高并发系统设计的15个建议
前言
大家好,我是田螺。最近有知识星球好友问我,高并发系统如何设计?我以前发过的,今天再发一次哈,内容很干的。
记得很久之前,去面试过字节跳动。被三面的面试官问了一道场景设计题目:如何设计一个高并发系统。当时我回答得比较粗糙,最近回想起来,所以整理了设计高并发系统的15个锦囊,相信大家看完会有帮助的。

如何理解高并发系统
所谓设计高并发系统,就是设计一个系统,保证它整体可用的同时,能够处理很高的并发用户请求,能够承受很大的流量冲击。
我们要设计高并发的系统,那就需要处理好一些常见的系统瓶颈问题,如内存不足、磁盘空间不足,连接数不够,网络宽带不够等等,以应对突发的流量洪峰。
1. 分而治之,横向扩展
如果你只部署一个应用,只部署一台服务器,那抗住的流量请求是非常有限的。并且,单体的应用,有单点的风险,如果它挂了,那服务就不可用了。
因此,设计一个高并发系统,我们可以分而治之,横向扩展。也就是说,采用分布式部署的方式,部署多台服务器,把流量分流开,让每个服务器都承担一部分的并发和流量,提升整体系统的并发能力。
2. 微服务拆分(系统拆分)
要提高系统的吞吐,提高系统的处理并发请求的能力。除了采用分布式部署的方式外,还可以做微服务拆分,这样就可以达到分摊请求流量的目的,提高了并发能力。
所谓的微服务拆分,其实就是把一个单体的应用,按功能单一性,拆分为多个服务模块。比如一个电商系统,拆分为用户系统、订单系统、商品系统等等。

3. 分库分表
当业务量暴增的话,MySQL单机磁盘容量会撑爆。并且,我们知道数据库连接数是有限的。在高并发的场景下,大量请求访问数据库,MySQL单机是扛不住的!高并发场景下,会出现too many connections报错。
所以高并发的系统,需要考虑拆分为多个数据库,来抗住高并发的毒打。而假如你的单表数据量非常大,存储和查询的性能就会遇到瓶颈了,如果你做了很多优化之后还是无法提升效率的时候,就需要考虑做分表了。一般千万级别数据量,就需要分表,每个表的数据量少一点,提升SQL查询性能。
当面试官问要求你设计一个高并发系统的时候,一般都要说到分库分表这个点。
之前写了分库分表15连问,为了应对面试官追问到底,大家可以顺便复习一下分库分表的相关经典面试题哈,可以看我这篇文章:分库分表经典15连问
4. 池化技术
在高并发的场景下,数据库连接数可能成为瓶颈,因为连接数是有限的。
我们的请求调用数据库时,都会先获取数据库的连接,然后依靠这个连接来查询数据,搞完收工,最后关闭连接,释放资源。如果我们不用数据库连接池的话,每次执行SQL,都要创建连接和销毁连接,这就会导致每个查询请求都变得更慢了,相应的,系统处理用户请求的能力就降低了。
因此,需要使用池化技术,即数据库连接池、HTTP 连接池、Redis 连接池等等。使用数据库连接池,可以避免每次查询都新建连接,减少不必要的资源开销,通过复用连接池,提高系统处理高并发请求的能力。
同理,我们使用线程池,也能让任务并行处理,更高效地完成任务。大家可以看下我之前线程池的这篇文章,到时候面试官问到这块时,刚好可以扩展开来讲
5. 主从分离
通常来说,一台单机的MySQL服务器,可以支持500左右的TPS和10000左右的QPS,即单机支撑的请求访问是有限的。因此你做了分布式部署,部署了多台机器,部署了主数据库、从数据库。
但是,如果双十一搞活动,流量肯定会猛增的。如果所有的查询请求,都走主库的话,主库肯定扛不住,因为查询请求量是非常非常大的。因此一般都要求做主从分离,然后实时性要求不高的读请求,都去读从库,写的请求或者实时性要求高的请求,才走主库。这样就很好保护了主库,也提高了系统的吞吐。
