d4b50bf2e17bf
Compiled by sunilg on 2019-01-08T06:08Z
Compiled with protoc 2.5.0
From source with checksum d3f0795ed0d9dc378e2c785d3668f39
This command was run using /usr/local/hadoop-3.2.0/share/hadoop/common/hadoop-common-3.2.0.jar可以看到,我们输出了 Hadoop 的版本号,说明 Hadoop 环境搭建成功。
(5)配置 Hadoop
这里,我们主要通过配置 Hadoop 安装目录下的 /etc/hadoop 目录下的 hadoop-env.sh 文件,例如我们将 Hadoop 安装在了 /usr/local/hadoop-3.2.0 目录下,所以,hadoop-env.sh 文件在 /usr/local/hadoop-3.2.0/etc/hadoop 目录下。
首先,使用 vim 编辑器打开 hadoop-env.sh 文件,如下所示。
vim /usr/local/hadoop-3.2.0/etc/hadoop/hadoop-env.sh然后找到如下代码。
# export JAVA_HOME=接着打开注释,我们将 JDK 的安装目录填写到等号后面。
export JAVA_HOME=/usr/local/jdk1.8.0_321至此,Hadoop 搭建环境搭建完成。