当然,如果回答了主从分离,面试官可能扩展开问你主从复制原理,问你主从延迟问题等等,这块大家需要全方位复习好哈。可以去看看我之前的这篇文章
6. 使用缓存
无论是操作系统,浏览器,还是一些复杂的中间件,你都可以看到缓存的影子。我们使用缓存,主要是提升系统接口的性能,这样高并发场景,你的系统就可以支持更多的用户同时访问。
常用的缓存包括:Redis缓存,JVM本地缓存,memcached等等。就拿Redis来说,它单机就能轻轻松松应对几万的并发,你读场景的业务,可以用缓存来抗高并发。
缓存虽然用得爽,但是要注意缓存使用的一些问题:
-
缓存与数据库的一致性问题
-
缓存雪崩
-
缓存穿透
-
缓存击穿
7. CDN,加速静态资源访问
商品图片,icon等等静态资源,可以对页面做静态化处理,减少访问服务端的请求。如果用户分布在全国各地,有的在上海,有的在深圳,地域相差很远,网速也各不相同。为了让用户最快访问到页面,可以使用CDN。CDN可以让用户就近获取所需内容。
什么是CDN?
Content Delivery Network/Content Distribution Network,翻译过来就是内容分发网络,它表示将静态资源分发到位于多个地理位置机房的服务器,可以做到数据就近访问,加速了静态资源的访问速度,因此让系统更好处理正常别的动态请求。
8. 消息队列,削锋
我们搞一些双十一、双十二等运营活动时,需要避免流量暴涨,打垮应用系统的风险。因此一般会引入消息队列,来应对高并发的场景。

假设你的应用系统每秒最多可以处理2k个请求,每秒却有5k的请求过来,可以引入消息队列,应用系统每秒从消息队列拉2k请求处理得了。
有些伙伴担心这样可能会出现消息积压的问题:
-
首先,搞一些运营活动,不会每时每刻都那么多请求过来你的系统(除非有人恶意攻击),高峰期过去后,积压的请求可以慢慢处理;
-
其次,如果消息队列长度超过最大数量,可以直接抛弃用户请求或跳转到错误页面;
9. ElasticSearch
Elasticsearch,大家都使用得比较多了吧,一般搜索功能都会用到它。它是一个分布式、高扩展、高实时的搜索与数据分析引擎,简称为ES。
我们在聊高并发,为啥聊到ES呢?因为ES可以扩容方便,天然支撑高并发。当数据量大的时候,不用动不动就加机器扩容,分库等等,可以考虑用ES来支持简单的查询搜索、统计类的操作。
10. 降级熔断
熔断降级是保护系统的一种手段。当前互联网系统一般都是分布式部署的。而分布式系统中偶尔会出现某个基础服务不可用,最终导致整个系统不可用的情况, 这种现象被称为服务雪崩效应。
比如分布式调用链路A->B->C....,下图所示:
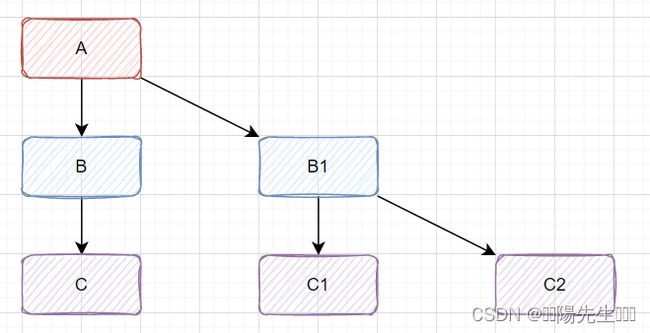
如果服务
C出现问题,比如是因为慢SQL导致调用缓慢,那将导致B也会延迟,从而A也会延迟。堵住的A请求会消耗占用系统的线程、IO、CPU等资源。当请求A的服务越来越多,占用计算机的资源也越来越多,最终会导致系统瓶颈出现,造成其他的请求同样不可用,最后导致业务系统崩溃。
为了应对服务雪崩, 常见的做法是熔断和降级。最简单是加开关控制,当下游系统出问题时,开关打开降级,不再调用下游系统。还可以选用开源组件Hystrix来支持。
你要保证设计的系统能应对高并发场景,那肯定要考虑熔断降级逻辑进来。
11. 限流
限流也是我们应对高并发的一种方案。我们当然希望,在高并发大流量过来时,系统能全部请求都正常处理。但是有时候没办法,系统的CPU、网络带宽、内存、线程等资源都是有限的。因此,我们要考虑限流。
如果你的系统每秒扛住的请求是一千,如果一秒钟来了十万请求呢?换个角度就是说,高并发的时候,流量洪峰来了,超过系统的承载能力,怎么办呢?
这时候,我们可以采取限流方案。就是为了保护系统,多余的请求,直接丢弃。
什么是限流:在计算机网络中,限流就是控制网络接口发送或接收请求的速率,它可防止DoS攻击和限制Web爬虫。限流,也称流量控制。是指系统在面临高并发,或者大流量请求的情况下,限制新的请求对系统的访问,从而保证系统的稳定性。
可以使用Guava的RateLimiter单机版限流,也可以使用Redis分布式限流,还可以使用阿里开源组件sentinel限流。
面试的时候,你说到限流这块的话?面试官很大概率会问你限流的算法,因此,大家在准备面试的时候,需要复习一下这几种经典的限流算法哈
最近,我们的业务系统引入了Guava的RateLimiter限流组件,它是基于令牌桶算法实现的,而令牌桶是非常经典的限流算法。本文将跟大家一起学习几种经典的限流算法。

限流是什么?
维基百科的概念如下:
In computer networks, rate limiting is used to control the rate of requests sent or
received by a network interface controller. It can be used to prevent DoS attacks
and limit web scraping简单翻译一下:在计算机网络中,限流就是控制网络接口发送或接收请求的速率,它可防止DoS攻击和限制Web爬虫。
限流,也称流量控制。是指系统在面临高并发,或者大流量请求的情况下,限制新的请求对系统的访问,从而保证系统的稳定性。限流会导致部分用户请求处理不及时或者被拒,这就影响了用户体验。所以一般需要在系统稳定和用户体验之间平衡一下。举个生活的例子:
★一些热门的旅游景区,一般会对每日的旅游参观人数有限制的。每天只会卖出固定数目的门票,比如5000张。假设在五一、国庆假期,你去晚了,可能当天的票就已经卖完了,就无法进去游玩了。即使你进去了,排队也能排到你怀疑人生。
”
常见的限流算法
固定窗口限流算法
首先维护一个计数器,将单位时间段当做一个窗口,计数器记录这个窗口接收请求的次数。
-
当次数少于限流阀值,就允许访问,并且计数器+1
-
当次数大于限流阀值,就拒绝访问。
-
当前的时间窗口过去之后,计数器清零。
假设单位时间是1秒,限流阀值为3。在单位时间1秒内,每来一个请求,计数器就加1,如果计数器累加的次数超过限流阀值3,后续的请求全部拒绝。等到1s结束后,计数器清0,重新开始计数。如下图:

/**
* 固定窗口时间算法
* @return
*/
boolean fixedWindowsTryAcquire() {
long currentTime = System.currentTimeMillis(); //获取系统当前时间
if (currentTime - lastRequestTime > windowUnit) { //检查是否在时间窗口内
counter = 0; // 计数器清0
lastRequestTime = currentTime; //开启新的时间窗口
}
if (counter < threshold) { // 小于阀值
counter++; //计数器加1
return true;
}
return false;
}但是,这种算法有一个很明显的临界问题:假设限流阀值为5个请求,单位时间窗口是1s,如果我们在单位时间内的前0.8-1s和1-1.2s,分别并发5个请求。虽然都没有超过阀值,但是如果算0.8-1.2s,则并发数高达10,已经超过单位时间1s不超过5阀值的定义啦。
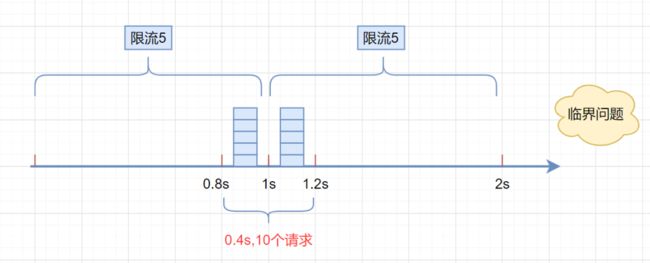
滑动窗口限流算法
滑动窗口限流解决固定窗口临界值的问题。它将单位时间周期分为n个小周期,分别记录每个小周期内接口的访问次数,并且根据时间滑动删除过期的小周期。
一张图解释滑动窗口算法,如下:
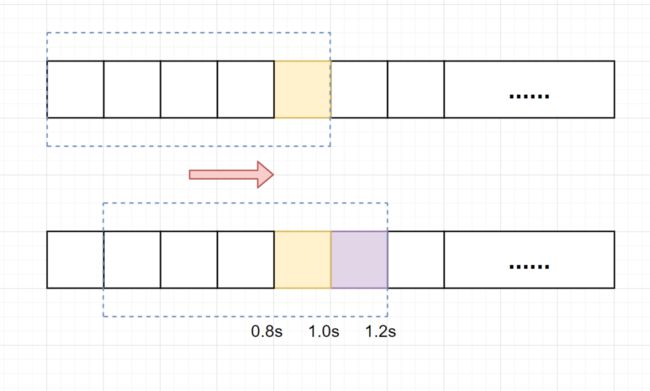
假设单位时间还是1s,滑动窗口算法把它划分为5个小周期,也就是滑动窗口(单位时间)被划分为5个小格子。每格表示0.2s。每过0.2s,时间窗口就会往右滑动一格。然后呢,每个小周期,都有自己独立的计数器,如果请求是0.83s到达的,0.8~1.0s对应的计数器就会加1。
我们来看下滑动窗口是如何解决临界问题的?
假设我们1s内的限流阀值还是5个请求,0.8~1.0s内(比如0.9s的时候)来了5个请求,落在黄色格子里。时间过了1.0s这个点之后,又来5个请求,落在紫色格子里。如果是固定窗口算法,是不会被限流的,但是滑动窗口的话,每过一个小周期,它会右移一个小格。过了1.0s这个点后,会右移一小格,当前的单位时间段是0.2~1.2s,这个区域的请求已经超过限定的5了,已触发限流啦,实际上,紫色格子的请求都被拒绝啦。
TIPS: 当滑动窗口的格子周期划分的越多,那么滑动窗口的滚动就越平滑,限流的统计就会越精确。
滑动窗口算法伪代码实现如下:
/**
* 单位时间划分的小周期(单位时间是1分钟,10s一个小格子窗口,一共6个格子)
*/
private int SUB_CYCLE = 10;
/**
* 每分钟限流请求数
*/
private int thresholdPerMin = 100;
/**
* 计数器, k-为当前窗口的开始时间值秒,value为当前窗口的计数
*/
private final TreeMap counters = new TreeMap<>();
/**
* 滑动窗口时间算法实现
*/
boolean slidingWindowsTryAcquire() {
long currentWindowTime = LocalDateTime.now().toEpochSecond(ZoneOffset.UTC) / SUB_CYCLE * SUB_CYCLE; //获取当前时间在哪个小周期窗口
int currentWindowNum = countCurrentWindow(currentWindowTime); //当前窗口总请求数
//超过阀值限流
if (currentWindowNum >= thresholdPerMin) {
return false;
}
//计数器+1
counters.get(currentWindowTime)++;
return true;
}
/**
* 统计当前窗口的请求数
*/
private int countCurrentWindow(long currentWindowTime) {
//计算窗口开始位置
long startTime = currentWindowTime - SUB_CYCLE* (60s/SUB_CYCLE-1);
int count = 0;
//遍历存储的计数器
Iterator> iterator = counters.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry entry = iterator.next();
// 删除无效过期的子窗口计数器
if (entry.getKey() < startTime) {
iterator.remove();
} else {
//累加当前窗口的所有计数器之和
count =count + entry.getValue();
}
}
return count;
} 滑动窗口算法虽然解决了固定窗口的临界问题,但是一旦到达限流后,请求都会直接暴力被拒绝。酱紫我们会损失一部分请求,这其实对于产品来说,并不太友好。
漏桶算法
漏桶算法面对限流,就更加的柔性,不存在直接的粗暴拒绝。
它的原理很简单,可以认为就是注水漏水的过程。往漏桶中以任意速率流入水,以固定的速率流出水。当水超过桶的容量时,会被溢出,也就是被丢弃。因为桶容量是不变的,保证了整体的速率。

-
流入的水滴,可以看作是访问系统的请求,这个流入速率是不确定的。
-
桶的容量一般表示系统所能处理的请求数。
-
如果桶的容量满了,就达到限流的阀值,就会丢弃水滴(拒绝请求)
-
流出的水滴,是恒定过滤的,对应服务按照固定的速率处理请求。
漏桶算法伪代码实现如下:
/**
* 每秒处理数(出水率)
*/
private long rate;
/**
* 当前剩余水量
*/
private long currentWater;
/**
* 最后刷新时间
*/
private long refreshTime;
/**
* 桶容量
*/
private long capacity;
/**
* 漏桶算法
* @return
*/
boolean leakybucketLimitTryAcquire() {
long currentTime = System.currentTimeMillis(); //获取系统当前时间
long outWater = (currentTime - refreshTime) / 1000 * rate; //流出的水量 =(当前时间-上次刷新时间)* 出水率
long currentWater = Math.max(0, currentWater - outWater); // 当前水量 = 之前的桶内水量-流出的水量
refreshTime = currentTime; // 刷新时间
// 当前剩余水量还是小于桶的容量,则请求放行
if (currentWater < capacity) {
currentWater++;
return true;
}
// 当前剩余水量大于等于桶的容量,限流
return false;
}在正常流量的时候,系统按照固定的速率处理请求,是我们想要的。但是面对突发流量的时候,漏桶算法还是循规蹈矩地处理请求,这就不是我们想看到的啦。流量变突发时,我们肯定希望系统尽量快点处理请求,提升用户体验嘛。
令牌桶算法
面对突发流量的时候,我们可以使用令牌桶算法限流。
令牌桶算法原理:
-
有一个令牌管理员,根据限流大小,定速往令牌桶里放令牌。
-
如果令牌数量满了,超过令牌桶容量的限制,那就丢弃。
-
系统在接受到一个用户请求时,都会先去令牌桶要一个令牌。如果拿到令牌,那么就处理这个请求的业务逻辑;
-
如果拿不到令牌,就直接拒绝这个请求。
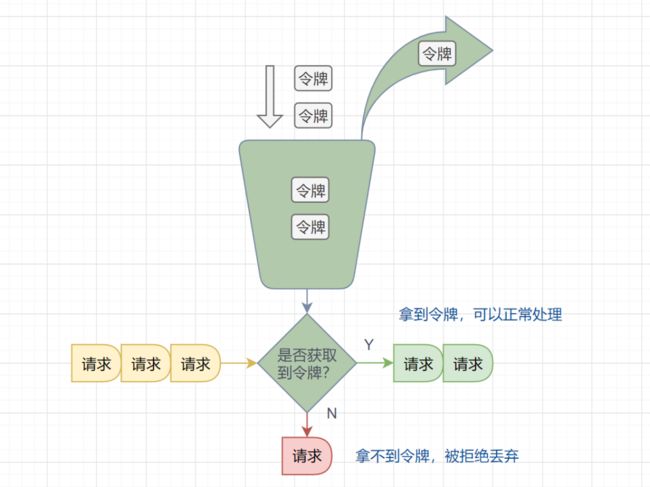
漏桶算法伪代码实现如下:
/**
* 每秒处理数(放入令牌数量)
*/
private long putTokenRate;
/**
* 最后刷新时间
*/
private long refreshTime;
/**
* 令牌桶容量
*/
private long capacity;
/**
* 当前桶内令牌数
*/
private long currentToken = 0L;
/**
* 漏桶算法
* @return
*/
boolean tokenBucketTryAcquire() {
long currentTime = System.currentTimeMillis(); //获取系统当前时间
long generateToken = (currentTime - refreshTime) / 1000 * putTokenRate; //生成的令牌 =(当前时间-上次刷新时间)* 放入令牌的速率
currentToken = Math.min(capacity, generateToken + currentToken); // 当前令牌数量 = 之前的桶内令牌数量+放入的令牌数量
refreshTime = currentTime; // 刷新时间
//桶里面还有令牌,请求正常处理
if (currentToken > 0) {
currentToken--; //令牌数量-1
return true;
}
return false;
}如果令牌发放的策略正确,这个系统即不会被拖垮,也能提高机器的利用率。Guava的RateLimiter限流组件,就是基于令牌桶算法实现的。
12. 异步
回忆一下什么是同步,什么是异步呢?以方法调用为例,它代表调用方要阻塞等待被调用方法中的逻辑执行完成。这种方式下,当被调用方法响应时间较长时,会造成调用方长久的阻塞,在高并发下会造成整体系统性能下降甚至发生雪崩。异步调用恰恰相反,调用方不需要等待方法逻辑执行完成就可以返回执行其他的逻辑,在被调用方法执行完毕后再通过回调、事件通知等方式将结果反馈给调用方。
因此,设计一个高并发的系统,需要在恰当的场景使用异步。如何使用异步呢?后端可以借用消息队列实现。比如在海量秒杀请求过来时,先放到消息队列中,快速响应用户,告诉用户请求正在处理中,这样就可以释放资源来处理更多的请求。秒杀请求处理完后,通知用户秒杀抢购成功或者失败。
13. 接口的常规优化
设计一个高并发的系统,需要设计接口的性能足够好,这样系统在相同时间,就可以处理更多的请求。当说到这里的话,可以跟面试官说说接口优化的一些方案了。大家可以看下我的这篇文章哈:实战总结!18种接口优化方案的总结
14. 压力测试确定系统瓶颈
设计高并发系统,离不开最重要的一环,就是压力测试。就是在系统上线前,需要对系统进行压力测试,测清楚你的系统支撑的最大并发是多少,确定系统的瓶颈点,让自己心里有底,最好预防措施。
压测完要分析整个调用链路,性能可能出现问题是网络层(如带宽)、Nginx层、服务层、还是数据路缓存等中间件等等。
loadrunner是一款不错的压力测试工具,jmeter则是接口性能测试工具,都可以来做下压测。
15. 应对突发流量峰值:扩容+切流量
如果是突发的流量高峰,除了降级、限流保证系统不跨,我们可以采用这两种方案,保证系统尽可能服务用户请求:
-
扩容:比如增加从库、提升配置的方式,提升系统/组件的流量承载能力。比如增加
MySQL、Redis从库来处理查询请求。 -
切流量:服务多机房部署,如果高并发流量来了,把流量从一个机房切换到另一个机房。
参考与感谢